Tecnología de la Información
Gestión de memoria principal
GESTIÓN DE MEMORIA PRINCIPAL
INTRODUCCIÓN
La Memoria Principal es un recurso muy importante que se ha de gestionar, porque se ha de disponer de velocidad.
Hay dos tipos de tiempos cuando hablamos de memoria:
-
Tiempo de acceso Tiempo de finalización de una petición menos el tiempo de inicio de la petición
-
Tiempo de ciclo de la memoria Desde que finaliza una petición hasta que se inicia la siguiente petición. Este se ve detenidamente por el Hardware.
DIRECCIONAMIENTO
Cuando escribimos un programa no indicamos el direccionamiento (donde guardamos el programa). Este se define solamente cuando comenzamos a escribir (donde pone la primera sentencia del programa). La primera línea de código marcará el momento de compilar la dirección de memora 0 relativa. De esta manera los programas son portables por diferentes sistemas y máquinas, separando la carga del programa en memoria de su ejecución
La primera sentencia sería la 0 relativo, seguidas de la 1 relativo,...
Cuando se coge la primera línea del programa para compilar y se pone la primera línea con 0 negativo. Y así el programa será + fácil para ejecutarse.
GESTION DE LA MEMORIA
-
MONOPROGRAMACIÓN
Con la llegada de la monoprogramación y de los sistemas operativos se hace necesario gestionar la memoria de manera que los programas que se querían cargar a la memora no pisen (borren,...) la memoria reservada al sistema operativo. Cuando se terminaba un proceso comienza el siguiente.
Programa en C Compilación Programa ejecutable
No hay nada que gestionar, solamente no preocupamos en coger el programa y ejecutarla.
| P |
Solamente nos tendríamos que preocupar cuando surgieron y esto se hacia mediante un registro frontera, que limitaba la memoria utilizable, para que no coja la memoria del SO.
| SO |
| P |
ERROR
Cuando yo hago un programa y al compilarlo se transforma en direcciones relativas.
¿Cómo se transforma la dirección relativa en absoluta?
Hay dos maneras de proceder:
-
Asignación de Memoria de forma Estática: no permiten que los procesos sean reutilizables, ya que en el momento que das la orden de ejecutar se carga el programa en memoria para su ejecución transforma todas las memorias relativas en absolutas.
-
Asignación de Memoria de forma Dinámica: cuando el programa se va ejecutando las direcciones relativas se pasan a absolutas tal como las líneas de código se ejecutan. (Instrucción por instrucción).
-
MULTIPROGRAMACIÓN
¿Cómo protegemos la memoria?
- Con asignación de direccionamiento (@x) de memoria estática: Antes mirábamos nada más límites inferiores y superiores de los registros fronteras. Pero con la Multiprogramación con más de un proceso ejecutándose a la vez necesitamos guardar los registros fronteras de cada proceso en su PCB, para poder organizar de manera eficiente su ejecución.
ERROR
Cuando hay varios procesos:
Lim. Inferior
| SO |
| P1 |
| P2 |
La dirección es absoluta.
- Con asignación de direccionamiento (@x) de memoria dinámica: El proceso tiene su rango de memoria definido (registro límite), la CPU habrá de asignar una dirección relativa menor a este rango y después sumar a esta dirección el registro base (donde comienza el proceso) para obtener la dirección absoluta.
ERROR
Dando una dirección que da el procesador serán las direcciones relativas se compara con el registro límite tiene que tener un límite (el tamaño del programa). Si es menor se le suma el Registro Base.
| En donde se guarda el proceso (donde comienza) | Tamaño del proceso | |
| SO | ||
| 1000 | P1 | 56K |
| 57... | P2 | 28K |
| 85... | P3 | 32K |
Compara que la dirección relativa sea menor.
| Donde empieza | MP | Cuanto ocupa |
| SO | ||
| 1000 | P1 | 5000 |
| 4999 | P2 | 28K |
| 85... | P3 | 32K |
Si es menor se le suma el registro base si no, no se podrá grabar.
Esta es más fácil de mantener, porque solamente guardas en trozos de memoria que lo da el programa.
De esta manera podemos independizar la compilación
Formas de gestionar la memoria por ubicar varios procesos den la memoria Principal.
-
Particiones continuas de tamaño fijo
Consiste en coger la MP y dividirla en trozos de tamaño fijos que quedan definidas en el momento que se carga el sistema operativo hasta que lo cambies hay que reiniciar el sistema para que sepa que lo has cambiado. No hace falta que sean del mismo tamaño. En cada partición se ubicará un proceso.
Se piensa en hacer colas de procesos relativas al tamaño de los procesos de la cola (p. ej. cola de procesos de 128K).
| P1 100K | 128K |
| 28K | |
| P2 70K | 128K |
| 58K | |
| 128K | |
| 256K |
Para eso hace falta que se creen colas para los procesos, para que entren en la partición:
128K
Pero este sistema hace que se malgaste memoria principal, pero de dos formas:
-
Fragmentación Interna: Malgasta memoria principal. El espacio que se pierde en la partición da que el programa no llega a aprovechar el espacio de la partición.
-
Fragmentación Externa: Se produce cuando hay suficiente espacio libre pero no podemos asignar memoria a un proceso en espera porque las particiones vacías son muy pequeñas y las adecuadas no están vacías (en las particiones que los puedes juntar y tendrías espacios suficientes para ubicar otros procesos, pero que sin juntar estos espacios, no puedes inserta).
| P1 100K | 128K |
| 28K | |
| P2 70K | 128K |
| 58K | |
| 128K | |
| P4 200K | 256K |
| 56K |
Hay varios tipos de colas: FIFO, Best-Fit,...
-
Particiones continuas de tamaño variable
La memoria se crea las particiones que necesita el proceso. Se crean según el tamaño de los procesos que se ubicarán. Para evitar la fragmentación exterior, en este caso se hará servir la compactación para recorrer los datos, pero esto tiene un elevado coste de T.
| P1 | 100K |
| P2 | 70K |
| P3 | 200K |
| P4 | 100K |
| 64K | |
Se está ejecutando el P1. Cuando se ejecuta un proceso está en memoria pero cuando termina de ejecutarse de la memoria.
| P2 | 70K |
| P3 | 200K |
| P4 | 100K |
| 64K | |
| 100K | |
Características:
-
compactación
-
RL registre limite + RB registro base + direcciones relativas @ rel + asignación dinámica procesos relativas
Los procesos han de ser reublicables porque hay esta compactación, hay que trabajar con asignación dinámica y no estática.
-
Paginación
Amb la paginació s'aconsegueix poder ubicar el procés en mem. tan
sols tenint espai suficient. S'agafa la mem.
Otra forma de gestionar la memoria posterior a las Particiones contiguas de tamaño variable.
Es una técnica que intenta disminuir los espacios vacíos.
Es 1 técnica q palia el inconveniente q había hasta ahora. Este inconveniente se encuentra en memoria un espacio grande para poder ubicar todo el proceso de forma contigua.
Permite ubicar un proceso en memoria teniendo espacio disponible, para estar separado.
Para poder llevar a cabo necesitamos una Tabla de Páginas. Aquí viene indexada, en donde está ubicada la primera posición(donde se guarda el inicio del flame).
| (Memoria Lógica) Procès A | Tabla de Paginación Proceso A | (Memoria Real) | ||||||
| P0 | 2K | @ F5 | F0 | (A) P3 | 2K | |||
| P1 | 2K | @ F3 | F1 | (B) P0 | 2K | |||
| P2 | 2K | @ F7 | F2 | (B) P1 | 2K | |||
| P3 | 2K | @ F0 | F3 | (A) P1 | 2K | |||
| Tabla de Pag Proceso B | F4 | |||||||
| Proceso B | F5 | (A) P0 | ||||||
| P0 | @ F1 | F6 | (B) P2 | |||||
| P1 | @ F2 | F7 | (A) P2 | |||||
| P2 | @ F3 | F8 | ||||||
| P3 | F9 | |||||||
En la tabla, un array, se encuentran les direcciones de memoria de los frames correspondientes a cada una de les páginas de los procesos: (1,2,3,...) ---> (frame3,frame1,frame5,...). Por ejemplo: la página 1 del proceso está contenido al frame 3 de memoria. El único problema de la paginación es que se puede producir fragmentación interna cuando por ejemplo tenemos un proceso de 7 kb, y los frames son de 2kb, de manera que la última página dejará 1kb libre dentro del último frame. Cada PCB guardará donde se encuentra la tabla (dirección en donde comienza).
¿Cuántos procesos tendremos? n
¿Cuántas direcciones relativas tendremos en los procesos? n
Cada PCB de cada proceso guardará los registros fronteras el de línea y el da la pagina a más de estar registrados las tablas de paginación de los procesos.
Necesitamos tantas tablas de pagina como procesos que tiene.
Pero hay una fragmentación interna porque hay procesos q no son iguales a los “marcs” y hay espacio q se desaprovecha. Podemos dividir mucho + los frames para aprovechar espacio perdido en memoria pero lo que haría es aumentar la Tabla de Páginas.
Va mejor q el otro proceso, porque lo separamos en frames.
En el proceso pasa a ser una dirección relativa a una dirección absoluta, para que se pueda acceder a la Memoria Principal.
Esquema del funcionamiento de la paginación (incluyendo la protección de la memoria)
ERROR
Esta forma de trabajar es dinámica.
El procesador, al compilar, emite una dirección de memoria que esta dirección es relativa, por cada línea de programa. El proceso no se entera de nada. Por ejemplo de 0 a (8*1024-1) si el programa es de 8kb entonces queremos acceder a una variable donde el procesador genera una dirección relativa. Tiene que estar dentro del ámbito del proceso si intenta estar fuera genera un error sino seguimos teniendo una dirección relativa que se sabe que ya está bien (*@rel) e intercepta la dirección relativa. Dentro del rango de direcciones relativas que seria de 0 a (8*1024-1), tendremos que saber si esta dirección relativa es correcta, si este es el caso, hemos de saber el índice que apuntara a la tabla de direcciones del frame. Hay que poder transformar la dirección relativa y la subdivide en dos ámbitos la pagina en la que se quiere acceder(p) y el desplazamiento(d)
p: @rel división entera Tamaño de pagina
@rel
d: @rel el módulo o resto del tamaño de pagina.
Con la división entera entre el rango de memoria relativa y el tamaño del número de paginas el mod. (resto) de la misma operación accede a la tabla de paginas(T.P) a la pagina que había obtenido y accede a esa posición y accede a la @ del frame (f) suma el desplazamiento(d) y se obtiene la dirección absoluta para acceder a la Memoria Principal(M.P).
Una vez que sepamos la dirección del frame, hemos de saber en que parte de este se encuentra los datos, entonces sumamos el desplazamiento a la dirección del frame y así obtenemos la dirección absoluta.
Pero es muy lenta porque hay que recorrer varias tablas por que hay múltiples visitas a la memoria,(para evitar que pase por la tabla de PCB que se accede una vez por ejecucion y no cada vez por peticion) se puede evitar cuando se carga el proceso en memoria se accede a un registro base en donde esté la dirección de la tabla de paginas del proceso en ejecución, de esta manera hacemos servir la memoria cache para guardar las entradas a paginas de cada proceso de manera que estos accesos serán mucho mas rápidos y el sistema también es mucho mas rápido por que se ahorra muchos accesos. Se le suma de la p(Tamaño Página) y se consigue la dirección del Frame.
En sistemas pequeños nos conviene tener tablas de paginas en RAM, se guardan en registros (registros associativos).
Per 1 parte se coge la Memoria Principal la Memorial Real en trozos de la misma medida, llamados marcs o frames o “armazones”
Se coge el proceso o Memoria Lógica y se divide en trozos de la misma medida que los frames o marcs a todos ellos, se llama páginas.
T.P Tabla de paginas
M.P Memoria Principal
| SCB | PCB | PCB | PCB | ... | ||||
| |
Soluciones propuestas para aumentar el rendimiento:
-
Si tenemos un registro en el procesador que nos guardar la tabla de procesos se dedicará un registro (Registro Base) donde se guarda
En el momento que se cargue el proceso se guardará la tabla de direcciones del microprocesador y guardar la información en la PCB anterior para acceder directamente la tabla de registro de páginas. (nos guarda la dirección de la tabla de paginas del proceso activo)
-
En vez de q la tabla de paginas, solamente conservaremos las direcciones de las páginas que se utilizan con más frecuencias de las tablas de paginas (en memoria caché) y así se carga mucho más rápido.
| PA | P0 | @f |
| PB | P2 | @f |
| Proceso | Pag | @F |
| P1 | P3 | @F0 |
| P2 | P2 | @F1 |
Cuando se llene la tabla sustituirá los que son menos visitados por otros. También se puede hacer en vez con los más visitados por los últimos accedidos.
-
En sistemas pequeños y los procesos pequeños en vez de tener la tablas de paginas en memoria principal se guardan en registros y estos registros se llaman registros asociativos.
Paginación Compartida
La paginación es un sistema q nos permite compartir información entre diferentes procesos con la utilización de unos bits adicionales que se añaden a las entradas de las tablas de pagina. Se necesitarán, bits de protección que indiquen el tipos de acceso, que se puede realizar sobre una pagina y bits de validez que indicarán si el contenido de la pagina ha estado modificado o no.
| Tabla de Paginación Proceso 1 | Tabla de Paginación Proceso A | |||||||
| @F0 | @ F0 | Editor | ||||||
| @F2 | @ F2 | |||||||
| @F3 | @ F4 | NOM + PUS2 | ||||||
| @F5 | @ F6 | |||||||
| (Memoria Real) | ||
| F0 | (A) P0 | |
| F1 | ||
| F2 | P1 | |
| F3 | (PO1) P2 | |
| F4 | (PO2) P2 | |
| F5 | (A) P2 | |
| F6 | ||
| F7 | ||
-
Segmentación
La paginación parte sin mirar nada, corta por tamaño no mira si corta un bucle, puede producir fragmentación interna en la ultima pagina del proceso. Para evitarlo aparece la segmentación que divide el proceso de una forma lógica y racional.(no por donde toca, por medidas).
Un programa está formado por varios ficheros o segmentos, por partes lógicas:
Programa Principal, funciones, Tratamientos de error, de ficheros, tiene áreas para destinada para guardar la pila de invocación de procedimientos, las variables locales, las variables globales.
| Tabla de segmentos | ||||
| Indice(nº segmentos) | @base | Limite | ||
| 0 | PP | 0 | 1000 | 2000 |
| 1 | F1 | 1 | 4000 | 1000 |
| 2 | F2 | 2 | 5000 | 2000 |
| 3 | Fen | 3 | 9000 | 1000 |
| 4 | VG | 4 | 12000 | 3000 |
| 5 | VL | 5 | 15000 | 3000 |
| 6 | PI | 6 | 18000 | 2000 |
@Basedonde empieza.
Limite lo que ocupa
| (Memoria Real) | ||
| 1000 | PP | |
| 3000 | ||
| 4000 | F1 | |
| 5000 | ||
| 5000 | F2 | |
| 7000 | ||
| 9000 | Fen | |
| 10000 | ||
| 12000 | VG | |
| 15000 | ||
| 15000 | VL | |
| 18000 | ||
| 18000 | PI | |
| 20000 | ||
ERROR ERROR
RBTS Registro del Procesador que guarda en donde comienza la tabla del Segmento del proceso en ejecución
RLTS Registro del Procesador que guarda cuantos segmentos tiene el proceso en ejecución.
Cada vez que se cambia de proceso se anota en el PCB.
Con todo esto puede acceder a la tabla de segmentos en donde quiere acceder a la tabla de segmentos del proceso con el limite puede marcar el mínimo si d es mayor que el limite hay un error si es menor se le suma la base y da la dirección real para acceder a la Memoria Principal.
Al igual al sistema anterior se pueden compartir segmentos haciendo usos de los bits de protección y los bits de validez en la tabla de segmentos aprovechar
También se puede mejorar el rendimiento de la segmentación validar haciendo uso de la Memoria cache para almacenar las entradas de los segmentos más utilizados.
También como en sistema anterior en sistemas pequeños se puede utilizar los Registros Asociativos.
-
Sistemas combinados
· Segmentación - Paginada:
Es un sistema que se aplica en una máquina
Ej:
(GE 685 MULTICS)
ERROR
ERROR Flames
(RLTS)Registro Límite Tabla del Segmento Cuantos segmentos tiene el proceso.
(RBTS)Registro Base Tabla de Segmentación guarda en donde comienza la tabla del Segmento del proceso en ejecución.
P= (desplazamiento respecto al segmento. =d- DIV Tamaño Pagina
d'= (desplazamiento respecto a la pagina) =d MOD Tamaño Pagina
· Paginación - Segmentada:
Ej:
(IBM 370)
-
Memoria Virtual
Esquema:
· Hasta ahora: todo el proceso ha de estar en MP Todos los sistemas anteriores tenían que estar en memoria de forma completa (los procesos habían de estar en memoria
· Inconveniente: hay partes del proceso que no se ejecutarán nunca.
En la Memoria Virtual nada más se ubicará en la Memoria Principal las “partes” que se necesiten.
Partes:
-
Paginación
-
Segmentación
-
Sistemas combinados
-
Paginación Segmentada
-
Segmentación Paginada
· Ventajas:
-
El rendimiento de la Multiprogramación.
-
El tiempo de carga de un proceso en Memoria Principal es menor.
PA 100K t
PA 75K x x <= t pero nunca t > x
-
ML > MR (La Memoria Lógica tiene que ser mayor que la Memoria Real)
| PA | 100K |
| PB | 100K |
| PC | 100K |
| ML 300K = 300 MR |
| (ocupa el proceso) | (lo q necesito para ejecutarlo) | |||
| PA | 100K | 50K | 150K | 300K |
| PB | 100K | 50K | ||
| PC | 100K | 50K | ||
| PD | 100K | 50K | 150K | |
| PE | 100K | 50K | ||
| PF | 100K | 50K | ||
ML=600K > MR = 300K
-
Algoritmos de reemplazamiento
Características importantes de la Memoria Virtual:
Carga Cuando en un proceso se carga un proceso que se utilice.
Como se sabe que parte se ha de cargar: mediante la ejecución se generará una dirección y nos dará una petición de una dirección de memoria.
Puede ser de dos maneras:
· Carga por petición: A mediada que se hace se mira si exite esa parte en memoria
· Carga por Anticipación: Adivina lo que necesita. Nunca se lleva a termino, porque el sistema operativo no puede adivinar lo que tiene que ejecutar, puede cargar un proceso que al final no se ejecutará.
Colocación
Si el sistema está trabajando en paginación y me pidan una página y no está colocada en memoria, en donde se colocará, ¿En que frame de memoria? En el primero que esté libre (Todos los frames son de igual medida).
Si fuese segmentación ¿Dónde se puede colocará? Buscar en memoria un frame en que se tenga mayor e igual tamaño para que haya menor fragmentación.
Sustitución Cuando no se tiene espacio en la Memoria para cargar un programa y para ello se ha de sustituir.
Para saber que segmento o página a de ser sustituida (cambiada), se ha de utilizar
FIFO Primer proceso en entrar primero en salir
LRU Least Recently Used El menos recientemente usado, para este se utilizan diferentes técnicas:
Contadores de Hardware: utilizaremos un registro del procesador se irá contando cada vez que se hace una petición de página. Dentro de las tablas de pagina se ha de añadir un campo en el que sea un contador.
| T.P | T.S. | Contador |
| P3 | @F5 | 4 |
| P5 | @F9 | 3 |
Matrices de bits: Se necesita una matriz cuadrada de n bits en donde n es el número de frames que tiene la memoria.
Se coge la petición de la pagina se pone a 1 las filas y la misma columna a 0. Y así con todas.
| 0 | 0 | 1 | 2 | 3 | 4 |
| 0 | 0 | ||||
| 1 | 0 | ||||
| 2 | 1 | 1 | 0 | 1 | 1 |
| 3 | 0 | ||||
| 4 | 0 |
Se haría por el sistema binario el que tenga el valor binario más bajo es la candidata a borrarse de la memoria.
Por Pila: Se haría ordenando los procesos cuando se van utilizando
| P1 |
| P3 |
| P2 |
| P1 |
LFN(Least Frequently Used) El menos frecuentemente usado. Cada cierto tiempo pone el contador a 0 y se irán borrando cuando a la siguiente vez que el contador se ponga a 0 tenga algún proceso a 0 quiere decir que se utiliza menos.
-
Criterios de reemplazamiento de páginas
GESTIÓN DE ALMACENAMIENTO SECUNDARIO
Hasta ahora, hemos visto el disco duro es una pieza clave para el sistema operativo. Por ejemplo los
No siempre se utiliza el disco duro (DD), para guardar información si no que también se puede utilizar para el tratamiento de la información. Se pueden realizar pequeñas peticiones para el disco duro.
Estas pequeñas peticiones se pueden atender según el orden de llegada.
-
Planificación del disco duro.
Esta formado por 1 o varios discos metalizadas y magnetizadas(con voltaje), entre ellas tendremos los lectores. Los cabezales y los brazos (Los brazos solamente se pueden mover)
Cada disco tiene pistas donde está almacenada la información.
Un Cilindro es un conjunto de pistas de diferentes discos, en la misma posición.
El Sector es la pista dividida por partes, el sector puede ser = o no al bloque de información que se transfiere, puede ser un determinado bloque de información desde 512 bytes a 4K.
Clasificación por tiempos:
Si quiere entrar en una determinada pista (el brazo) hay un Tiempo de Búsqueda.
Pero de que aquella pista se ha
· Local por proceso
· Global para todos los procesos Se puede generar una falta de paginas para
la peor situación es q un proceso robe paginas y coja paginas propias, que constantemente se esté paginando, se podría llegar a crear una Hiperpaginación o “Trashing” que sería la peor consecuencia del sistema.
Hasta conseguir que el disco gire y que un terminado sector se ubique (se situe) debajo del cabezal del sector que quieres se llama Tiempo de Latencia.
El tiempo que tarda en coger del disco duro y llevar al procesador se llama Tiempo de Transmisión.
La hiperpaginación se puede producir cuando:
|
| HIPERPAGINACIÓN | ||||
| Frecuencia de faltas de paginación | |||||
| El proceso no genera falta de pagina. | |||||
| + nº FRAMES | |||||
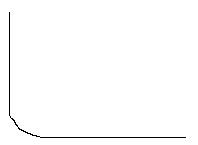
Mientras que los procesos se puedan producir sobre el intervalo, está bien el proceso. No hay hiperpaginación
Si está debajo el procesos no genera falta de paginas
Si está por encima hay hiperpaginación.
-
Algoritmos de petición
Los algoritmos de petición están clasificados:
FCFS (First come first server) Primera petición que llega primera que se sirve.
| 53 | 98 | 183 | 37 | 122 | 14 | 124 | 65 | |||||||||
| 45 | 85 | 146 | 85 | 108 | 110 | 50 | = | 638 cl | ||||||||
En este sistema hay muchos desplazamientos, se mueve por muchos cilindros y tarda mucho tiempo, en tiempo de Búsqueda.
SSTF (Shortest Seek Time First) Primero el de menor tiempo de Búsqueda.
Consiste en que las peticiones se atenúan aquellas que están más cerca. La cabecera siguiente cabecera será la cabecera más cercana, la que precisa menos desplazamiento.
| 53 | 65 | 37 | 14 | 98 | 122 | 124 | 183 | |||||||||
| 12 | 28 | 23 | 84 | 24 | 2 | 59 | = | 232 cl | ||||||||
Es más rápido que el anterior pero puede llegar a aplazar indefinidamente una posición.
SCAR (Exploración) Consiste que comienza por el primer cilindro y recorre hasta el último y vuelve a recorrer desde el principio hasta el final, sin atender ninguna petición. Tiene una mejora solamente puede llegar hasta el primer y último cilindro solicitado.
Vuelve al principio.
| 53 | 65 | 98 | 122 | 124 | 183 | 14 | 37 | |||||||||
| 12 | 33 | 24 | 2 | 59 | 169 | 23 | = | 322 cl | ||||||||
| rápido | ||||||||||||||||
C-SCAR (Exploración Circular) Es una variante de la anterior pero con una variante, va de principio al final y del final al principio, no vuelve a comenzar, como el anterior.
| 53 | 65 | 98 | 122 | 124 | 83 | 37 | 14 | |||||||||
| 12 | 33 | 24 | 2 | 59 | 146 | 23 | = | 299 o 309 cl | ||||||||
-
Asignación de memoria
-
Control del espacio disponible(Libre)
¿De qué manera puedo controlar el espacio?
Mapa de bits o vector de bits consiste en que en cada partición del o de los disco/s duro/s que tengamos hay un vector de bits que indica si está libre u ocupado el cluster o bloque de información.
1 libre
0 ocupado
| Nº cluster o bloque de información | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| Lib | Ocup | Ocup | Lib | Lib | Lib | ... |
Hay un inconveniente para que sea eficiente y consistente tendría que ubicarse, el mapa de bits en memoria principal, pero si es bastante grande se desaprovecharía memoria.
- Bloques enlazados
Cada bloque libre apunta, con un apuntador, al siguiente bloque libre.
En este sistema hay inconvenientes:
-
Gestión de apuntadores.
-
Si se pierde un apuntador chungo
-
Para poder conocer el espacio disponible hay que recorrer todos los bloques libres
Las ventajas: es muy facil de implantar.
- Tablas de Bloques libres
Habrá dos campos libres.
Cuando está poco fragmentado
| @Inicial Bloque libre | Cuantos bloq. Libres continuos hay. |
| 2 | 5 |
| 11 | 3 |
| 16 | 1 |
Cuando está muy fragmentado
| @Inicial Bloque libre | Cuantos bloques libres continuos hay. |
| 1 | 2 |
| 4 | 1 |
| 7 | 2 |
| 10 | 1 |
| 13 | 2 |
| 16 | 1 |
- Control del espacio ocupado.
-
Asignación continua Cuando yo necesito archivar un archivo previamente necesito saber cuando espacio necesitaré.
-
Con este sistema hay una perdida de espacio porque el usuario tendrá que sobredimensionar el espacio para que le quepa los sistemas. (Posible pérdida de espacio)
-
Si se queda corto de espacio, pueden asignarse más bloques que le preguntan la medida (extensión) para grabarlos. Estos bloques necesitas apuntadores, para que esté guardada como de forma continua
Tedremos una tabla:
| Datos del archivo (Nombre del archivo, fecha de creación, fecha de acceso,...) | Cuando comienza (En el bloque nº ...) | Cuantos bloques ocupa (la suma desde que comienza hasta que se acaba) |
-
Asignación Enlazada Cada bloque de cada archivo, los últimos bits apuntan los siguientes apuntadores del archivo.
-
Inconvenientes:
-
Gestión de apuntadores Si se pierde un apuntador “Chungo”, porque perderemos a partir de ahí perderemos el resto de información del archivo. Hay una alternativa para no perder la información “Solución” es tener dos apuntadores uno que vaya al siguiente bloque y otro al anterior, una lista doblemente enlazada.
-
Pérdida de espacio por el uso de los apuntadores(Cada apuntador ocupa 32bits por bloque).
Tabla del directorio
| Datos del archivo (Nombre del archivo, fecha de creación, fecha de acceso,...) | Apuntador en donde comienza el primer bloque | Apuntador al último bloque |
-
¿Como se puede gestionar un acceso directo en este sistema? No se puede gestionar, no es directo. hay una alternativa, el que utiliza el sistema FAT
-
FAT Tiene tantas posiciones con clusters (Bloques de información). El directorio tendrá los datos del archivo(permisos, modo de archivo, nombre)y la posición (a parte de información guardará la posición en donde está guardada la siguiente información).
| Datos archivo | Donde comienza* | FAT | |||
| Aaa | 2 | 0 | 5 | Tantas posiciones como clusters | |
| Bbb | 3 | 1 | -1 | ||
| Ccc | 0 | 2 | 4 | ||
| Ddd | 6 | 3 | 1 | ||
| 4 | 4 | ||||
| 5 | 1 | ||||
| 6 | 7 | ||||
| -1 | Donde se acaba | 7 | -1 | ||
| 6 | Espacio libre | 8 | 8 | ||
| Otros | Ocupados | -1 | |||
| -1 | |||||
-
Donde comienza el siguiente cluster, va recorriendo la fat.
-
Asignación Indexada Consiste
Tabla de directorios.
Información archivo, permisos, nombre archivo apuntador,...
Apuntador bloque de indice.
| I.Arch | Apun.bloq. indice |
| Aaa | |
| Bbb |
-
Asignación del espacio ocupado (UNIX)
4K = 4096Bytes
@4 bytes
1024@*4K
| Inode (Indice Nodo) |
| (I) del archivo |
| 12 apuntadores directos |
| 1 apunt indirecto sencillo |
| 1 apunt. Indirect. Doble |
| 1 apunt. indirec. Triple |
Cluster de 4k
12*4096+1024*4096+1024*1024*4096+1024*1024*1024*4096=4402345721856
Cluster de 8k
4096 8192
1024 2048
| 15*4 <= 48K 48<a>(48+4096k) |
| 15*4+1024*4 |
Método de Acceso
-
Secuencial va paso por paso.
-
Directo nos permite acceder directamente al archivo, no nos permite siempre(no se puede utilizar en estructuras enlazadas) depende tanto de la organización, como la unidad.
-
Indexado tendrá unas tablas en donde ubicará la dirección de una palabra clave. También se puede poner la palabra clave, según una función para que nos dé un determinado número de posición.
F(clau) fos
Estructuras de directorios
-
Estructura de un solo directorio
Solamente había un directorio y todo los archivos se guardaban allí.
No permitía una jerarquización de los archivos (ordenarlos)
-
Estructura de dos directorios
Son directorios de dos niveles. Uno que es la raiz y otro para cada usuario. Y dentro de cada subdirectorio, solamente se podrá poner los archivos con nombres cortos y sin jerarquizar.
-
Estructuras en árbol
Las que conocemos en MS-DOS. Un directorio principal, que tiene directorios y archivos, dentro de estos más directorio y archivos.
En este sistema, se crea términos como el camino de búsqueda de archivos y camino absoluto(camino que tiene desde un directorio partiendo desde el directorio principal(directorio raiz)) y camino relativo(caminos desde el directorio en donde estás actualmente).
-
Grafos Acíclicos
Grafos Estructura no jerarquizada.
Es una estructura en la que no nos podremos encontrar ciclos(bucles), ni estructruras en árbol.
Nos facilita los accesos directos.
No dirigido (en los dos sentidos, es bidireccional) Dirigido
Información de los archivos que se encuentran en las entradas de directorio
Los datos que nos dan en las entradas de los directorios son:
-
El nombre del archivo
-
Tipo del archivo (Extensión)
-
Su localización del bloque en donde está ubicada en disco
-
Protección del archivo
-
MS-DOS Atributos
W95/98 LM, CT, CSL, O,S,...
-
NT L, E, A, CT, Elim
-
UNIX Propietario, Grupo, todos los otros (de usuario)
-
Fecha y hora de creación
-
Fecha y hora de modificación
-
Contadores de uso y posición
-
Tamaño del archivo
-
Propietario
1
20
Registro Frontera
Registro Frontera
P
Menor
<
Acceso a la Mem. Principal
NO
SI
Reg. Frontera
Límite Inferior
(Donde comienza)
Mayor
>
Acceso a la Mem. Principal
SI
P
M.P
SI
Reg. Frontera
Límite Superior
(Donde termina)
Menor
<
NO
Lím. Superior
Reg. Base
(donde comienza el proceso)
Reg. Frontera
Límite (Tamaño del proceso)
+
Acceso a la Mem. Principal
Menor
<
SI
Ej: Si queremos poner un proceso de 200K. No nos cabe.
P
NO
NO
|
|
@rel
P
@ABS
Registro Frontera o Límite
@rel <
tamaño o límite
M.P
@rel
| p | d |
p+d
*@rel
Convertir @rel en
p + d
|
|
SI
P
@ABS
T.P
+
| f | d |
| @ f |
NO
@ T.P.
+ nº p
Var
Global
P.P
Var
Local
Fun-ciones
P.P
F2
Var
Global
F1
Pila
Invoc.
Registro Límite
Tabla Segmento
Reg. Base Tabla Seg
s <
RLTS
Tabla de Seg del Proceso
| Base | Limite |
s,d
+
M.P
| s | d |
|
|
SI
P
d<
Limite
@Real
T.P
+
Si
| @ f |
NO
No
Registro Límite
Tabla Segmento
Reg. Base Tabla Seg
RBTS
Tabla de Seg del Proceso
| Long Seg | @Base TP |
s <
RLTS
s,d
+
| s | d |
SI
P
T.P.S
@Real
| @ f |
+
Si (d)
d<
Limite
+
NO
Convertir (d) en (p,d')**
No
| s | d' |
M.P
|
|
p,d
d
Flames
M.P
| p | d |
P
|
|
@ f
T.P.S
p<Long TP
+
@Real
| @ f |
+
Si (p')
| s | p' |
No
ERROR
+
Tabla de Seg del Proceso
| Long TP | @Base TP |
RBTS
15 11
| 0 | 0 | 1 | 2 | 3 | 4 |
| 0 | 0 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 1 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 |
| 4 | 1 | 1 | 1 | 1 | 0 |
Arestas
Vertice
Bloq.de Indice 1024
Bloq.de Indice 1024
Bloq.(I)
Bloq.(I)
Bloq.de Indice 1024
Bloq.de Indice 1024
Bloq.de Indice depende del tamaño de un cluster.
Si cluster 4k 1024
Si cluster 8k 2048
Bloq.(I)
Bloq.de Indice 1024
Bloq.(I)
Bloq.de Indice 1024
Bloq. De Indice
Bloq.(I)
Bloq.(I)
Bloq.(I)
Bloq.(I)
Tabla de índice
| 6 |
| 8 |
| ... |
Tabla de índice
| 3 |
| 5 |
| 7 |
| 0 | 1 | 2 | 3 | |||
| 4 | 5 | 6 | 7 | |||
| 8 | 9 | 10 | 11 | |||
| 12 | 13 | 14 | 15 | |||
| 16 | 17 | 18 | 19 | |||
| 0 | 1 | 2 | 3 | |||
| 4 | 5 | 6 | 7 | |||
| 8 | 9 | 10 | 11 | |||
| 12 | 13 | 14 | 15 | |||
| 16 | 17 | 18 | 19 | |||
| Ocupado | |
| Libre |
| 0 | 1 | 2 | 3 | |||
| 4 | 5 | 6 | 7 | |||
| 8 | 9 | 10 | 11 | |||
| 12 | 13 | 14 | 15 | |||
| 16 | 17 | 18 | 19 | |||
Descargar
| Enviado por: | Tatyana |
| Idioma: | castellano |
| País: | España |
Todos los derechos reservados.