Informática
Sistemas de bases de datos
Motivación
Existen 2 fuerzas que han impulsado la evolución de los sistemas de bases de datos. Los usuarios como parte de organizaciones más complejas que se han ido incorporando en los sistemas de bases de datos. Un ejemplo de esto es la integrar información proveniente de fuentes diversas. Por otro lado, la tecnología ha hecho posible que algunas facilidades inicialmente imaginarias solo en sueños se conviertan en realidad. Por ejemplo, las transacciones en línea que permite al sistema bancario no hubieran sido posibles sin el desarrollo de los equipos de comunicación.
La presión por datos distribuidos.
La prisión de los usuarios.
Las bases de datos grandes permiten organizar la info. Revelantes a alguna parte de la operación de una organización como por ejemplo, servicios de salud, bancos, etc. Casi cualquiera organización que usa un sistema de info. Para su funcionalidad ha experimentado 2 fases.
Fuerzas evolucionarías en los sistemas de bases de datos
En la primera fase se ha agrupado toda la info. En un solo lugar. La idea original era que todos los accesos a datos podrían ser integrados en un solo lugar usando herramientas de bases de datos tales como lenguajes de descripción de datos, lenguajes de manipulación da datos mecanismos de acceso verificadores de restricciones y lenguajes de alto nivel. Para tener en estos mecanismos, las organizaciones hicieron grandes inversiones en equipos computacionales sofistica con grandes capacidades. Pero con el tiempo se dieron cuenta que el sistema ser satisfactorio pero no todos los usuario tuvieron un servicio óptimo, además los propietarios perdieron el control de la información almacenada.
Algunos experimentos mostraron que un 90% de las operaciones de entrada y salida info. .eran “locales” (correspondiente al departamento. que las generaba) y solo el 10% de tales operaciones involucraba información cruzadas) info. .proveniente de diferente departamento). Así en la segunda fase se promovió la descentralización de los sistemas de bases de datos. Entonces, empezaron a adquirir sorteares y hardware departamentales.
Sin embargo, muy pronto empezaron a aparecer inconvenientes con este enfoque. Se presentaron problemas de consistencia de la información entre los sistemas locales y central se hallaron problemas al transferir información de entre departamentos diferentes.
De esta manera en esta tercera fase s ha tratado de formalizar sus funciones manteniendo la integridad de la información.
La presión de la tecnología.
Existen buenas razones técnicas para distribuir datos. Las mas obvia es la referente a la sobre carga de los canales de entrada y salida a los discos donde se almacena finalmente la información. Es mucho mejor distribuir los accesos a la información sobre diferentes canales que concentrarlos en uno solo. Otra razón de peso es que las redes de computadoras empezaron a trabajar a velocidades razonables.
Al hacer una descentralización de la información se justifica desde el punto de vista tecnológico por las siguientes razones:
-
Para ofrecer buenos rendimientos.
-
Para proveer una arquitectura de sistema simple, flexible y tolerable a fallas.
-
Para permitir autonomía local.
Existen aplicaciones que nacieron distribuidas. Para ellas ha sido necesario el uso de nuevas tecnologías para integrar sistemas de información diferentes.
Aunque la idea de distribución de datos es bastante atractiva, su realización lleva a la superación de una serie de dificultades tecnológicas entre las que se puedan mencionar:
-
Asegurar que el acceso entre diferentes sitios o nodos y el procesamiento de datos se realice de manera eficiente, o sea óptima.
-
Distribuir datos en los nodos del ambiente distribuido de una manera optima
-
Controlar el acceso a los datos disponibles en el ambiente distribuido.
Computación distribuida.
Los sistemas de bases de dato distribuidas son un caso particular de los sistemas de cómputo distribuidos en los cuales un conjunto de elementos (no necesariamente homogéneos) se interconectan por una red de comunicaciones y cooperan entre ellos para realizar sus tareas asignadas.
Entre los términos mas comunes que se utilizan para referirse al computo distribuido podemos encontrar: funciones distribuidas, procesamiento distribuido de datos, multiprocesadores, multicomputadoras, procesamiento satelital, procesamiento tipo “backend”, computadoras dedicadas y de propósito especifico, sistema de tiempo compartido.
Existen muchos componentes para realizar una tarea. En computación distribuida los elementos que se pueden distribuir son:
-
Control. Las actividades relacionadas con el manejo o administración del sistema.
-
Datos. La información que maneja el sistema.
-
Funciones. Las actividades que cada elemento del sistema realiza.
-
Procesamiento lógico. Las tareas específicas involucradas en una actividad de procesamientos de información.
Motivación de los sistemas de bases de datos distribuidos.
Sistemas de bases de dato distribuidas.
Una base de datos distribuidos (BDD): es un conjunto de múltiples bases de datos lógicamente relacionadas las cuales se encuentran distribuidas entre diferentes sitios interconectados por una red de comunicaciones.
Un sistema de bases de datos distribuidas (SBDD): es un sistema en el cual múltiples sitios de bases de datos están ligados por un sistema de comunicaciones, de tal forma que, un usuario en cualquier sitio pueda acceder los datos en cualquier parte de la red exactamente como silos datos en cualquier parte de la red exactamente como si los datos estuvieran almacenados en su sitio propio.
Un sistema de manejo de bases de datos distribuidas (SMBDD): es aquel que se encarga del manejo de BDD u y proporciona un mecanismote acceso que hace que la distribución sea transparente a los usuarios. El término transparente significa que la aplicación, trabajaría desde un punto de vista lógico, como si un solo SMBD ejecutado en una sola computadora, administrara esos datos.
Un sistema de bases de datos distribuida (SBDD) es entones el resultado de la integración de una base de dato distribuidas con un sistema para su manejo.
Dado las definiciones anteriores no se puede considerar todos los sistemas como (SBDD).por ejemplo un sistema de tiempo compartido no incluye necesariamente un sistema de manejo de bases de datos, y si fuese así una sola computadora lo administraría.
Un sistema centralizado sobre una red.
Un medio ambiente distribuido para bases de datos.
Ambientes con muchos procesadores.
Desde el punto de vista de las bases de datos, conceptualmente existen 3 tipos de ambientes con múltiples procesadores:
1.- Arquitecturas de memoria compartida. constan de varios procesadores los cuales accedan a una misma memoria y una misma unidad de almacenamiento (1 o mas discos).algunos ejemplos de este tipo de computadoras Sequent Encore y los mainframes IBM4090 y BULL DPS8.
Arquitectura de memoria compartida.
2.- Arquitecturas de disco compartido. Consiste de diversos procesadores cada uno de ellos con su memoria local pero compartiendo una misma unidad de almacenamiento (1 o varios discos).ejemplos de estas arquitecturas son los CLUSTER de Digital, y los modelos IMS/VS Data Sharing de IBM.
Arquitectura de un disco compartido.
1.- Arquitecturas nada compartido. Consiste en diversos procesadores cada uno con su propia memoria y su propia unidad de almacenamiento. Aquí se tienen los cluster de estaciones de trabajo, las computadoras Intel Paragon, NCR 3600 y 3700 e IBM SP2.
Arquitectura nada compartido.
Aplicaciones
Los ambientes donde se encuentra con mayor frecuencia el uso de bases de datos distribuidas son:
-
cualquier organización que tiene una estructura descentralizada.
-
Casos típicos de lo anterior son: organismos gubernamentales y/o de servicio publico.
-
La industria de la manufactura, particularmente, aquella con plantas múltiples. Por ejemplo la industria automotriz.
-
Líneas de transportación aéreas
-
Cadenas hoteleras
-
Servicios bancarios y financieros
Ventajas
Los SMBDD tienen múltiples ventajas. En primer lugar los datos son localizados en lugar mas cercano, por lo mismo el acceso es mas rápido debido a que varios nodos intervienen en le procesamiento de una carga de trabajo. La comunicación de los nodos se mejora, bajan los costos de producción, son amigables a los usuarios, cada nodo es independiente y al fallar uno es poca la probabilidad de que afecte a los demás.
Las razones de que las empresas se cambian a las bases de datos distribuidas es por razones económicas y organizacionales, las bases de datos distribuidas se adaptan a las estructuras de las organizaciones. Además la necesidad de desarrollar una aplicación global (que incluya a toda la organización), se resuelva fácilmente con bases de datos distribuidas. Si una organización crece por medio de creación de departamentos, el enfoque de la base datos distribuidas permite un crecimiento suave.
Los datos se pueden colocar en un lugar con más concurrencia, haciendo que los usuarios tengas control local con los datos.
Las bases de datos distribuidas pueden presentar cierto grado de tolerancia a fallas haciendo que el funcionamiento del sistema no dependa de un solo lugar como en le caso de las bases de datos centralizadas.
Desventajas.
La principal desventaja se refiere al control y al manejo de datos. Dado que estos están ubicados en muchos nodos diferentes y se pueden consultar por nodos diversos de la red, la probabilidad de violaciones de seguridad es creciente si no se toman las precauciones debidas.
Dado que los datos pueden estar replicados, el control de concurrencia y los mecanismos de recuperación son muchos mas complejos que en un sistema centralizado.
Aspectos importantes de los SMBD distribuidos.
Existen varios factores relacionados a la construcción de bases de datos distribuidas que no se presentan en bases de datos centralizadas.
Entre los más importantes se encuentran:
1.- Diseño de la base de dato distribuida. El diseño de base de datos distribuidos se debe considerar el problema de cómo distribuir la información entre diferentes sitios. Cuando se busca eficiencia en el acceso a al información se deben ver dos problemas.
Primero, como fragmentar la información. Segundo, como asignar cada fragmentación entre los diferentes sitios de la red. En el diseño de la BDD también
es importante considerar si la información esta repetidas, es decir, si existen copias múltiples de los mismos datos como mantener la resistencia de la información. Finalmente, una parte importantes el deseo de una BDD se refiere al manejo del directorio. Si existen únicamente usuarios globales, se debiera manejar un solo directorio global. Sin embargo, si existen también usuarios locales, el directorio mezcla información local con información global.
2. Procesamiento de consultas. El procesamiento es súper importante en bases de datos centralizadas. En cambio las BDD adquieren mayor importancia. El objetivo es convertir transacciones de usuarios en instrucciones para manipulación de datos. El orden de la forma que se hacen las transacciones afecta grandemente la velocidad de respuesta de sistema. Este problema de optimización es NP-difícil, por lo que solo se pueden soluciones aproximadas. En BDD se tiene que considerar l procesamiento local de una consulta junto con el costo de transmisión de información al lugar en donde se solicito la consulta.
3. Control de concurrencia. El control de concurrencia es la actividad de coordinar accesos a las bases de datos .el control de concurrencia permite a los usuario acceder al sistema de bases de datos en una forma multiprogramada. El control de concurrencia se preocupa de que muchos usuarios hagan transacciones y que además no se transfieran para que hayan errores. En BDD el control d concurrencia es aun más complejo que en sistemas centralizados. Los algoritmos más utilizados son variaciones de aquellos usados en sistemas centralizados: candados de dos fases, ordenamiento por estampas de tiempo, ordenamiento por estampas de tiempo múltiples y control de concurrencia optimista. Un aspecto interesante del control de concurrencia es el manejo de ínterbloqueos. El sistema no debe permitir que 2 o mas transacciones se bloqueen entre ellas.
4. Confiabilidad. En cualquier sistema de bases de datos, centralizado o distribuido, se debe ofrecer garantías de que la información es confiable. Así cada consulta o actualización de la información se hace mediante transacciones, las cuales tiene un inicio y un fin. En sistemas distribuidos el manejo de la durabilidad de las transacciones es aun más complejo, ya que una sola transacción puede involucrar 2 o más sitios de la red. Entonces el control de recuperación en sistemas distribuidos debe asegurar que el conjunto de agentes que participan en una transacción realicen todo un compromiso (commit)) de que toso al mismo tiempo restablezcan la información anterior (roll-back).
Se presenta un diagrama con las relaciones entre los aspectos relevantes sobre las BDD.
Factores importantes en BDD.
Estado del arte.
Aun cuando los beneficios del uso de BDD son claramente visibles, en la actualidad se encuentran únicamente en sistema experimentales (de investigación). A continuación discute el estado actual de las bases de datos comerciales respecto a 4 logros potenciales accesible en BDD.
1.- Manejo transparente de bases de datos distribuidos, fragmentados y replicados. Comercialmente todavía no se soporta la replicación de información. La fragmentación utilizada es únicamente de tipo horizontal. la distribución de información no se realiza aun con la transparencia requerida. por ejemplo, el usuario debe indicar donde esta el objeto y el acceso a los datos es mediante sesiones remotas a bases de datos locales. La mayoría de los sistemas comerciales utilizan el modelo múltiples clientes-un solo servidor.
2.- Mejoramiento de la confiabilidad y disponibilidad de la información mediante transacciones distribuidas. Algunos sistemas como Ingres, NonStop SQL y Oracle V7.x ofrecen el soporte de transacciones distribuidas. En Sybase, por ejemplo, es posible tener transacciones distribuidas. Respecto del soporte para replicación de información o no se ofrece o se hace a través de la regla une-lee-todos-escriben.
3.- Mejoramiento de la eficiencia. Una mayor eficiencia es una de las grandes promesas de los SMBDD. Exciten varia partes donde esto se puede lograr: primero, la ubicación de los datos a lugares próximos a dónde se usan puede mejorar la eficiencia en el acceso a la información. Pero para lograrlo hay que tener un buen soporte de fragmentación y replicación de información. Otro método para aumentar el rendimiento es explotar el paralelismo entre operaciones. en el caso de varias consultas a la vez, estas se pueden procesar por sitios diferentes.
Incluso, el procesamiento de una sola consulta puede involucrar varios sitios y así procesarse de manera mas rapad. Sin embargo, la explotación del paralelismo requiere que se tenga tanta información requerida como para cada aplicación en el sitio donde la aplicación se realiza, la cual llevaría a una replicación completa, esto es, tener toda la información en cada red. El manejo de replicas es complicado ya que las actualizaciones a este tipo de datos involucran a todo los sitios teniendo copias del dato .por ejemplo en los bancos se da el horario de oficina para hacer lecturas y la horas no hábiles para hacer actualizaciones .otra forma de estrategia es la de tener 2 bases de datos, una para consulta y otra para actualizaciones.
4.- Mejor escalabilidad de las BD. El tener sistemas escalables de manera fácil y económica se ha logrado por el desarrollo de la tecnología de microprocesadores y estaciones de trabajo. A respecto de la escalabilidad, la comunicación de la información tiene un costo el cual no se ha estudiado con suficiente profundidad.
CARACTERISTICAS DE LAS BDD CON RESPECTO A CENTRALIZADAS
CONTROLCENTRALIZADO: Las BD fueron desarrolladas como evolución de un sistema de información, la función principal de un DBA es garantizar la salud de los archivos.
En una BD se puede ver la estructura de control jerárquica basada en una DBAGLOBAL que es responsable de la BD en su totalidad y DBALOCALES responsable de su BD local respectiva. La coordinación ADM local se denomina autonomía local.
ESTRUCTURA FISICA COMPLEJAS Y ACCESO EFICIENTE
Estructuras de accesos complejos, como los índices secundarios, son un aspecto importante en las BD tradicionales. El soporte a esas estructuras es una de las funciones de los SGBD. La razón es obtener un acceso eficiente a los datos.
En BDD, las estructuras de accesos no son la herramienta adecuada para un acceso eficiente. Un eficiente acceso en las BDD no puede ser proporcionado por medio de estructuras físicas locales porque es muy difícil construir y mantener tales estructuras.
En BDD se habla de 2 necesidades:
Optimización Global: Es el encargado de determinar el dato haciende y donde debe ser transmitido.
Optimización Local: Decide como realizar los accesos a las BD en cada lugar, los problemas de optimización local son típicos de BD tradicionales.
¿Por qué BDD?
1.- Razones económicas y organizativas: Muchas organizaciones están descentralizadas, y una aproximación de BDD se acopla más naturalmente a la estructura de la organización. Con los recientes desarrollos en tecnología, la motivación de economías de escala de tener grandes ordenadores centrales está siendo cuestionada.
2.- Interconexión de BD existentes: Las BDD son la solución natural cuando varias BD ya existen en la organización y aparece la necesidad de realizar aplicaciones globales. En este caso, las BDD son creadas de abajo-arriba desde las BD preexistentes. El proceso puede requerir un cierto grado de reestructuración; sin embargo, el esfuerzo que es requerido por esta reestructuración es mucho menor que el necesario para la creación de una nueva BD centralizada.
3.- Crecimiento incremental: Si una organización crece añadiendo nuevas unidades organizativas autónomas (nuevas sucursales, nuevos almacenes, etc.) entonces la aproximación de BDD soporta un crecimiento incremental con un mínimo grado de impacto en las unidades ya existentes. Con una aproximación centralizada, o las dimensiones iniciales del sistema tienen en cuenta la futura expansión, lo cual es difícil de prever y caro de implementar, o el crecimiento tiene un impacto mayor no solamente en las nuevas aplicaciones sino también en las existentes.
4.- Reducida sobrecarga de comunicación: En una BD distribuida geográficamente, el hecho de que muchas aplicaciones sean locales claramente reduce la sobrecarga de comunicación con respecto a las BD centralizadas.
5.- Consideraciones de rendimiento: La existencia de varios procesadores autónomos resulta en un incremento del rendimiento debido a un alto grado de paralelismo. Estas consideraciones pueden ser aplicadas a un sistema de multiprocesadores, y no solamente a las BDD. Los cuellos de botella que se producen para la utilización de ciertos recursos se minimizan.
6.- Fiabilidad y disponibilidad: La aproximación distribuida, especialmente con datos redundantes, puede ser usada para obtener un alto grado de veracidad y disponibilidad. La capacidad de procesamiento autónomo de los diferentes centros no garantiza por sí mismo un nivel más alto de exactitud en el sistema, pero el efecto de fallos en las aplicaciones es menor; un fallo del sistema completo es infrecuente.
DESVENTAJAS DE UN SBDBB.
1.- Falta de experiencia: Los SGBDD no son muy usados, pero hay prototipos para líneas aéreas que son quienes las usan.
2.- Complejidad: Los problemas de un SGBDD son mayores que los de los gestores Centralizados.
3.- Coste: El componente de coste mas importante es la mano de obra, ya que para está distribuida se necesita mucha mano de obra para mantenerla.
4.- Distribución de control: es desventaja solo por crear problemas de sincronización y coordinación, en este caso se adopta una política adecuada para que no sea desventaja.
5.- Seguridad: Las BD centralizadas proporcionan un elevado grado de control de acceso a los datos. En un entorno distribuido está una red implicada, que es un medio que tiene sus propios requerimientos de seguridad. Hay muchos problemas de seguridad en redes.
6.- Dificultad de cambio de las BD centralizadas en BDD: No existen herramientas ni metodologías que ayuden a los usuarios a convertir sus BD en BDD.
ESTRUCTURA FISICA COMPLEJAS Y ACCESO EFICIENTE.
Es la independencia del programa de aplicación de la distribución de datos. Aquí veremos una arquitectura de referencia para una BD distribuida.
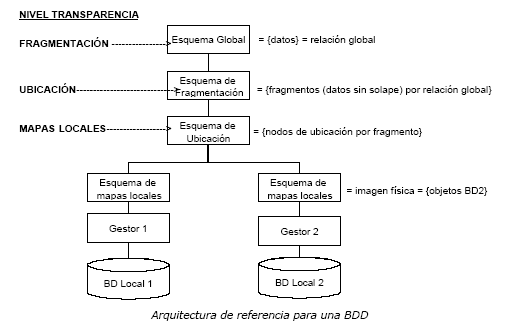
1.- Esquema Global: Define todos los datos que están contenidos en la BDD como si la BD no fuese distribuida. Por esta razón se puede decir que esquema global y BD no distribuida son similares
2.- Fragmentos: cada relación global puede ser dividida en porciones que no se solapen llamados fragmentos. El mapa resultante se denomina esquema de fragmentación. Una relación global puede dividirse en n fragmentos y un fragmento sólo puede pertenecer a una relación global. Los fragmentos se referencian por un nombre de relación global y un subíndice. Por ejemplo Ri indica el fragmento i de la relación R.
Los fragmentos son porciones lógicas de relaciones globales que pueden estar físicamente ubicadas en uno o varios nodos de la red. El esquema de ubicación define en qué nodos un fragmento va a ser almacenado. El tipo de mapa definido en el esquema de ubicación determina si la BDD es redundante o no. Todos los fragmentos que corresponden a la misma relación global R y están ubicados en el mismo nodo constituyen la imagen física de una relación global R en el nodo. Las imágenes físicas se pueden referenciar por el nombre de la relación global R y un superíndice; por ejemplo, Rj indica la imagen física de la relación global R en el nodo j.
Por último se denomina copia de fragmento a la información de un fragmento en un nodo determinado en un nodo dado, y se denota usando el nombre de la relación global, un subíndice y un superíndice. Por ejemplo, R3 2 indica copia del fragmento R2 que está ubicado en el nodo 3. Dos imágenes físicas pueden ser idénticas; se dice entonces que una imagen física es copia de otra imagen física.
En un nivel más bajo, es necesario construir un mapa que relacione las imágenes físicas con los objetos que son manipulados por los gestores locales. Este mapa se llama esquema de mapas locales y depende del tipo de gestor local; por lo tanto, en un sistema heterogéneo tenemos diferentes tipos de mapas locales en los diferentes nodos.
Esta arquitectura proporciona un marco conceptual de comprensión de las BDDs. Los tres objetivos más importantes de esta arquitectura son:
Separar el concepto de fragmentación de datos del de ubicación de datos: Esta separación permite distinguir dos niveles diferentes de transparencia de la distribución llamados transparencia de fragmentación y transparencia de ubicación.
La transparencia de fragmentación es el grado más alto de transparencia y quiere decir que el usuario o programador de aplicaciones trabaja sobre relaciones globales. La transparencia de ubicación es un grado inferior de transparencia y requiere que el usuario o programador de aplicaciones trabaje con fragmentos en lugar de relaciones globales; sin embargo, no es necesario saber donde se localizan los fragmentos. La separación entre el concepto de fragmentación y ubicación es muy conveniente en diseño de BDD.
Control explícito de redundancia: Una arquitectura de referencia proporciona un control de redundancia explícito al nivel de fragmento. La definición de fragmentos disjuntos nos permite referirnos a fragmentos replicados.
Independencia de gestores locales: Esta característica, denominada transparencia de mapas locales, permite estudiar varios problemas de gestión de BDDs sin tener que tener en cuenta los modelos de datos de los gestores locales. Claramente, en un sistema homogéneo es posible definir los modelos de datos para los mismos gestores, reduciendo la complejidad de los mapas.
Otro tipo de transparencia relacionada con la transparencia local es la transparencia de reproducción. Significa que el usuario no se da cuenta de la reproducción de los fragmentos. Es posible, en ciertos casos, que el usuario no tenga transparencia de ubicación pero tenga transparencia de reproducción (de esta manera, cuando alguien hace uso de una copia particular, el sistema local toma las acciones oportunas sobre las restantes copias). Es decir, puede que el usuario conozca los fragmentos y dónde se ubican sus diferentes copias, pero que no se encargue de actualizar dichas copias si se realiza alguna modificación. Se
pueden usar sin distinción una de la otra.
Tipos de fragmentación de datos.
Hay dos tipos de fragmentación: fragmentación horizontal y fragmentación vertical. En todos los tipos de fragmentación, un fragmento puede ser definido por una expresión en un lenguaje relacional que sobre unos operadores (que son las relaciones globales) producen un resultado. Por ejemplo, si una relación global contiene datos sobre los empleados, un fragmento podría ser aquel que contiene solamente datos sobre los empleados que trabajan en el departamento D1.
Hay algunas reglas que deben ser seguidas:
Condición de completitud: Todos los datos de una relación global deben de estar contenidos en los fragmentos, es decir, no puede suceder que un ítem de datos de una relación global no pertenezca a ningún fragmento.
Condición de reconstrucción: Debe ser siempre posible reconstruir una relación global desde sus fragmentos. Ello es obvio, porque solamente los fragmentos son almacenados en la BDD.
Condición de fragmentos disjuntos: Es conveniente que los fragmentos sean disjuntos, por lo que la reproducción de datos puede ser controlada explícitamente en el nivel de ubicación. Esta condición es útil, especialmente con fragmentación horizontal.
Fragmentación horizontal
La fragmentación horizontal consiste en particionar las tuplas de una relación global en subconjuntos; esto es claramente útil en BDDs, donde cada subconjunto contiene datos que tienen propiedades lógicas y, en general, geográficas comunes.
Se define cada fragmento con una operación de selección sobre la relación global.
Ejemplo: Supongamos la siguiente relación global:
PROV (nupro, nopro, nolocpro)
la fragmentación horizontal puede ser definida de la siguiente forma:
PROV1 = σnolocpro = “Madrid” (PROV)
PROV2 = σnolocpro = “Barcelona” (PROV)
Comprobación de las reglas:
Completitud: la fragmentación satisface esta condición si Madrid y Barcelona son los únicos valores posibles del atributo nolocpro; de otra forma no podríamos conocer a qué fragmento pertenecen las tuplas con otros valores en nolocpro.
Reconstrucción: esta condición se verifica fácilmente, ya que siempre es posible
reconstruir la relación global PROV con la operación UNION:
PROV = PROV1 ð PROV2
Fragmentos disjuntos: El predicado que es usado en la operación de selección que define un fragmento se llama predicado de cualificación. Así, para el ejemplo anterior los predicados de
cualificación son:
q1: nolocpro = “Madrid”
q2: nolocpro = “Barcelona”
Fragmentación horizontal derivada
En algunos casos, la fragmentación no puede basarse en una propiedad de sus propios atributos, sino que se deriva de la fragmentación horizontal de otra relación.
Ejemplo: consideremos la relación:
PEDIDO (nuped, nupro, nupieza, nudep, qped)
Si quisiéramos dividir esta realción para que cada fragmento tenga las tuplas de los proveedores que son de una ciudad dada, como el atributo localidad pertenece a la relación PROV, se necesita una operación de semi-join para determinar qué tuplas de PEDIDO corresponden a proveedores de una localidad determinada. La fragmentación derivada de PROV puede definirse así:
PEDIDO1 = PEDIDO µnupro = nupro PROV1
PEDIDO2 = PEDIDO µnupro = nupro PROV2
El efecto de la operación de semi-join es seleccionar de PEDIDO las tuplas que satisfacen la condición de join entre PROV1 ó PROV2 y PEDIDO.
Cuando una relación global R tiene una fragmentación derivada, las cualificaciones de sus fragmentos no pueden ser expresadas como predicados que utilizan atributos de R. La condición para una tupla t de pertenecer a un fragmento dado Ri de R es de existencia, en algún otro fragmento de Si de S, de una tupla t' tal que t y t' satisface la especificación de semi-join de la fragmentación derivada.
Considerando el ejemplo anterior, representamos esta condición de la siguiente manera:
q1: PEDIDO.nupro = PROV.nupro AND PROV.nulocpro = “Madrid”
q2: PEDIDO.nupro = PROV.nupro AND PROV.nulocpro = “Barcelona”
Comprobación de las reglas:
Completitud: la completitud requiere que no haya números de proveedores en PEDIDO que no estén contenidos en PROV. Esto se garantiza por la restricción de integridad referencial.
Reconstrucción: la reconstrucción de la relación global PEDIDO puede ser realizada por la operación de UNION.
PEDIDO = PEDIDO1 È PEDIDO2
Fragmentos disjuntos: esta condición se cumple si una tupla de la relación PEDIDO no se corresponde con dos tuplas de una relación de PROV que pertenezcan a dos fragmentos diferentes. En este caso, la condición es fácilmente verificada, porque el atributo nupro es clave en la relación PROV. En general no resulta tan fácil probar que se mantiene esta condición.
Fragmentación vertical
La fragmentación vertical de una relación global es la subdivisión de sus atributos en grupos; los fragmentos son obtenidos proyectando la relación global en cada grupo. Esto puede ser útil en BDDs cuando cada grupo de atributos pueden contener datos que tienen propiedades geográficas comunes y con tratamientos diferenciados.
Ejemplo: Consideremos la siguiente relación:
EMP (nuemp, noemp, isalemp, itasaemp, nudep)
Una fragmentación vertical de esta relación puede definirse como:
EMP1 = Õ nuemp, noemp, nudep (EMP)
EMP2 = Õ nuemp, isalemp, itasaemp (EMP)
Esta fragmentación podría, por ejemplo, reflejar una organización en la que los salarios y tasas son gestionados separadamente.
Comprobación de las reglas:
Reconstrucción: la reconstrucción de la relación global se realiza mediante un join de los fragmentos. La reconstrucción de la relación EMP puede ser obtenida de la siguiente forma:
EMP = Õ nuemp (EMP1 ¥nuemp=nuemp EMP2)
siendo nuemp clave de EMP.
En general, la inclusión de una clave de la relación global en cada fragmento es la mejor forma de garantizar que la reconstrucción a través de un join es posible. Un camino alternativo es generar identificadores de tuplas que son usados como claves. Ello puede ser conveniente para eliminar la reproducción de claves muy grandes. Los identificadores de tuplas no pueden ser modificados por los usuarios.
Fragmentos disjuntos: En general, en la fragmentación vertical no es tan importante mantener conjuntos disjuntos como en la fragmentación horizontal, De hecho, si se incluyen los mismos atributos en diferentes fragmentos verticales, sabemos exactamente que los datos reproducidos son los que se corresponden a dicho atributo. Así, si diseñamos los fragmentos verticales:
EMP1 = Õ nuemp, noemp, nudep (EMP)
EMP2 = Õ nuemp, noemp, isalemp, itasaemp (EMP)
El atributo noemp está reproducido en los dos fragmentos. Se puede explícitamente eliminar este atributos al reconstruir la relación global EMP, de la siguiente forma:
EMP = EMP1 ¥nuemp=nuemp (Õ isalemp, itasaemp (EMP2))
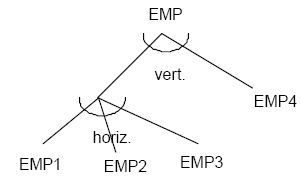
Fragmentación mixta
Los fragmentos que se obtienen en las operaciones de fragmentación anteriores son relaciones en sí mismas, por lo que es posible aplicar operaciones de fragmentación recursivamente, siempre y cuando se satisfagan las reglas. Sin embargo, no se deberían definir fragmentos intermedios innecesarios.
La reconstrucción se obtiene aplicando las reglas de reconstrucción en orden inverso.
Ejemplo: Consideremos la relación EMP anterior:
EMP (nuemp, noemp, isalemp, itasaemp, nudep)
Consideremos las fragmentaciones siguientes:
EMP1 = snudep < 10 (Õ nuemp, noemp, nudep (EMP))
EMP2 = s10<= nudep <= 20 (Õ nuemp, noemp, nudep (EMP))
EMP3 = snudep > 20 (Õ nuemp, noemp, nudep (EMP))
EMP4 = Õ nuemp, noemp, isalemp, itasaemp (EMP)
Es posible representar la fragmentación mediante un árbol de fragmentación, donde la raíz corresponde a la relación global, las hojas a los fragmentos y los nodos intermedios corresponden a los resultados intermedios de las expresiones que definen los fragmentos. El conjunto de nodos hijo de un nodo dado representan la descomposición de dicho nodo por una operación de fragmentación.
CONFIABILIDAD.
Un sistema de manejo de bases de datos confiable es aquel que puede continua procesando las solicitudes de usuario aún cuando el sistema sobre el que opera no es confiable.
DEFINICION.
La confiabilidad se puede interpretar de varias formas. La confiabilidad se puede ver como una medida con la cual un sistema conforma su comportamiento a alguna especificación. También se puede interpretar como la probabilidad de que un sistema no haya experimentado ninguna falla dentro de un periodo de tiempo dado. La confiabilidad se utiliza típicamente como un criterio para describir sistemas que no pueden ser reparados o donde la operación continua del sistema es crítica.
SISTEMA DE ESTADO O FALLA.
Es un mecanismo que tiene una colección de componentes y sus integraciones con el medio ambiente que responde a estímulos que provienen del mismo con un patrón de comportamiento reconocible. Cada componente de un sistema puede ser así mismo un sistema, llamado comúnmente subsistema.
Estado externo: Es la respuesta que un sistema proporciona a un estímulo externo, Por lo tanto, es posible hablar de un sistema que se mueve dentro de estados externos de acuerdo a un estímulo proveniente del medio ambiente.
Estado interno: Es la respuesta del sistema a un estímulo interno, es decir, desde el punto de vista de confiabilidad es la unión de todos los estado externos de las componentes que constituyen el sistema. Así, el cambio de estado interno se da como respuesta a los estímulos del medio ambiente
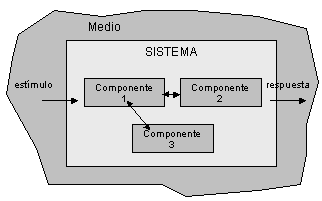
El comportamiento del sistema al responder a cualquier estimulo del medio, necesita establecerse por medio de especificaciones, la cual indica el comportamiento valido década estado del sistema. Su especificación es esencial para definir los siguientes conceptos de confiabilidad.
Cualquier sistema que se salga de su especificación se considera como falla. Cada falla debe ser rastreada hasta su causa. En un sistema confiable los cambios van de estados válidos a estados válidos. Sin embargo, en un sistema no confiable, es posible que el sistema caiga en un estado interno el cual no obedece a su especificación; a este tipo de estados se les conoce como estados erróneos.
Transiciones a partir de este estado pueden causar una falla, cuando el estado interno es incorrecto se le conoce como error de sistema, y los errores de estado interno se les llaman fallas del sistema. Así, una falta causa un error lo que puede inducir una falla del sistema.
Las fallas de sistema se clasifican en dos severas y no severa. Severas: casi siempre de tipo permanente y conducen a fallas severas del sistema. No severas: normalmente son transitorias o intermitente, por lo general son el 90% de todas las fallas.
![]()
A continuación daremos la definición formal de confiabilidad y disponibilidad.
Confiabilidad: La confiabilidad de un sistema R(t), se define como la siguiente probabilidad condicional: R(t) = PR{ 0 fallas en el tiempo [0,t] | no hubo fallas en t = 0 }
Aparte de estas hay otro tipos de fallas las cuales no mencionaremos.
TIPOS DE FALLAS EN SMBDD.
Diseñar un sistema confiable que se pueda recuperar de fallas requiere identificar los tipos de fallas con las cuales el sistema tiene que tratar. Así, los tipos de fallas que pueden ocurrir en un SMBD distribuido son:
1. Fallas de transacciones: Pueden ocurrir debido a errores de datos de entrada incorrectos como a la detección de un ínter bloqueo. La forma normal de solucionar esto es abortar.
2. Fallas del sistema: En sistema distribuido puede presentar fallas en el procesador, memoria principal o la fuete de energía de un nodo. En estas fallas se pierde el contenido de la memoria principal, pero el almacenamiento secundario es seguro. Si diferenciamos entre fallas parciales y fallas totales de nodo. Una falla total se presenta en todos los nodos del sistema distribuido. Una parciales presenta solo en algunos nodos del sistema.
3. Fallas del medio de almacenamiento: Son fallas que presentan los dispositivos de almacenamiento secundario que almacenan bases de datos. Estas se presentan por errores del sistema operativo, del controlador del disco, o del disco mismo.
4. Fallas de comunicación: Las fallas de comunicación en un sistema distribuido son frecuentes. Estas se pueden manifestar como pérdida de mensajes lo que lleva en un caso extremo a dividir la red en varias subredes separadas.
CONSIDERACIONES ESTRUCTURALES.
Se hace referencia al modelo de la arquitectura de un dbms. La arquitectura corresponde a la recuperación de errores de un sistema de almacenamiento construido por dos partes. La primera, llamada memoria principal, es un medio de almacenamiento volátil. La segunda, llamada de almacenamiento secundario ya que es permanente el cual en un principio no es infalible a fallas. Por medio de una combinación de hardware y software es posible tener un medio estable de almacenamiento, capaza de recurar fallas.
INFORMACION DE RECUPERACION.
Se asume que ocurren únicamente fallas de sistema. Cuando una falla del sistema ocurre el contenido volátil se pierde. Por lo tanto el dbms debe mantener información de su estado cuando falle con tal de ser capas de recuperar el estado antes de la falla. A esta se le llama información de recuperación.
La información de recuperación que el sistema mantiene depende del método con el que se realizan las actualizaciones. Existen dos estrategias para efectuarlas: en el lugar (in place) y fuera de lugar (out-of-place). En el primer caso, cada actualización se hace directamente en los valores almacenados en las páginas de los buffers de la base de datos. En la segunda alternativa, al crear un nuevo valor para un dato, éste se almacena en forma separada del valor anterior. De esta manera se mantiene los valores nuevo y anterior.
EJECUCION DE LOS COMANADOS DEL LRM
Existen cinto comandos que forman la interfaz lrm. Ellos son: begin_transaction, read, write, commit y abort. La ejecución de los comandos abort, commit y recover es completamente dependiente de los algoritmos de recuperación que se usen.
-Begin_transaction: hace que el lmr escriba un comando en el registro de la base de datos
-Read: El lrm trata de leer los datos especificados de las paginas de buffer que pertenecen ala transacción. Si los datos no se encuentran envía un comando fetch para que los datos sean disponibles.
-Write:este comando modifica el valor que se encuentra volátil en la base de datos.
PROTOCOLOS DISTRIBUIDOS.
La versión distribuida ayuda a mantener la autenticidad y durabilidad de las transacciones. Las ejecución de las operaciones commt, abort y recover requieren de un protocolo especial en el que participan todos los nodos de la red.
Si suponemos que en el nodo que se origina una transacción hay un proceso, llamado coordinador, que ejecuta las transacciones. Este se comunica con procesos participantes en los otros nodos los cuales ayudan en las operaciones de transacción.
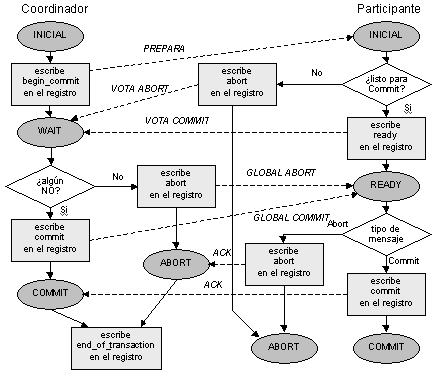
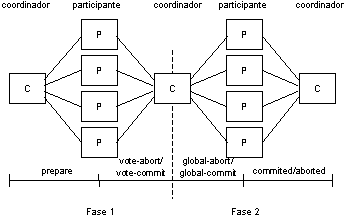
COMPROMISOS DE DOS FASES.
El compromiso de dos fases es muy simple y asegura la autenticidad de transacciones distribuidas, extiende los efectos de commit a transacciones distribuidas poniendo de acuerdo a todos los nodos que ejecutan una transacción antes de que los cambios de transacción sean permanentes.
Las fases del protocolo son las siguientes:
Fase 1: El coordinador hace que todos los participantes estén listos para escribir los resultados en la base de datos
Fase 2: Todos escriben los resultados en la base de datos.
Las terminaciones de una transacción se hace mediante la regla del compromiso global:
1.- El coordinador aborta una transacción si y solamente si al menos un participante vota por que se aborte.
2.- El coordinador hace un commit de la transacción si y solo si todos los participantes votan por que se haga el commit.
La operación de compromiso de dos fases entre coordinador y un participante de ausencia e falla se presenta en la Fig., en sonde los círculos indican el estado y las líneas encontradas indican mensajes entre coordinador y participante.
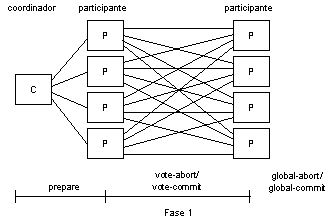
Otra alternativa es la comunicación lineal, donde los participantes se comunican con otros
Otra estructura de comunicación usual para implementar los compromisos de dos fases involucra la comunicación entre todos los participantes durante la primera fase del protocolo. Esta versión llamada estructura distribuida, no requiere segunda fase.
FALLAS DE NODOS
Aquí consideramos cuando un nodo falla en la red. El objetivo es desarrollar un protocolo no bloqueante que permita desarrollar protocolos de recuperación independientes. En una red hay muchas fallas de comunicación debido a colisiones, comunicación intermitente por interferencia, etc. La forma de saber que hay fallas de nodo es cuando no hay respuesta de este en un periodo de tiempo.
Sistemas de base de datos
Usuarios
Tecnología
Descargar
| Enviado por: | Carcar |
| Idioma: | castellano |
| País: | Chile |
Todos los derechos reservados.