Electrónica, Electricidad y Sonido
Diseño de Multiplicador 4x8 en VLSI (Very Large Scale Integration)
DISEÑO DE MULTIPLICADOR 4 x 8 EN VLSI
INTRODUCCION AL VLSI
PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD DE INGENIERIA
DEPARTAMENTO DE ELECTRONICA
BOGOTA
2006
MULTIPLICADOR 4 x 8
INTRUDUCCION
El siguiente trabajo pretende explicar de manera sencilla el procedimiento utilizado en el diseño VLSI de un multiplicador básico de dos números, uno de 4 bits por otro de 8 bits. La realización de este proyecto es de carácter académico e intenta buscar un esquema adecuado en cuanto a medidas de velocidad, tamaño y disipación de potencia se refiere, obviamente utilizando parámetros de optimización que se encuentren dentro de los límites del curso. Se busca aprender a manejar las herramientas básicas para el diseño en layout y simulación (alliance a nivel de layout y pspice para simulaciones) de los circuitos implementados, al igual que utilizar los conocimientos adquiridos durante el curso para obtener resultados acordes con los objetivos preestablecidos para el proyecto.
ESQUEMA GENERAL
El multiplicador que se va a diseñar es un dispositivo poco práctico a la hora de hacer una multiplicación pero que, debido a su implementación de carácter rudimentario, requiere del diseño de muchos bloques funcionales, lo que resulta adecuado a la hora de enriquecer conocimientos.
El circuito funciona a partir de la realización de sumas consecutivas. El número de 8 bits es sumado tantas veces como el número de 4 bits lo indique. Por ejemplo, si se va a multiplicar 0101 (que equivale al número 5 en decimal) por 00011010 (26 en decimal), se realizará la operación: 26+26+26+26+26=130 (se suma 5 veces el número 26) que es lo mismo que multiplicar 26*5.
Teniendo claro el procedimiento a seguir para realizar la multiplicación, es importante definir los bloques necesarios para la ejecución de la misma. Debido a que la multiplicación se realizará a partir de sumas, la necesidad de un sumador es más que obvia, y será el primer bloque que se diseñará. Ya que necesitamos ir sumando el mismo número una y otra vez resulta práctico el uso de un dispositivo de almacenamiento como un registro, el cual vaya acumulando las sumas consecutivas es decir, que siempre sume el valor de la entrada con el valor previamente almacenado. Teniendo ya un dispositivo que acumule es necesario algo que indique cuantas veces acumular las sumas. Para esto resulta útil la implementación de un contador que se incremente hasta llegar al número de veces que se quiere sumar, lo que puede ser detectado mediante el uso de un comparador. Debido a las diferentes tareas que debe realizar el circuito, la utilización de una máquina de estados que indique cuando sumar, cuando mostrar el resultado, cuando resetear para empezar una nueva operación, etcétera, resulta valiosa siempre y cuando no complique mucho el “hardware” del circuito.
Habiendo establecido los bloques básicos, y teniendo muy claro la existencia de una máquina de estados, es indispensable definir de manera clara el comportamiento del circuito. Se definirán tres estados posibles para la máquina de estados: el primero donde se resetean tanto el registro como el contador, el segundo donde se realizan las sumas consecutivas, y el tercero donde se muestra el resultado. La definición de estos pasos indica de manera clara la necesidad de una señal de “arranque” que se encargue de inicializar el circuito para indicar cuando se realizará una nueva operación. Durante el siguiente trabajo llamaremos a esta señal de entrada “BEGIN” o “clear” indistintamente.
La siguiente figura muestra un esquema a grandes rasgos de la interconexión de los bloques básicos del circuito, donde A y B son el multiplicando y el multiplicador y S es el resultado.
A continuación se muestra el código AHDL y AHPL para el sistema digital que queremos implementar a partir de la máquina de estados:
AHDL
1. REG.CLR BEGIN, COUNT.CLR BEGIN
[1*BEGIN]+[2*BEGIN!]
2. REG SUM(REG,A), COUNT INC(COUNT)
[2*XOR(COUNT,B)!]+[3*XOR(COUNT,B)]
3. OUT=REG
[1*BEGIN]+[3*BEGIN!]
REG es el registro, COUNT es el contador, y OUT es la misma salida S.
Cualquier operación debe venir presidida por la señal de BEGIN. Siempre y cuando esta señal esté en estado alto la máquina de estados permanecerá en el paso 1 donde se da “clear” al registro y al contador. Una vez la señal de BEGIN pase a estado bajo, la máquina pasará al paso 2 donde se almacenará en el registro el valor que tenía almacenado anteriormente, más el valor de “a”. La máquina permanecerá en el paso 2 siempre y cuando el contador (el cual va incrementado cada pulso de reloj) tenga un valor diferente al de “b”. Una vez el contador llegue a ser igual a “b” la multiplicación habrá concluido y la máquina pasará al paso 3 donde la salida toma el valor del registro. La máquina permanecerá en este estado hasta que la señal de BEGIN vuelva a un estado alto, lo que indica el inicio de una nueva operación.
AHPL
title "Multiplicador";
subdesign multiplicador
(
a[7..0], b[3..0], beg, clk :input;
mul[11..0] :output;
)
variable
car[11..0] :node;
reg[11..0], s[2..0] :DFF;
count[3..0] :JKFF;
begin
s[].clk=not clk;
reg[].clk=clk and s[1].q;
s[0].d=Beg;
s[1].d=(s[0].q and (not beg)) or (s[1].q and not ((count[0].q xnor b[0]) and (count[1].q xnor b[1]) and (count[2].q xnor b[2]) and (count[3].q xnor b[3])));
s[2].d=(s[2].q and (not beg)) or (s[1].q and ((count[0].q xnor b[0]) and (count[1].q xnor b[1]) and (count[2].q xnor b[2]) and (count[3].q xnor b[3])));
reg[].clrn=not beg;
count[].clrn=not beg;
reg[0].d=reg[0].q xor a[0];
car[0]=reg[0].q and a[0];
reg[1].d=(reg[1].q xor a[1]) xor car[0];
car[1]=(reg[1].q and a[1]) or ((reg[1].q xor a[1]) and car[0]);
reg[2].d=(reg[2].q xor a[2]) xor car[1];
car[2]=(reg[2].q and a[2]) or ((reg[2].q xor a[2]) and car[1]);
reg[3].d=(reg[3].q xor a[3]) xor car[2];
car[3]=(reg[3].q and a[3]) or ((reg[3].q xor a[3]) and car[2]);
reg[4].d=(reg[4].q xor a[4]) xor car[3];
car[4]=(reg[4].q and a[4]) or ((reg[4].q xor a[4]) and car[3]);
reg[5].d=(reg[5].q xor a[5]) xor car[4];
car[5]=(reg[5].q and a[5]) or ((reg[5].q xor a[5]) and car[4]);
reg[6].d=(reg[6].q xor a[6]) xor car[5];
car[6]=(reg[6].q and a[6]) or ((reg[6].q xor a[6]) and car[5]);
reg[7].d=(reg[7].q xor a[7]) xor car[6];
car[7]=(reg[7].q and a[7]) or ((reg[7].q xor a[7]) and car[6]);
reg[8].d=(reg[8].q xor gnd) xor car[7];
car[8]=(reg[8].q and gnd) or ((reg[8].q xor gnd) and car[7]);
reg[9].d=(reg[9].q xor gnd) xor car[8];
car[9]=(reg[9].q and gnd) or ((reg[9].q xor gnd) and car[8]);
reg[10].d=(reg[10].q xor gnd) xor car[9];
car[10]=(reg[10].q and gnd) or ((reg[10].q xor gnd) and car[9]);
reg[11].d=(reg[11].q xor gnd) xor car[10];
car[11]=(reg[11].q and gnd) or ((reg[11].q xor gnd) and car[10]);
count[].J=vcc;
count[].K=vcc;
count[0].clk=not clk and s[1].q;
count[1].clk=not count[0].q;
count[2].clk=not count[1].q;
count[3].clk=not count[2].q;
mul[]=reg[].q and s[2].q;
end;
La siguiente gráfica muestra las simulaciones, realizadas en Quartus II de Altera, del código anterior:
Se puede observar claramente que el diseño planteado funciona adecuadamente al sumar los números “a” y “b” y mostrar el resultado “mul” después de que las sumas han terminado. La línea “reg” muestra los resultados parciales de las sumas que se van realizado después de cada pulso de reloj. En este ejemplo “s” denota los estados de la máquina: 001 es el paso 1, donde la señal de inicio resetea el contador y el registro; 010 es el paso 2 donde se realizan las sumas, y 100 es el paso 3 donde se muestra el resultado. La máquina de estados permanece en el paso 3 hasta que la señal de Begin “Beg” vuelva a ponerse en alto para indicar que se realizará una nueva operación.
Los números a multiplicar, el contador y el resultado están expresados en sistema hexadecimal.
BLOQUES FUNCIONALES
1. SUMADOR
Tal vez el bloque que hay que diseñar con mayor cuidado en nuestro diseño es el sumador, ya que será éste quien pondrá los límites de velocidad en la frecuencia del reloj.
Existen muchas maneras de optimizar el desempeño de un sumador, incluyendo diferentes topologías como carry lookahead o sumador condicional, que se encargan de hacer cálculos rápidos sacrificando tamaño y complejidad del esquema a utilizar. Debido a la falta de tiempo y a la poca práctica en el diseño de dispositivos digitales, utilizaremos un esquema de sumador básico: el sumador de rizado (ripple adder). Trataremos de mejorar el desempeño de nuestro sumador valiéndonos de herramientas como el “sizing” y el uso de lógica dinámica [1], lo que hace que nuestro diseño requiera de mucho cuidado a la hora de hacer las operaciones.
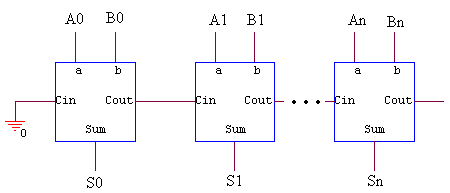
La topología de ripple adder se fundamenta en la interconexión de bloques básicos que sumen dos números de 1 bit cada uno y un carry de entrada, y obviamente retornen tanto el resultado de la suma como el carry de la misma. A esto se le conoce como un Full adder y por lo general se implementa de la siguiente manera:
![]()
Donde la compuerta mayoritaria es la encargada de calcular el carry y se construye:
![]()
Para la implementación del sumador existen técnicas de reducción lógica que disminuyen el número de transistores necesarios para hacer la suma. Estas técnicas son de gran utilidad a la hora de hacer circuitería con lógica estática donde el número mínimo de transistores es 2N, siendo N el número de funciones lógicas. Debido a que el tipo de lógica que usaremos acá será dinámica, donde el número de transistores a utilizar es de N+2 (con N el número de funciones lógicas básicas) este tipo de reducción resulta innecesario.
Habiendo establecido que nuestro sumador será implementado con lógica dinámica, debemos escoger un tipo de interconexión para cada bloque sumador (full adder). En este caso usaremos una interconexión tipo “dominó” con lógica tipo N, es decir los 2 transistores de sincronismo de reloj con un bloque PDN (Pull down network) y una compuerta negadora de lógica estática a la salida de cada bloque para evitar cambios inválidos durante los ciclos de evaluación [2]. La siguiente figura describe la topología a grandes rasgos:
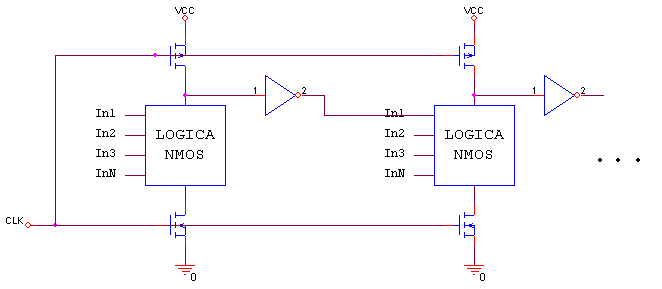
Teniendo clara la topología básica se procede a implementar las funciones lógicas a partir de transistores; comenzaremos con el bloque encargado de calcular el carry.
Como se mencionó anteriormente, la función lógica de carry es la misma compuerta mayoritaria: ![]()
que se construyó de la siguiente manera:
Debido a que esta función requiere de un número apreciable de transistores la aparición de varios nodos es inevitable. Como bien se sabe, una de las desventajas de lógica dinámica es la repartición de carga entre las capacitancias parásitas equivalentes que aparece en cada nodo del circuito. Para solucionar este problema se recurre a la utilización de transistores “keeper” o también al uso de transistores de precarga para nodos internos. Debido al gran número de nodos en el circuito la solución adecuada es la precarga de cada nodo interno por aparte como se muestra en la siguiente figura:
Con el circuito esquemático definido se procede al diseño del mismo a nivel de “layout”.
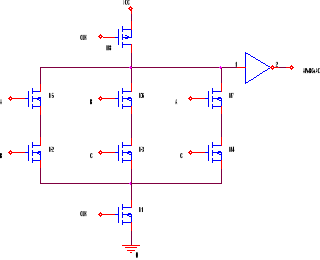
COMPUERTA MAYORITARIA (CARRY)
Siguiendo el mismo procedimiento que para el carry, diseñamos el circuito para la parte encarga de la suma:![]()
, que es equivalente a tener un circuito que calcule la función XOR a tres entradas:
Es importante notar que este circuito no tiene tres entradas sino seis, donde tres de ellas corresponden a A, B y Cin y las otras tres a las mismas señales negadas por lo que habrá que incluir una compuerta negadora para cada una de las entradas. También es importante incluir los transistores de precarga de nodos como se muestra a continuación:
Al igual que lo hicimos anteriormente procedemos a diseñar el circuito a nivel de “layout”
XOR DE 3 ENTRADAS (SUMA)
Con los circuitos encargados de hacer la suma y calcular el carry podemos armar nuestro “full adder” y proceder a hacer las simulaciones del sumador de 1 bit:
SUMADOR DE 1 BIT EN LOGICA DINAMICA (FULL ADDER)
Para el análisis de la simulación es importante recordar que los resultados (Sum y Cout) son válidos durante el ciclo de evaluación es decir, cuando Clk esté en 1 (alto).
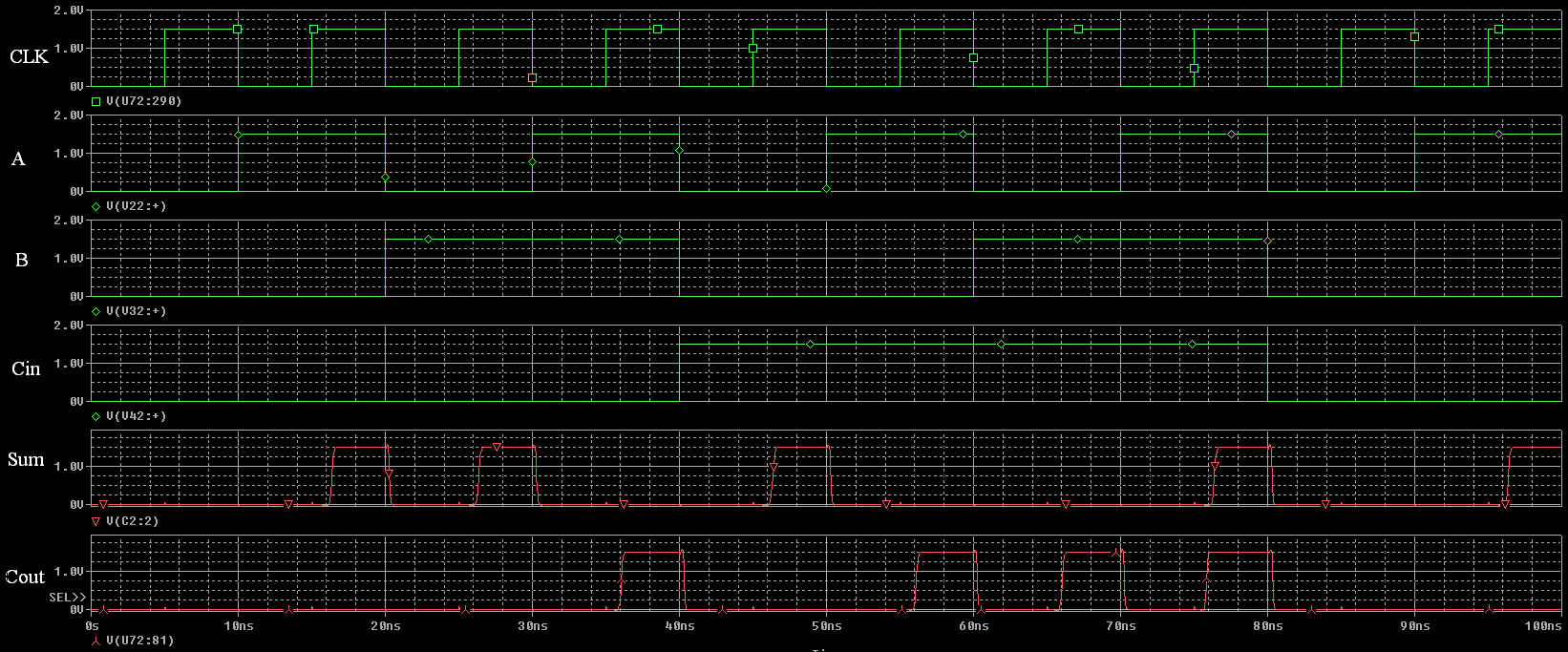
Con el bloque básico sumador podemos interconectar varios de ellos en cascada para formar nuestro sumador de 12 bits:
Al hacer la interconexión y proceder a simular se notó que había un serio problema con el diseño del sumador. Debido a que el resultado de la n-esima suma depende del resultado del carry del bloque n-1, y que cada bloque tiene un retardo para entregar tanto su resultado como el valor del carry, se estaba teniendo valores no válidos de carry de entrada en muchos de los bloques sumadores a la hora de llegar al ciclo de evaluación porque el reloj es exactamente el mismo para todos los bloques. Para solucionar este inconveniente, sin tener que recurrir a muchos cambios en la topología del diseño, se recurrió a una técnica de retardo de reloj, donde el reloj que recibe cada bloque tiene un retardo de valor igual al máximo retardo que se pueda llegar a tener en el carry del bloque anterior. De esta forma, el reloj se va retardando consecutivamente de la misma manera como se retarda el carry a través de los bloques sumadores. Después de haber culminado el proyecto se encontró que esta técnica es muy común en el diseño de circuitos de lógica dinámica y se ha utilizado previamente en aplicaciones similares a las de este trabajo [3].
Para generar el retardo se adicionaron cuatro compuertas negadoras a la entrada del reloj de cada uno de los bloques y se hicieron varias de las interconexiones utilizando polisilicio en vez de metal para aumentar los valores resistivos y por ende aumentar los tiempos de retardo. En la bibliografía que se encontró después, la técnica más común para generar los retardos es mediante el uso de compuertas negadoras interconectadas por compuertas pass gate (las cuales se diseñan para tener valores resistivos apreciables), lo que quiere decir que nuestro método de retardo no es igual de sofisticado, pero resulta ser una buena aproximación para ser éste un primer proyecto.

SUMADOR DE 1 BIT EN LOGICA DINAMICA CON CLOCK DELAY
Una vez modificado el sumador se hizo una simulación de tipo estático (entradas a Vcc o a tierra) tomando como ejemplo:
A=000011111111
B=110011111111
SUM=110111111110
Y verificando con la simulación el resultado:
Podemos ver que se obtienen resultados acordes con el ejemplo, donde el carry es de vital para la validez de los mismos.
2. REGISTRO
El registro será el dispositivo de almacenamiento encargado de ir guardando el resultado parcial de las múltiples sumas que se realizarán entre la entrada A y la salida acumulada en el registro.
El bloque básico para construir un registro es el “Flip-Flop”. Para el diseño se utilizará un “Data Flip-Flop” que almacena con borde de bajada del reloj. La principal razón por la cual se escogió este tipo de dispositivo es la precisión requerida a la hora de almacenar el dato entregado por el sumador, ya que éste por ser de tipo dinámico pone en su salida valores que muchas veces no son válidos. Otra razón por la que se escogió este dispositivo básico es la facilidad que presenta implementar divisores de frecuencia mediante el uso de “Flip-Flops” por borde, razón que se hará evidente cuando diseñemos nuestro contador.
El circuito esquemático del “Flip-Flop” utilizado se muestra a continuación:
El anterior circuito es una modificación del “Data Flip-Flop” comúnmente encontrado en la literatura de dispositivos de almacenamiento, por lo tanto no se discutirá la manera como funciona. La única diferencia entre el “Flip-Flop” convencional y el nuestro es la introducción de una señal de “clear” CLR la cual pone la salida Q en 0 (bajo) un pulso de reloj después de que ésta toma el valor 1 (alto) sin importar el valor de la señal “Data” D. Es claro que usualmente una señal de “clear” debe poner en 0 (bajo) la salida Q inmediatamente ésta toma el valor 1 (alto), sin embargo esto requiere de un mayor número de componentes. Además para nuestra aplicación el tipo de “clear” que se implementó funciona adecuadamente.
Todo el diseño del “Flip-Flop” fue realizado con lógica estática convencional y de manera jerárquica, se diseñaron bloques básicos como inversores, NANDs, NORs. A partir de estos bloques se implementó un “Set-Reset Latch” que aparece dos veces dentro del “Flip-Flop”, y con estos bloques se hizo la interconexión final que se muestra en la siguiente figura:

FLIP FLOP DATA CON ALMACENAMIENTO POR BORDE DE BAJADA
Las simulaciones siguientes muestran los tiempos de retardo de almacenamiento del “Flip-Flop” ya que estos son vitales para el correcto sincronismo de la suma, el almacenamiento, y la evaluación de los pasos de la máquina de estados.

En el registro cada bit almacenado es independiente de los demás, por lo tanto la simulación de un solo “Flip-Flop” es suficiente para evidenciar el correcto funcionamiento del mismo (la interconexión de los “Flip-Flops” ocasionará la aparición de capacitancias parásitas adicionales, pero para nuestro análisis éstas no afectan el comportamiento del circuito).
3. CONTADOR
El tipo de contador que se implementó se hizo a través de la interconexión de cuatro “Flip-Flops” de la misma naturaleza del diseñado para el registro:

El único inconveniente de este circuito es que, debido a que el “clear” de cada “Flip-Flop” toma validez una vez llegue el siguiente borde de bajada de reloj, la señal de clear no se hace válida al tiempo para todos los bloques del circuito porque la entrada de reloj de cada uno de ellos es la salida Q del bloque anterior, lo que quiere decir que para resetear todo el contador tomaría un total de 16 pulsos de reloj. Para solucionar este problema se utilizó un multiplexor tal que si la señal de “clear” toma el valor 1 (alto) el reloj de cada “Flip-Flops” no es la salida del “Flip-Flop” anterior sino la señal de reloj global CLK, y si la señal de “clear” está en 0 (bajo) el circuito funciona como lo muestra la figura anterior. A continuación se muestra la modificación del “Flip-Flop” original, incluyendo la retroalimentación de !Q a D:

Si CLR=0 el reloj del contador n es Qn-1.
Si CLR=1 el reloj del contador n es CLK.
El multiplexor utilizado se diseñó con lógica “pass-gate” y se muestra su esquemático, diseño en layout y simulación:


MULTIPLEXOR EN LOGICA PASS GATE

Si CLR=0 entonces CLKn=Qn-1.
Si CLR=1 entonces CLKn=CLK.
El layout del bloque básico del contador (Flip-Flop modificado) se muestra en la siguiente figura:

BLOQUE BASICO PARA IMPLEMENTAR CONTADOR
Es importante recalcar que el “sizing” que se hizo para el diseño del multiplexor en lógica “pass gate” no fue adecuado debido a que la resistencia de encendido para los transistores tipo n y los transistores tipo p depende de la movilidad de electrones y huecos, por lo tanto el tamaño relativo de los transistores (para el tipo de proceso escogido en particular) también debe ser diferente en compuertas diseñadas en este tipo de lógica. Desafortunadamente se cayó en cuenta de este error demasiado tarde para hacer su corrección, sin embardo el desempeño del circuito no se vio afectado significativamente.
Ya con el bloque básico construido, se interconectaron jerárquicamente cuatro de ellos para implementar el contador. El layout y su simulación se muestran a continuación:

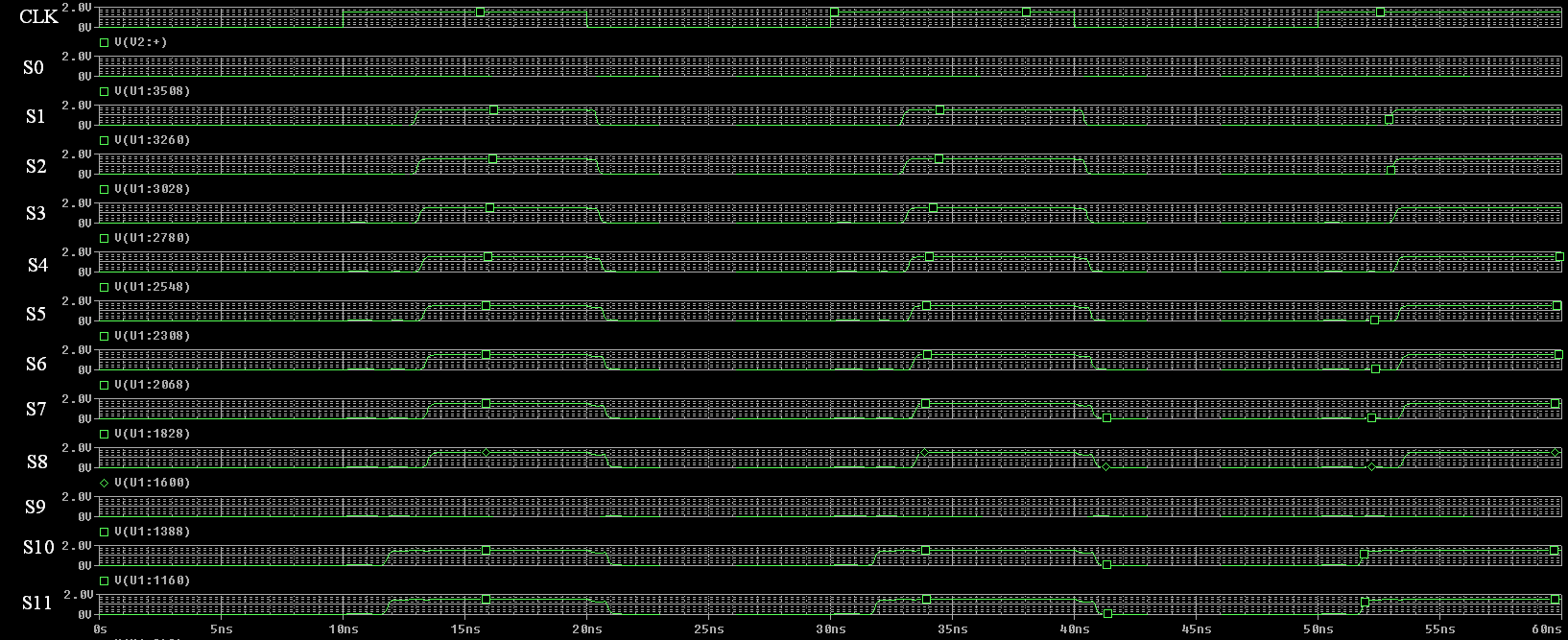
CONTADOR DE 4 BITS

El bit menos significativo es A0 y el más significativo A3. Se puede ver claramente como el contador aumenta desde 0000 (apenas la señal de CLR se hace 0) hasta 1111 y vuelve a comenzar. También se ve claramente que cuando la señal CLR vuelve a tomar el valor 1, el contador se resetea a 0000.
4. COMPARADOR
El comparador de nuestro circuito se encargará de avisar a la máquina de estados cuando el contador llega a un valor igual al de la entrada B. Para lograr esto utilizaremos cuatro XNORs y una AND que de la siguiente forma:

Cuando la señal C (la salida del contador) sea exactamente igual a la entrada de 4 bits B, la salida CONTROL tomará el valor de 1 de lo contrario la salida CONTROL permanecerá en 0.
Debido a la gran cantidad de transistores requeridos para implementar una compuerta XNOR en lógica estática convencional, implementamos estas compuertas en lógica “pass gate”. El esquemático de estas compuertas se muestra a continuación junto con el diseño en layout.


La compuerta AND que se utilizó se armó a partir de las compuertas inversoras y NAND que se había diseñado para el diseño del “Flip-Flop”.
Tanto el layout del comparador de 4 bits como su simulación se muestran en las siguientes figuras:

COMPARADOR DE 4 BITS
La simulación que se muestra a continuación es un caso particular donde la entrada B está estática y tiene el valor de 1111, por lo tanto la salida del comparador tomará el valor de 1 solo cuando el contador llegue a 1111.

5. MAQUINA DE ESTADOS
Al igual que los demás bloques del circuito, la máquina de estados requiere de un diseño cuidadoso ya que sus salidas y entradas deben estar perfectamente sincronizadas con las sumas y las cargas del registro.
Como mencionamos anteriormente la máquina de estados consta de tres pasos fundamentales: El primero donde se da “clear” al circuito (siempre y cuando la señal BEGIN esté en 1), el segundo donde se hacen las sumas (siempre y cuando la salida del comparador permanezca en 0), y el tercero donde se muestra la salida.
La manera como se implementó cada uno de los pasos fue mediante el uso de “Flip-Flops” y compuertas básicas para la lógica que indican cuando permanecer en un estado determinado o pasar al siguiente. Las ecuaciones utilizadas para la lógica son las siguientes:
S1.D=BEGIN
S2.D=(S1.Q and !BEGIN) or (S2.Q and !COMP)
S3.D=(S2.Q and COMP) or (S3.Q and !BEGIN)
Haciendo simplificaciones lógicas, mediante el uso de “De Morgan”, para dejar las ecuaciones en términos de NANDs, NORs y negadoras se llegó al siguiente circuito definitivo:

El layout y las simulaciones del anterior circuito se muestran a continuación:


Con lo realizado anteriormente logramos la generación de cada uno de los estados, sin embargo es importante saber que hacer con ellos:
-
La salida S1 simplemente indica un estado de espera ya que la señal de BEGIN va directamente conectada al “clear” del contador y el registro.
-
La salida S2 se utilizará como una especie de “Clock Enable” para el registro. Esto quiere decir que mientras no se esté en el paso S2 el registro no recibirá señal de reloj y mantendrá almacenado el dato que se tenía antes de que esta S2 se habilite.
-
La salida S3 se usará como “Output Enable” del registro es decir, que la salida del registro permanecerá en 0 (solo su salida, no los datos almacenados) siempre y cuando S3 permanezca en 0, y mostrará un dato válido cuando S3 tome el valor 1.
Teniendo en cuenta todas estas especificaciones se adicionó una entrada de “Clock Enable” (una compuerta AND entre el reloj CLK y esta entrada de “Clock Enable”, cuya salida es ahora el reloj de cada “Flip-Flop”) al registro sin embargo, debido a la falta de tiempo la parte del “Output Enable” no se alcanzó a implementar (una compuerta AND entre el Q de cada “Flip-Flop” y esta entrada de “Output Enable”, cuya salida sería la salida final del circuito).
5. CIRCUITO DEFINITIVO
Una vez se tenían los bloques listos se procedió a hacer la interconexión final y simular el multiplicador:

Las simulaciones que se muestran a continuación son ejemplos de ciertas multiplicaciones particulares:
Ejemplo 1: 15 x 13 = 195 (1111 x 00001101 = 11000011)

Ejemplo 2: 3 x 7 = 21 (0011 x 00000111 = 10101)

Como se puede ver, el circuito funciona bastante bien, por lo menos para los ejemplos mostrados anteriormente. Debido a que las simulaciones de todo el circuito resultan ser demoradas, no se incluyeron más ejemplos, sin embargo, debido a la naturaleza jerárquica del diseño se puede decir que el circuito funcionará bien para cualquier otro ejemplo que se realice.
CONCLUSIONES
Durante el diseño del circuito se presentaron varias dificultades tanto a nivel funcional como a nivel estructural. Las dificultades a nivel funcional se dieron más que todo en la parte del diseño con lógica dinámica. Debido a la poca experiencia con este tipo de circuitos se presentaron varías complicaciones que retrasaron el proceso de diseño ocasionando descuidos que no pudieron ser corregidos por la falta de tiempo, como el incorrecto sizing de las compuertas implementadas con lógica “pass gate”. A nivel estructural se presentaron muchas complicaciones a la hora de hacer las interconexiones. Estos problemas pudieron ser abolidos, o por lo menos reducidos, si se hubiera establecido desde el comienzo del diseño un “floor planning” del circuito. Sin embargo, considero que para lograr una adecuada concepción y entendimiento de lo que es el “floor planning” se debe tener experiencia en el campo del diseño en VLSI, y no esperar tener diseños perfectos desde el primer proyecto. La experiencia hace al maestro.
Debido a que este informe (EL INFORME, NO EL PROYECYO) lo hice voluntariamente me disculpo por su informalidad y posibles errores tanto a nivel gramático, ortográfico, etcétera, como a nivel técnico. Cualquier sugerencia, inquietud, corrección (que agradecería que hicieran) pueden escribirme a diemilioser@gmail.com.
BIBLIOGRAFIA
[1] Jan M. Rabaey, “Digital Integrated Circuits A Design Perspective”, Prentice-Hall, Dec 29, 1995.
[2] David Harris, “Introduction to CMOS VLSI Design”, Standford University.
[2] Jacob Baker, “Introduction to VLSI, Chapter 14 Dynamic Logic Gates.
[3] G. Yee and C.Sechen, “Clock-Delayed Domino for Adder and Combinational Logic design”, IEEE ICCD 1996.
[3] Aiyappan Natarajan, “Advanced Dynamic Logic Styles”, ECE 697V Paper Presentation.
[3] Tyler Thorp, Gin Yee and Carl Sechen, “Design and Synthesis of Monotonic Circuits”, Department of Electrical Engineering, University of Washington, Seattle, WA.
Descargar
| Enviado por: | Diego Emilio Serrano |
| Idioma: | castellano |
| País: | Colombia |
Todos los derechos reservados.