Economía y Empresa
Plan de acción para el desastre
Plan de Acción para el Desastre
¿Porqué Recuperación de Desastres?
En la actualidad y a pesar de la creciente confianza existente en la computación y en las telecomunicaciones en casi todos los aspectos de los negocios, muchas corporaciones continúan estando mal preparadas en cuanto a la recuperación en la pérdida de activos de sus aparatos de computación y telecomunicación se refiere. Al estar mal preparados están corriendo riesgo, esperando que el desastre no les toque a ellos.
Pero estos riesgos aumentan en contra de ellos cada día.
¿ Qué puede causar un desastre?
En el actual medio de la computación, existe una gran lista de cosas que pueden causar un desastre en el negocio. A parte de los desastres naturales, ¿ Qué podría causar un desastre en la computadora ? Cientos de cosas, por ejemplo, una falla en la energía eléctrica, fuego, problemas de agua, explosión, sabotaje, vandalismo o problemas del medio ambiente, tan solo por mencionar algunas. Aún si su equipo sobrevie, ¿ Qué sucede si su personal no puede llegar hasta él ? Las huelgas laborales, las huelgas de transporte o inclusive una fuerte nevada que deje su equipo inalcanzable, pueden ocasionar un desastre en su negocio.
A pesar de las continuas mejoras que se hacen en los equipos de las computadoras, las fallas en el hardware y software siguen siendo las tres cuartas partes de todas las interrupciones en los negocios, pérdida de información o corrupción. Estas fallas incluyen deterioro del disco, problemas con los cables e interrupciones en el sistema operativo.
Los Números son Alarmantes....
Y, si usted nunca se ha tomado el tiempo para pensar en cuál es el costo real de un desastre de negocio, y la mayoría de la gente no se lo ha hecho, encontrará que las cifras son alarmantes. Pero dejemos los números a un lado por un momento para considerar algunas de las consecuencias potenciales.
Y Aún hay Más....
Accionistas.- Los accionistas se han vuelto más agresivos en cuanto al seguimiento dado para obtener más altos reembolsos por su inversión. Para algunos, esto significaría presionar a la junta directiva para quitar al gerente del puesto ejecutivo de la compañía. Al dar seguimiento a un desastre el cual tiene un severo impacto en el valor accionario, se buscaría a las partes responsables.
Demanda.- Existe la amenaza de una demanda. ¿ A caso, cuando usted eligió ignorar la planeación formal para la recuperación del desastre, llenó su responsabilidad fiduciaria para proteger los activos innvolucrados ?
Existen otras consecuencias muy serias en los desastres. Los negocios dependen de los sistemas computacionales para optimizar las operaciones, desde la planta hasta el centro de servicio al cliente y pasando por las oficinas administrativas. Considere tan solo algunas de la amplia gama de funciones que recaen en las computadoras: nómina, ingresos, ordenes de entrada, facturación, cuentas por cobrar, cuentas por pagar, inventario y control de producción.
Cuando se presenta una interrupción en el servicio de los equipos en forma repentina se paralizan simultáneamente un sinnúmero de funciones. De hecho, los estudios demuestran que cerca del 90% de las compañías reportan que al presentarse una falla en el sistema experimentan pérdida en la productividad, esto sin mencionar la insatisfacción que experimentan tanto el usuario el equipo como el cliente y finalmente el daño que se produce.
Hay una infinidad de razones por las cuales los negocios no están preparados adecuadamente ante un desastre en su centro de datos. El Plan de Acción para el Desastre de SunGard es una lectura muy útil para cada ejecutivo I.S. ya sea que cuente o no con un plan de recuperación.
¿Cómo está cambiando el mundo de la Información Tecnológica?
Los negocios hoy en día están pasando un torbellino de cambios. Reduciéndose, volviéndose a alinear, adaptándose a las nuevas presiones competitivas, expandiéndose hacia nuevos mercados. Todos estos cambios se reflejan en el Centro Procesador de Datos y otros recursos fundamentales de información dentro de la compañía.
El número de ambientes de computación dentro de cierta organización está aumentando. Generalmente, la información se ha vuelto más organizada, y más y más funciones críticas se vienen encontrando afuera del la tradicional "casa de cristal". Muchas aplicaciones han sido bajadas de la unidad principal y subidas a un sistema de medio rango (o mediano). Las redes locales están estallando con un crecimiento veloz, incrementando la dependencia en grupos de trabajo. Ahora, las organizaciones tienen múltiples requerimientos de plataformas. Al mismo tiempo, hay un movimiento que barre hacia el uso del tiempo como un arma competitiva. Las actitudes de los consumidores piden respuestas inmediatas. Las presiones reguladoras están aumentando, especialmente en las áreas de servicios financieros. Los negocios hoy en día están buscando un servicio personalizado rápido, y soluciones a la medida de los retos en la recuperación del negocio.
¿Cómo está cambiando la recuperación de desastres?
La Recuperación de Desastres (RD) está cambiando en un sin número de maneras. Como especialistas en la protección de compañías de los efectos de la interrupción del negocios, firmas como SunGard tienen un papel único. El punto fundamental aquí es el cambio - la adaptación a nuevas tecnologías y a nuevas formas de trabajo.
La Recuperación de Desastres debe mantenerse al día con los rápidos cambios impulsando a las compañías americanas. Las clases de cambios que afectan los recursos de información de las compañías. RD, como cualquier otro servicio a la industria que desea sobrevivir dentro del año 2000, está siendo muy flexible. Ya no hay más "soluciones de cajón". Los proveedores de RD deben ofrecer a los suscriptores la máxima flexibilidad, y personalización al grado "n". Esto quiere decir que la lista de servicios de RD ha crecido - desde un servicio exclusivo a las unidades principales hace una década a servicios como: recuperación de medio rango o (medianos), recuperación LAN, soluciones transportables, centros de datos móviles y grupos de trabajo de recuperación. La lista crecerá cada vez más con el tiempo.
¿Qué es lo que el futuro depara para la recuperación de desastres?
El futuro se ve bien pero no será fácil. Aunque más y más organizaciones están al tanto de la necesidad de la recuperación de desastres, muchas aun no saben dónde empezar. Añada a esto cambios constantes que están destruyendo a la mayoría de los negocios en los Estados Unidos y el panorama se torna un poco inquietante. El verdadero reto para los expertos en la recuperación de desastres como SunGard es estar por lo menos un paso adelante que nuestros suscriptores. Necesitamos estar en contacto con las necesidades cambiantes de los negocios, y al mismo tiempo mantenernos atentos de las tecnologías emergentes que puedan impactar los servicios que ofrecemos y las formas en las que se ofrecen al cliente. No va a ser fácil; en SunGard no podemos permitirnos no andar bien.
¿Cómo es que cambiarse a un ambiente ordenado de cómputo afecta a la recuperación de desastres?
Así como la información se vuelve más dispersa dentro de la organización, el control sobre ella también se vuelve decentralizada. Por ejemplo, ¿es el jefe de MIS responsable de que los empleados no lleven a cabo un respaldo de las PCs en red en cada localidad de la compañía? ¿Qué sucede después que una PC se respalda? ¿Deja usted el disco de respaldo encima del monitor? ¿Quién toma responsabilidad para llevar este disco fuera del lugar? ¿A dónde debe de entregarse? Puede apreciar usted que hay muchas preguntas. Las respuestas varían dependiendo de la organización y de las necesidades de la RD. Generalmente, se necesita un mayor y más complejo proceso de planeación de recuperación para una mayor informática distribuida. Organizaciones como la subsidiaria de SunGard, SunGard Planning Solutions se especializa en construir planes a la medida para acomodar los retos únicos de la informática distribuida.
¿Qué es lo que los negocios esperan de los proveedores de la recuperación de desastres?
Ellos están esperando lo mismo que sus propios clientes esperan de ellos. Mayor flexibilidad, precios competitivos, tiempos de respuestas más veloces, y más servicios -- servicios que ofrecen soluciones específicas a problemas específicos. Nuestros suscriptores nos buscan para eliminar la complejidad de la planeación y del proceso de recuperación. Ellos quieren soluciones que son transparentes para sus propios clientes.
Todo en una sola compra es una de las más nuevas expectativas del consumidor. (Introducción a La Alianza). Una solución de recuperación traída directamente a las puertas de su casa es otro ejemplo. (Introducción a la Recuperación Móvil).
¿Qué le está sucediendo a la "Ventana de Recuperación"?
Hay una presión creciente en los negocios, desde consumidores y reguladores gubernamentales, hasta cerrar el cuadro de tiempo de recuperación o "ventana de recuperación". Al mismo tiempo, las bases de datos se están expandiendo tan rápidamente como las necesidades IS de los negocios continúan creciendo. Esto representa un reto único para los vendedores de la recuperación de desastres, un reto que muchos en la industria no han sido capaces de enfrentar. El enfoque de 7 X 24 X 365 de SunGard a la recuperación de desastres significa que los suscriptores pueden cerrar la ventana de recuperación más eficientemente. Las soluciones de recuperación de el cierre electrónico y la llave en mano, son dos ejemplos de la clase de soluciones que son requeridas por más y más de nuestros suscriptores. Los negocios que hace cinco años podían permitirse estar sin operar por varios días ahora quieren estar listos y trabajando en horas.
¿Qué tan rápido la mayoría de los negocios necesitan estar de nuevo trabajando?
Basado en estudios realizados por la Universidad de Minnesota, la Universidad de Texas y el Grupo Gartner, podemos hacer algunas afirmaciones acerca de la duración de un apagón y sus efectos en los negocios. La mayoría de los negocios pueden sobrevivir 1 o 2 apagones pero después de eso las consecuencias empiezan a desarrollarse en: deterioro del servicio a clientes, y baja la liquidez. Si las funciones primarias del negocio son interrumpidas por 3 a 7 días otros impactos negativos se sienten: posible publicidad negativa de la compañía; clientes perdidos; obligaciones legales causadas por tiempos de entrega fallidos; serio peligro financiero. Más allá de una semana, el impacto es enorme: recrear la información, si fuese posible, viene a ser muy costoso; la pérdida permanente de información lleva a incrementar los litigios; y después de apagones largos por lo general el personal se encuentra exhausto y hay mucha rotación de los mismos.
El Plan de Acción para el Desastre trata acerca de la protección del empleo, datos y equipo cuando un desastre con cualquier descripción llega y afecta al negocio. Para ayudarlo a prepararse, le ofrecemos esta guía autorizada en la reanudación del negocio - asunto importante aunque en ocasiones nos alarme pensar en ello. Un enlace vital en la cadena de la supervivencia del negocio cuando la emergencia llega&un incendio, inundación, un terremoto. O algo menos catastrófico, pero no menos dañino un virus, error humano, fallas en la red que afectan sus datos&.la sangre vital de los negocios de hoy en día.
Sólo SunGard, los expertos en recuperación de desastres, pueden buscar, escribir, publicar y ofrecer - sin cargo alguno, gratis - este trabajo objetivo de la recuperación de desastres. Decimos objetivo, porque deseamos que usted conserve esta guía aunque no sea nuestro cliente, aun cuando escoja un método alternativo de recuperación o ningún método. Porque ya sea que maneje una unidad principal central grande o mediana o un ambiente de sistema abierto, o si está planeando ubicarse en una plataforma diferente, necesitará de un programa de recuperación de datos. Y nosotros simplemente queremos que tome una decisión bien fundada en lo que es mejor para su negocio.
CONTROLES PARA RECUPERACION EN CASO DE DESASTRES.
Con el propósito de crear o aumentar la capacidad de recuperación en caso de desastres es necesario concebir procedimientos de recuperación y respaldo para todo el entorno (edificio) y para hardware, software, datos y redes de comunicación. El plan debe contemplar varios niveles de respuesta ante diferentes posibles desastres y debe permitir la recuperación parcial o total en las áreas de:
-
El edificio
-
Software del sistema y las instalaciones
-
Programas de aplicación
-
Hardware del centro de datos
-
Microcomputadoras o terminales remotas
-
Formas manuales
-
Apoyo para la entrada de datos
-
Almacenamiento y retención de archivos de bases de datos en el sitio mismo y en lugares remotos
-
Procedimientos del sistema operativo en el centro de datos y en áreas de usuarios remotos
-
Asignación de personal y responsabilidades para casos de desastre
-
Actualización y mantenimiento adecuados del plan para desastres
-
Todas las redes de comunicación (troncales arrendadas, redes de área local, de micro y macro, de marcación pública, etcétera).
Los controles de recuperación y respaldo dentro de la red de comunicación abarcan muchas áreas por lo que usualmente se realiza un plan por separado para cada una de las áreas siguientes:
-
El centro de control de la red de comunicación
-
Los circuitos de comunicación
-
Controladores remotos de conmutadores, concentradores, terminales inteligentes
-
Instalaciones de la empresa de comunicaciones (compañía telefónica)
-
Energía eléctrica para las instalaciones de la concentración de datos y las terminales de los usuarios.
El plan para desastres en una red de comunicación de datos debe considerar los siguientes detalles:
-
El administrador tomará decisiones y estará a cargo de la operación de recuperación del desastre. En caso de que el primer administrador no esté disponible se nombrará un segundo administrador.
-
Capacitación y disponibilidad de personal de apoyo con suficiente conocimiento y experiencia en la comunicación de datos.
-
Procedimientos de recuperación para las instalaciones de la comunicación de datos. Esto es información sobre la ubicación de los circuitos de a quien debe localizarse para apoyar los circuitos de datos y la documentación y prioridades preestablecidas acerca de cuales circuitos de datos deben reconstruirse en primer lugar.
-
Como sustituir el hardware y el software dañados de comunicación de datos que son proporcionados por los proveedores. Es necesario delinear el apoyo que puede esperarse de parte de los proveedores, junto con el nombre y numero telefónico de la persona que debe contactarse.
-
Localización de instalaciones alternativas de comunicación de datos y de equipo como cables de conexión, líneas de abonado locales, CIC, medios de conmutación de la empresa de comunicaciones y otras redes públicas.
-
Acciones por emprender en caso de un daño parcial, amenazas como bombas, incendios, daño eléctrico por agua, sabotajes, movimientos sociales, fallas de los proveedores.
-
Procedimientos para imponer controles extraordinarios sobre la red hasta que el sistema regrese a la normalidad.
-
Almacenamiento de los procedimientos de recuperación en caso de desastres en un lugar seguro en el que no sea posible que sean destruidos por la catástrofe. Sin embargo, esta área debe ser accesible a quien necesite utilizar los planes.
MATRIZ DE CONTROLES.
Si se desea tener la certeza de que la red de comunicación de datos y las estaciones de trabajo de las microcomputadoras cuentan con todos los controles necesarios y que estos controles ofrecen protección adecuada, es recomendable construir una matriz bidimensional en la que se incorporen todos los controles que se encuentren presentes en ese momento de la red.
La matriz se construye identificando primero todas las amenazas que enfrenta la red y después los componentes de la red.
-
AMENAZA a cualquier evento adverso potencial que pueda dañar la red, interrumpir los sistemas que se encuentran utilizando la red o provocar pérdidas económicas a la organización.
-
COMPONENTE a una de las partes individuales que, cuando se ensamblan juntas, integran la red de comunicaciones de datos. Un componente puede considerarse un bien que se encuentra sometido a revisión o un bien sobre el que se está intentando mantener control así como componentes son hardware, software, circuitos y otras piezas de la red.
| Amenazas generales a una red de comunicación de datos
|
| Componentes Generales de una red de comunicación de datos
|
Para la identificación y la documentación de los controles de una red es necesario identificar las amenazas y componentes específicos que se relacionen con cualquier red que esté utilizando la organización, posteriormente se pueden relacionar tales amenazas y componentes con los controles individuales que se encuentran en el lugar.
El paso siguiente será realizar una breve descripción de cada amenaza en la parte superior de la matriz.
De igual manera, en el eje vertical izquierdo de la matriz se escribe una breve descripción de cada componente.
Una vez que se han etiquetado los ejes horizontales y vertical, el paso siguiente es identificar todos los controles específicos que se están utilizando actualmente en la red de comunicación de datos. Estos controles in situ deben describirse y colocarse en una lista numerada. Por ejemplo, supóngase que se han identificado 24 controles que estaban utilizándose en la red. Se describe cada uno, además de numerarlos consecutivamente del 1 al 24, la lista de controles numerados no tiene asociada clasificación alguna: el primer control es el número 1 sencillamente porque es el primer control identificado.
| Lista de control Garantizar que el sistema puede conmutar los mensajes destinados a una estación/terminal hacia una estación/terminal alterna. |
Determinar si el sistema puede realizar conmutación de mensajes entre estaciones/terminales. |
Para evitar perdida de mensajes en un sistema de conmutación de mensajes, se debe contar con la capacidad de almacenamiento y envío. Esto consiste en que un mensaje con destino a una estación ocupada se almacena en el conmutador central y de ahí se envía tiempo más tarde, cuando la estación ya no esta ocupada. |
Revisar las capacidades de registro de mensajes o transacciones para reducir las pérdidas de mensajes, constituir un rastreo de intervención, restringir los mensajes, prohibir los mensajes ilegales, y funciones parecidas. Los mensajes pueden registrarse en la estación remota (terminal inteligente), en un concentrador remoto/procesador de entrada remoto, o en el procesador de comunicación de entrada central/computadora central. |
Transmitir rápido los mensajes para reducir el riesgo de pérdida. |
Identificar cada mensaje mediante la contraseña (password) del usuario individual, la terminal y el número de secuencia del mensaje individual. |
Reconocer la recepción exitosa o no exitosa de todos los mensajes. |
Considerar los siguientes controles especiales en los módems con marcación cuando la red de conmutación de datos permita el ingreso de conexiones con marcación: cambiar los números telefónicos a intervalos regulares, mantener confidenciales los números telefónicos, retirar los números telefónicos de los módems que se hallan en el área de operación de computación, requerir que cada "terminal con marcación" tenga un microcircuito de identificación electrónica del circuito para transmitir su identificación única al procesador de comunicación de entrada, no permitir la recepción y conexiones automáticas de llamadas (siempre se debe tener a una persona para interceptar la llamada y hacer la identificación verbal), hacer que el sitio central llame a las diversas terminales con autorización de conexión al sistema, utilizar la marcación hacia fuera sólo cuando con una llamada entrante con marcación se active de manera automática la marcación de una llamada al solicitante (de esta manera el sistema central controla los números telefónicos a los cuales se permite la conexión). |
Luego, cada uno de los controles identificados se coloca en el cuadro apropiado de la matriz. Esto se logra leyendo la descripción de cada control en la lista de control y luego planteando las dos preguntas siguientes:
¿Cuál o cuáles amenazas mitigará o detendrá este control?
¿Cuál o cuáles componentes salvará o preservará este control?
Por ejemplo, si la descripción del control 1 es "asegurar que el sistema pueda conmutar mensajes de una estación/terminal caída hacia una estación terminal alternativa", entonces se debe escribir el número 1 en la primera entrada (cuadro) en el ángulo superior izquierdo.
Se asignó esta posición porque un control que asegura que el sistema puede conmutar mensajes cuando una estación se ha caído ayuda a controlar errores y también es un control que salvaguarda la computadora principal o el procesador de entrada (o ambos) reside en ellos. En la siguiente figura [Matriz en Blanco] se muestra el control 1 en el cuadro en el que se intersectan Pérdida o cambio de mensaje y Computadora principal. El control 1 también aparece en varios cuadros. La cuestión es que al responder las dos preguntas anteriores sea posible colocar cada control en los cuadros idóneos de la matriz.
La matriz terminada con los controles [Segunda Matriz] muestra la relación que tiene cada control con respecto a la amenaza que se supone que dicho control mitiga y el componente al que salvaguarda o controla.
El último paso en el diseño de una matriz de controles para una red de comunicación de datos específica es evaluar la idoneidad de los controles [Ultima Matriz]. Esto se logra revisando cada subconjunto de controles según se relaciona con cada área de amenaza y de componente de la matriz. Por ejemplo, se evalúa el subconjunto de controles que constituye una columna debajo de la amenaza. El objetivo de este paso es responder la pregunta específica "¿se tienen los controles específicos y son adecuados con respecto a cada amenaza específica?" Usando la figura [matriz]se observa que la columna que se encuentra identificada por Errores y omisiones. La matriz define claramente el subconjunto específico de controles que se relacionan con el área de la amenaza Errores y omisiones (números).
Este tipo de revisión también puede efectuarse para otros diferentes subconjuntos de controles. Por ejemplo, es posible evaluar subconjuntos individuales de controles según se relacionen con amenazas (columnas), componentes (renglones), cuadros individuales y cuadros vacíos. Al observar la figura, se tiene un diagrama gráfico que describe las cuatro áreas que deben ser revisadas. El método matricial constituye una herramienta perfecta para efectuar un microanálisis de los controles en una red de comunicación de datos. La matriz muestra claramente la relación entre diferentes subconjuntos de controles y áreas de amenazas específicas, componentes, cuadros individuales y cuadros vacíos.
Todo el procedimiento para diseñar y elaborar una matriz de controles ha sido automatizado para su uso en microcomputadora. Existen a disposición tres paquetes:
-
El paquete 1 enseña cómo diseñar y elaborar una matriz de controles.
-
El paquete 2 enseña cómo clasificar en cuanto a riesgo de la matriz para observar regiones de riesgo alto, medio y bajo.
-
El paquete 3 permite el trazo en línea de una matriz, la búsqueda interactivas en la base de datos de controles relacionados con cualquier cuadro (inteligencia artificial básica) y la impresión de una matriz con su lista de controles de matriz asociada.
Para ayudar a construir una matriz de controles relacionada con la red de comunicación de datos de su organización existen listas específicas de controles para redes de comunicación de datos, las cuales cada una incluye la definición del área correspondiente seguida por su propio conjunto de controles. Las áreas que se abordan son:
-
Controles de software
-
Desastres e interrupciones
-
Modems
-
Multiplexor, concentrador, conmutador
-
Circuitos (líneas) de comunicación
-
Manejo de errores
-
Líneas de abonado locales
-
Entrada y validación de datos
-
Errores y omisiones
-
Rearranque y recuperación
-
Pérdida o cambio de mensajes
-
Controles del personal
-
Procesador de comunicación de entrada
-
Confiabilidad/actualización
MATRIZ EN BLANCO CON ENCABEZADOS EN LOS BORDES
AMENAZAS
| Errores Y omisiones | Pérdida o cambio de mensajes | Desastres y siniestros | Pérdida de privacía | Extravío, robo | Confiabilidad (tiempo de funcionamiento) | Recuperación y rearranque | Manejo de errores | Verificación y validación de datos | |
| Computadora principal o sistema central | |||||||||
| Software | |||||||||
| Procesador de comunicación de entrada | |||||||||
| Multiplexor, concentrador, conmutador | |||||||||
| Circuitos de comunicación | |||||||||
| Líneas de abonado | |||||||||
| Modems | |||||||||
| Personal | |||||||||
| Terminales/ Inteligencia distribuida |
MATRIZ DE CONTROLES
AMENAZAS
| Errores Y omisiones | Pérdida o cambio de mensajes | Desastres y siniestros | Pérdida de privacía | Extravío, robo | Confiabilidad (tiempo de funcionamiento) | Recuperación y rearranque | Manejo de errores | Verificación y validación de datos | |
| Computadora principal o sistema central | 1,2,3,4,7 | 1,2,3,4,7 | 1,8,11,13,16 | 6,8, 24 | 6,8, 24 | 6,8, 24 | 1,13,16 | 6, 24 | |
| Software | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 16 | 6, 8, 24 | 6,8, 24 | 1 | 6, 24 | ||
| Procesador de comunicación de entrada | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 13, 16 | 6, 8, 24 | 6,8, 24 | 1, 13, 16 | 6, 24 | ||
| Multiplexor, concentrador, conmutador | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 13, 16 | 6,8, 24 | 1, 13, 16 | 6, 24 | |||
| Circuitos de comunicación | 12 | 10, 15, 16, 18 | 15, 16 | ||||||
| Líneas de abonado | 12 | ||||||||
| Modems | 12,18 | 18, 24 | 8, 9, 10, 11,13,14, 15,16,18 | 24 | 24 | 9,10,11, 13,14,15,16,17,18 | 9,10,11,14,15 | 18,19,20, 22,23 | |
| Personal | 5 | 5, 7 | 6, 8, 24 | 6, 8, 24 | 6 | ||||
| Terminales/ Inteligencia distribuida | 2 | 6, 8, 24 | 6, 8, 24 | 1 | 6, 24 |
EVALUACION DE LA MATRIZ DE CONTROL
AMENAZAS
| Errores Y omisiones | Pérdida o cambio de mensajes | Desastres y sinietros | Pérdida de privacía | Extravío, robo | Confiabilidad (tiempo de funcionamiento) | Recuperación y rearranque | Manejo de errores | Verificación y validación de datos | |
| Computadora principal o sistema central | 1,2,3,4,7 | 1,2,3,4,7 | 1,8,11,13,16 | 6,8, 24 | 6,8, 24 | 6,8, 24 | 1,13,16 | 6, 24 | |
| Software | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 16 | 6, 8, 24 | 6,8, 24 | 1 | 6, 24 | ||
| Procesador de comunicación de entrada | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 13, 16 | 6, 8, 24 | 6,8, 24 | 1, 13, 16 | 6, 24 | ||
| Multiplexor, concentrador, conmutador | 1,2,3,4,7 | 1,2,3,4,7 | 1, 8, 13, 16 | 6,8, 24 | 1, 13, 16 | 6, 24 | |||
| Circuitos de comunicación | 12 | 10, 15, 16, 18 | 15, 16 | ||||||
| Líneas de abonado | 12 | ||||||||
| Modems | 12,18 | 18, 24 | 8, 9, 10, 11,13,14, 15,16,18 | 24 | 24 | 9,10,11, 13,14,15,16,17,18 | 9,10,11,14,15 | 18,19,20, 22,23 | |
| Personal | 5 | 5, 7 | 6, 8, 24 | 6, 8, 24 | 6 | ||||
| Terminales/ Inteligencia distribuida | 2 | 6, 8, 24 | 6, 8, 24 | 1 | 6, 24 |
ANEXO
A continuación se presentan como ejemplo las medidas que toma en cuenta el protocolo Frame Relay para la recuperación de errores:
LA ESTRATEGIA DE DESCARTE
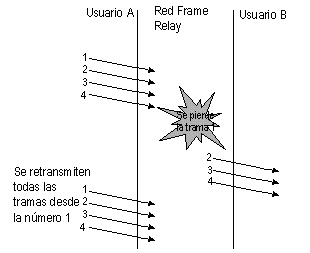
Uno de los principios básicos del protocolo de frame relay es: si hay un problema con una trama, se ignora y se descarta. Si ocurren muchos problemas, un número significativo de tramas serán descartadas y el sistema de destino final tendrá que encargarse de recuperar la situación. Esta recuperación normalmente consiste en una retransmisión de las tramas perdidas. Todos los sistemas inteligentes tendrán un método de numeración secuencial de los datos enviados y recibidos, y los datos perdidos requerirán un cierto nivel de resincronización. Esta numeración es una característica de los protocolos de nivel superior conectados y no del frame relay en sí. Una trama descartada puede causar la retransmisión de más de una trama para poder resincronizar. Por ejemplo supongamos, tal y como se muestra en la Ilustración 1, que se envían 4 tramas desde el usuario A hasta el B. La red descarta la trama número 1, y el usuario B recibe las tramas 2, 3 y 4. Algunos protocolos serán capaces de solicitar de nuevo la trama 1 solamente, sin embargo, muchos otros requerirán la completa resincronización de todo el flujo de datos y, consecuentemente, solicitarán de retransmisión de todas las tramas.
Desafortunadamente, las retransmisiones incurren en una demanda adicional de ancho de banda en la red. Las consecuencias de esto es que un error en una parte de la red provoca que otras tramas lleguen incorrectas (y por tanto sean retransmitidas) lo que probablemente causará problemas de congestión.
El usuario espera que el número de errores a lo largo de la red sea pequeño, ya que se supone que frame relay se usa sobre líneas de muy alta calidad (normalmente fibra óptica), pero ¿es esto cierto?. Los cables de fibra óptica instalados a lo largo del mundo representan menos del 1% de las líneas disponibles y normalmente se encuentra entre las mayores centrales. Así, los datos de frame relay raramente se estropearán cuando pasen entre grandes centrales, pero ¿qué pasa en el recorrido local? Todo esto revela que el enlace débil en la red frame relay es la conexión usuario-red.
CONTROL DE LA CONGESTIÓN
El otro problema principal de las redes frame relay está provocado por una de sus mayores cualidades - la capacidad de un dispositivo de mandar datos a la red cuando él quiera, sin tener que recurrir a mecanismos de control de flujo. Esta cualidad puede provocar el efecto de incrementar el rendimiento de una única aplicación a través de la red, ya que esta aplicación es capaz de utilizar todo el ancho de banda de la red para su propio uso. Sin embargo, ¿qué pasa cuando más de una aplicación pasa una ráfaga de datos a la red simultáneamente? Sin un diseño cuidadoso, la red pronto se verá congestionada. La estrategia del CIR sólo es una guía a seguir por los dispositivos de acceso, todavía es posible que un dispositivo envie datos a más velocidad que su CIR. El mecanismo de elegibilidad de descarte proporciona en estos casos que las tramas que se envíen por encima del CIR se marquen como "elegibles para ser descartadas si hay congestión". Pero, por supuesto, una trama descartada aparece en el otro extremo de la red como una trama pérdida que hay que reenviar, luego esta retransmisión de tramas perdidas provoca un tráfico adicional en la red.
El efecto que se produce es que la red pasa a un estado de congestión.
Los mecanismos de congestión son de vital importancia en el frame relay. El problema fundamental que aparece en el tratamiento de la congestión con frame relay es que no hay un mecanismo que permita a la red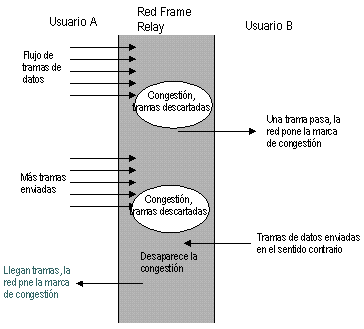
reducir el tráfico a través de ella. La notificación de un estado de congestión en la red se realiza activando un bit situado en la cabecera Frame Relay. Esto implica que sólo los dispositivos que están recibiendo tramas son los que tienen conocimiento de dicha situación de congestión. De todas formas, normalmente, el usuario que recibe las tramas no es el que está causando los problemas de congestión. Además, este mensaje de notificación de congestión no es una orden del protocolo para cesar de enviar datos, luego un dispositivo puede ignorarla y seguir enviando datos (el problema de la congestión se verá en detalle en el capítulo dedicado a la misma).
Este método de tratar la congestión puede llevar a verdaderos problemas dentro de la red. Una vez que ocurre la congestión, la única manera de frenar el problema es descartar tramas. Estas tramas descartadas serán solicitadas por el otro extremo para ser reenviadas, lo que provoca una mayor demanda de ancho de banda y provoca una mayor congestión. Más aún, un dispositivo puede ignorar esta notificación de congestión y continuar enviando datos. Así pues la congestión aumentará rápidamente.
BIBLIOGRAFIA
Comunicación de Datos en los Negocios
Conceptos Básicos, Seguridad y Diseño
Jerry Fitz Gerald
Megabyte
15
Descargar
| Enviado por: | Genmota Cotarelo |
| Idioma: | castellano |
| País: | México |
Todos los derechos reservados.