Informática
Sockets
Instituto Profesional “Cenafom”
Ramo : “Transmisión de Datos”
Santiago, Octubre de 2000
Indice
Introducción 3
¿Dónde nos Movemos? 4
I Parte. Conceptos Básicos de Redes 4
Protocolo de Comunicaciones 4
Capas de Red 4
Cliente y Servidor 6
IP Internet Protocol 6
TCP Transmission Control Protocol 7
UDP User Datagram Protocol 7
Dirección IP 8
Dominios 9
Puertos y Servicios 10
Cortafuegos (Firewall) 10
Servidores Proxy 10
URL Uniform Resource Locator 11
II Parte UNIX y los Sockets 11
2.1 ¿Qué son los Sockets? 12
Tipos de Sockets 13
Stream Sockets y Datagram Sockets 14
¿Cómo creo un Socket? 16
Obtención del Descriptor(Paso 1) 16
Dirección del Socket(Paso 2) 17
Opciones de Socket y Trabajo con Datagramas 19
Datagramas 21
Sendto 21
Recvfrom 21
III Parte Sockets Orientados a Conexión 22
3.1 El Servidor 22
3.2 Función Listen() 23
3.3 Función Accept() 23
3.4 El Cliente 25
3.5 Función Connect() 25
3.6 Funciones Close() y Shutdown() 26
3.7 Función Getpeername() 27
3.8 Función Gethostname() 27
3.9 Ultimos puntos a tener en cuenta 27
3.10 Señales más importantes 28
3.11 Temporizaciones 29
3.12 Función Select() 30
3.13 Programa Servidor 30
3.14 Programa Cliente 32
Conclusiones 34
Bibliografía 35
Introducción
Debido al rápido avance de los cambios tecnológicos que se suceden, muchas veces estos mismos no son muy claros para nosotros, pero al encontrarse fuera del ámbito de nuestro trabajo, no nos damos el tiempo, ni la ocasión de investigarlos y, de esta manera, comprenderlos. Uno de estos sectores, cuya evolución se ha hecho sentir con paso del tiempo, es la que concierne al desarrollo de los medios de comunicación de datos y que se acrecienta si pensamos en los diferentes formatos que disponemos actualmente para lograr esta comunicación.
Si quisiésemos lograr nosotros mismos una comunicación sin problemas, ¿Qué deberíamos hacer?, ¿Buscar entre los medios conocidos aquel que me dé más confiabilidad?, ¿Usar lo que tengo y no crearme más problemas?, ¿Probar si es que puedo programar algo que me dé solución o, al menos, libere carga del problema?…..Todas las posibles soluciones que se nos vendrían a la mente estarían orientadas casi en un 90% a responder las dos primeras interrogantes, pero ¿Por qué nos quedamos con un escuálido 10% para intentar resolver la última?, Y la respuesta se cimienta por lo que comentamos al principio, desconocemos muchos de los detalles que involucran los procesos de envío y recepción de información.
Este trabajo se orienta, precisamente, al tratamiento de este problema. Mejorar nuestro conocimiento de uno de los principales elementos que nos sirven de enlace a la hora de traspasar información, los Sockets. Si bien es cierto que un acabado estudio de todo lo que debemos saber a la hora de comprender cabalmente su funcionamiento traería el enfrentarse con tomos de información de diferentes tópicos con rasgos en común. Nuestro norte aquí será remitirnos a saber: ¿Qué es un Socket?, ¿Cómo funciona?, ¿Hay diferentes tipos de ellos?, ¿Es posible que me cree yo mismo un Socket?, ¿Existe algún tipo de restricciones en su uso?
Bueno este trabajo intentará despejar todas estas dudas y tratará de profundizar en aquellas áreas en las que me sea posible, sin dejar de mencionar el hecho de que podría estar obviando, quizás sin quererlo, algunos detalles importantes, mas me he esforzado para que esto no sea así.
Es bueno dejar en claro que como este concepto es nativo del sistema operativo UNIX algunos conceptos o notaciones podrían ser pocos claros, pero he intentado utilizar un lenguaje más conciliador.
Espero que al termino de la lectura, muchas de las interrogantes hayan sido despejadas y que sirva como base para un camino más profundo de investigación a este tema.
¿ Dónde nos Movemos?
Lo primero para entrar en materia sería definir cuál es nuestro campo de acción, o sea, el medio ambiente en el cual desarrollaremos nuestro trabajo y en el que programaremos lo que haya que codificar para culminar nuestras tareas.
Inevitablemente a la hora de entrar en materia de Sockets tendremos que caer en lo que a elección de un protocolo de red se refiere, pues nuestro objetivo, aunque no sea en un 100%, estará orientado a la transmisión de información desde un lugar a otro. Sin desmerecimiento de aquellos que quisiesen trabajar de un computador a otro en forma local, pero con esto perderíamos mucho de lo que queremos aprender o llegar a entender.
Sin querer tratar este trabajo como un compendio de Redes se hace justificable hacer mención a algunos conceptos básicos en las transmisiones de información, así que esta primera parte será dedicada a esto.
I. Parte Conceptos Básicos de Redes
Protocolo de Comunicaciones
Para que dos o más ordenadores puedan conectarse a través de una red y ser capaces de intercambiar datos de una forma ordenada, deben seguir un protocolo de comunicaciones que sea aceptado por todos ellos. El protocolo define las reglas que se deben seguir en la comunicación, por ejemplo, enseñar a los niños a decir por favor y gracias es una forma de indicarles un protocolo de educación, y si alguna vez se olvidan de dar las gracias por algo, seguro que reciben una reprimenda de sus mayores.
Hay muchos protocolos disponibles para ser utilizados; por ejemplo, el protocolo HTTP define como se van a comunicar los servidores y navegadores Web y el protocolo SMTP define la forma de transferencia del correo electrónico. Estos protocolos, son protocolos de aplicación que actúan al nivel de superficie, pero también hay otros protocolos de bajo nivel que actúan por debajo del nivel de aplicación.
Capas de Red
Las redes están separadas lógicamente en capas, o niveles, o layers; desde el nivel de aplicación en la parte más alta hasta el nivel físico en la parte más baja. Los detalles técnicos de la división en capas o niveles de la red se escapan de este trabajo. La única capa interesante para el usuario y el programador es el Nivel de Aplicación, que es el que se encarga de tomar los datos en una máquina desde esta capa y soltarlos en la otra máquina en esta misma capa, los pasos intermedios y los saltos de capas que se hayan producido por el camino están ocultos.
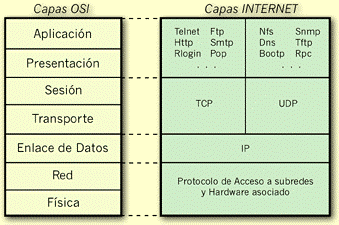
La figura siguiente muestra la correlación existente entre el modelo teórico de capas o niveles de red propuestos por la Organización de Estándares Internacional (ISO, International Standards Organisation) y el modelo empleado por las redes TCP/IP. Cuando se presenta un problema de tamaño considerable, la solución más óptima comienza por dividirlo en pequeñas secciones, para posteriormente proceder a solventar cada una de ellas independientemente. Pues el mismo principio de divide y vencerás es el que se sigue a la hora de diseñar redes, es decir, separar en un buen número de niveles el hecho de la transmisión de un sistema a otro. Como referencia, la ISO, creó un modelo de interconexión de sistemas abiertos, conocido como OSI. Ese modelo divide en siete capas el proceso de transmisión de información entre equipos informáticos, desde el hardware físico, hasta las aplicaciones de red que maneja el usuario. Estas capas son las que se pueden ver en la figura siguiente: física, de enlace de datos, de red, de transporte, de sesión, de presentación y, por último, de aplicación. Cada nuevo protocolo de red que se define se suele asociar a uno (o a varios) niveles del estándar OSI. Internet dispone de un modelo más sencillo; no define nada en cuanto al aspecto físico de los enlaces, o a la topología o clase de red de sus subredes y, por lo tanto, dentro del modelo OSI, sólo existe una correlación con los niveles superiores.
Las aplicaciones que trabajan a un cierto nivel o capa, sólo se comunican con sus iguales en los sistemas remotos, es decir, a nivel de aplicación; un navegador sólo se entiende con un servidor Web, sin importarle para nada cómo le llega la información. Este mismo principio es el que se emplea para el resto de las capas. Para ilustrar este concepto de capas o niveles, puede resultar explicativo ver qué sucede cuando se solicita una página Web. En este caso, el navegador realiza una petición HTTP, petición que se incluye en un paquete TCP, que a su vez es encapsulado y fragmentado en uno o varios datagramas IP, que es la unidad de datos a nivel de red. Dichos datagramas son de nuevo encapsulados en unidades de datos PPP, o frames, que se envían al proveedor de Internet a través del módem, que transforma esas unidades digitales de datos en señales acústicas de acuerdo a una determinada norma, V.34bis o V.90, por ejemplo. El proveedor de Internet ensamblará los paquetes PPP para convertirlos de nuevo en datagramas IP, que son llevados a su destino, donde serán decodificados en sentido inverso al realizado en el equipo originador de la petición, hasta que alcancen el nivel de aplicación, que supone el servidor web.
De todo esto, se deben sacar tres ideas fundamentales. En primer lugar, que TCP/IP opera sólo en los niveles superiores de red, resultándole indiferente el conjunto de protocolos que se entienden con los adaptadores de red Token Ring, Ethernet, ATM, etc., que se encuentren por debajo. En segundo lugar, que IP es un protocolo de datagramas que proporciona una interfaz estándar a protocolos superiores. Y, en tercer lugar, que dentro de estos protocolos superiores se incluyen TCP y UDP, los cuales ofrecen prestaciones adicionales que ciertas aplicaciones de red necesitan.
Cliente y Servidor
Este es un término comúnmente aplicado a la arquitectura del software en el cual las funciones de procesamiento están segmentadas en colecciones independientes de servicios y peticiones en una única máquina o divididas en varias máquinas. Uno o más procesos del Servidor otorgan los servicios a otros clientes en el mismo o a través de múltiples plataformas de trabajo. Un Servidor encapsula completamente sus procesos y presenta una interfaz bien definida para los clientes.
IP, Internet Protocol
Es el protocolo que se utiliza por debajo del Nivel de Aplicación para traspasar datos entre cliente y servidor. El lector no necesita más que saber de su existencia; no obstante, indicar que es un protocolo de red encargado de mover datos en forma de paquetes entre un origen y un destino y que, como bien indica su nombre, es el protocolo que normalmente se utiliza en Internet.
IP es un protocolo simple, fácilmente implementable, de pequeñas unidades de datos o datagramas, que proporciona un interfaz estándar a partir del cual el resto de los protocolos y servicios pueden ser construidos, sin tener que preocuparse de las diferencias que existan entre las distintas subredes por las cuales circulen los datos.
Todo dispositivo conectado a Internet o a cualquier red basada en TCP/IP, posee al menos una dirección IP, un identificador que define unívocamente al dispositivo que lo tiene asignado en la red.
Un datagrama IP se encuentra dividido en dos partes: cabecera y datos. Dentro de la cabecera se encuentran, entre otros campos, la dirección IP del equipo origen y la del destino, el tamaño y un número de orden.
IP opera entre un sistema local conectado a Internet y su router o encaminador más próximo, así como entre los distintos encaminadores que forman la red. Cuando un datagrama llega a un encaminador, éste determina, a partir de su dirección IP de destino, hacia cuál de sus conexiones de salida ha de dirigir el datagrama que acaba de recibir. Por desgracia, en cuanto al transporte, IP provee un servicio que intenta entregar los datos al equipo destino, pero no puede garantizar la integridad, e incluso la recepción de esos datos. Por ello, la mayoría de las aplicaciones hacen uso de un protocolo de más alto nivel que ofrezca el grado de fiabilidad necesario.
Cada datagrama IP es independiente del resto, por lo que cada uno de ellos es llevado a su destino por separado. La longitud del datagrama es variable, pudiendo almacenar hasta 65 Kbytes de datos; si el paquete de datos (TCP o UDP) sobrepasa ese límite, o el tamaño de la unidad de datos de la red que se encuentra por debajo es más pequeño que el datagrama IP, el mismo protocolo IP lo fragmenta, asignándole un número de orden, y distribuye empleando el número de datagramas que sea necesario.
TCP, Transmission Control Protocol
Hay veces en que resulta de vital importancia tener la seguridad de que todos los paquetes que constituyen un mensaje llegan a su destino y en el orden correcto para la recomposición del mensaje original por parte del destinatario. El protocolo TCP se incorporó al protocolo IP para proporcionar a éste la posibilidad de dar reconocimiento de la recepción de paquetes y poder pedir la retransmisión de los paquetes que hubiesen llegado mal o se hubiesen perdido. Además, TCP hace posible que todos los paquetes lleguen al destinatario, juntos y en el mismo orden en que fueron enviados.
Por lo tanto, es habitual la utilización de los dos acrónimos juntos, TCP/IP, ya que los dos protocolos constituyen un método más fiable de encapsular un mensaje en paquetes, de enviar los paquetes a un destinatario, y de reconstruir el mensaje original a partir de los paquetes recibidos.
TCP, en resumen, ofrece un servicio de transporte de datos fiable, que garantiza la integridad y entrega de los datos entre dos procesos o aplicaciones de máquinas remotas. Es un protocolo orientado a la conexión, es decir, funciona más o menos como una llamada de teléfono. En primer lugar, el equipo local solicita al remoto el establecimiento de un canal de comunicación; y solamente cuando ese canal ha sido creado, y ambas máquinas están preparadas para la transmisión, empieza la transferencia de datos real.
UDP, User Datagram Protocol
Hay veces en que no resulta tan importante que lleguen todos los mensajes a un destinatario, o que lleguen en el orden en que se han enviado; no se quiere incurrir en una sobrecarga del sistema o en la introducción de retrasos por causa de cumplir esas garantías. Por ejemplo, si un ordenador está enviando la fecha y la hora a otro ordenador cada 100 milisegundos para que la presente en un reloj digital, es preferible que cada paquete llegue lo más rápidamente posible, incluso aunque ello signifique la pérdida de algunos de los paquetes. El protocolo UDP está diseñado para soportar este tipo de operaciones. UDP es, por tanto, un protocolo menos fiable que el TCP, ya que no garantiza que una serie de paquetes lleguen en el orden correcto, e incluso no garantiza que todos esos paquetes lleguen a su destino. Los procesos que hagan uso de UDP han de implementar, si es necesario, sus propias rutinas de verificación de envío y sincronización. Como programador, el lector tiene en sus manos la elección del protocolo que va a utilizar en sus comunicaciones, en función de las características de velocidad y seguridad que requiera la comunicación que desea establecer.
Dirección IP
La verdad es que no se necesita saber mucho sobre el protocolo IP para poder utilizarlo, pero sí que es necesario conocer el esquema de direccionamiento que utiliza este protocolo. Cada ordenador conectado a una red TCP/IP dispone de una dirección IP única de 4 bytes (32 bits), en donde, según la clase de red que se tenga y la máscara, parte de los 4 bytes representan a la red, parte a la subred (donde proceda) y parte al dispositivo final o nodo específico de la red. La figura siguiente muestra la representación de los distintos números de una dirección IP de un nodo perteneciente a una subred de clase B (máscara 255.255.0.0). Con 32 bits se puede definir una gran cantidad de direcciones únicas, pero la forma en que se asignaban estas direcciones estaba un poco descontrolada, por lo que hay muchas de esas direcciones que a pesar de estar asignadas no se están utilizando.
Por razones administrativas, en los primeros tiempos del desarrollo del protocolo IP, se establecieron cinco rangos de direcciones, dentro del rango total de 32 bits de direcciones IP disponibles, denominando a esos subrangos, clases. Cuando una determinada organización requiere conectarse a Internet, solicita una clase, de acuerdo al número de nodos que precise tener conectados a la Red. La administración referente a la cesión de rangos la efectúa InterNIC (Internet Network Information Center), aunque existen autoridades que, según las zonas, gestionan dominios locales; por ejemplo, el dominio correspondiente a España lo gestiona Red Iris.
Los subrangos se definen en orden ascendente de direcciones IP, por lo cual, a partir de una dirección IP es fácil averiguar el tipo de clase de Internet con la que se ha conectado. El tipo de clase bajo la que se encuentra una dirección IP concreta viene determinado por el valor del primer byte de los cuatro que la componen o, lo que es igual, el primer número que aparece en la dirección IP. Las clases toman nombre de la A a la E, aunque las más conocidas son las A, B y C. En Internet, las redes de clase A son las comienzan con un número entre el 1 y el 126, que permiten otorgar el mayor número de direcciones IP (16,7 millones), por lo que se asignan a grandes instituciones educativas o gubernamentales. Las clases B (65536 direcciones por clase), suelen concederse a grandes empresas o corporaciones y, en general, a cualquier organización que precise un importante número de nodos. Las redes de clase C (256 direcciones) son las más comunes y habitualmente se asignan sin demasiados problemas a cualquier empresa u organización que lo solicite. La clase D se reserva a la transmisión de mensajes de difusión múltiple (multicast), mientras que la clase E es la destinada a investigación y desarrollo. La tabla siguiente resume estos datos:
Todo lo dicho antes solamente implica a la asignación de direcciones dentro de Internet. Si se diseña una red TCP/IP que no vaya a estar conectada a la Red, se puede hacer uso de cualquier conjunto de direcciones IP. Solamente existen cuatro limitaciones, intrínsecas al protocolo, a la hora de escoger direcciones IP, pero que reducen en cierta medida el número de nodos disponibles por clase que se indicaban en la tabla anterior. La primera es que no se pueden asignar direcciones que comiencen por 0; dichas direcciones hacen referencia a nodos dentro de la red actual. La segunda es que la red 127 se reserva para los procesos de resolución de problemas y diagnosis de la red; de especial interés resulta la dirección 127.0.0.1, bucle interno (loopback) de la estación de trabajo local. La tercera consiste en que las direcciones IP de nodos no pueden terminar en 0, o en cualquier otro valor base del rango de una subred; porque es así como concluyen las redes. Y, por último, cuando se asignan direcciones a nodos, no se pueden emplear el valor 255, o cualquier otro valor final del rango de una subred. Este valor se utiliza para enviar mensajes a todos los elementos de una red (broadcast); por ejemplo, si se envía un mensaje a la dirección 192.168.37.255, se estaría enviando en realidad a todos los nodos de la red de clase C 192.168.37.xx.
Ahora bien, si se quiere que una red local tenga acceso exterior, hay una serie de restricciones adicionales, por lo que hay una serie de direcciones reservadas que, a fin de que pudiesen ser usadas en la confección de redes locales, fueron excluidas de Internet. Estas direcciones se muestran en la siguiente tabla.
Actualmente, se intenta expandir el número de direcciones únicas a un número mucho mayor, utilizando 128 bits. E.R. Harold, en su libro Java Network Programming, dice que el número de direcciones únicas que se podría alcanzar representando las direcciones con 128 bits es 1.6043703E32. La verdad es que las direcciones indicadas de esta forma son difíciles de recordar, así que lo que se hace es convertir el valor de los cuatro bytes en un número decimal y separarlos por puntos, de forma que sea mucho más sencillo el recordarlos; por ejemplo, la dirección única asignada a java.sun.com es 204.160.241.98.
Dominios
Y ahora surge la pregunta de qué es lo que significa java.sun.com. Como a pesar de que la dirección única asignada a un ordenador se indique con cuatro cifras pequeñas, resulta muy difícil recordar las direcciones de varias máquinas a la vez; muchas de estas direcciones se han hecho corresponder con un nombre, o dominio, constituido por una cadena de caracteres, que es mucho más fácil de recordar para los humanos. Así, el dominio para la dirección IP 204.160.241.98 es java.sun.com.
El Sistema de Nombres de Dominio (DNS, Domain Name System) fue desarrollado para realizar la conversión entre los dominios y las direcciones IP. De este modo, cuando el lector entra en Internet a través de su navegador e intenta conectarse con un dominio determinado, el navegador se comunica en primer lugar con un servidor DNS para conocer la dirección IP numérica correspondiente a ese dominio. Esta dirección numérica IP, y no el nombre del dominio, es la que va encapsulada en los paquetes y es la que utiliza el protocolo Internet para enrutar paquetes desde el ordenador del lector hasta su destino.
Puertos y Servicios
Un servicio es una facilidad que proporciona el sistema, y cada uno de estos servicios está asociado a un puerto. Un puerto es una dirección numérica a través de la cual se procesa el servicio, es decir, no son puertos físicos semejantes al puerto paralelo para conectar la impresora en la parte trasera del ordenador, sino que son direcciones lógicas proporcionadas por el sistema operativo para poder responder.
Sobre un sistema Unix, por ejemplo, los servicios que proporciona ese sistema y los puertos asociados por los cuales responde a cada uno de esos servicios, se indican en el fichero /etc/services, y algunos de ellos son:
daytime 13/udp
ftp 21/tcp
telnet 23/tcp telnet
smtp 25/tcp mail
http 80/tcp
La primera columna indica el nombre del servicio. La segunda columna indica el puerto y el protocolo que está asociado al servicio. La tercera columna es un alias del servicio; por ejemplo, el servicio smtp, también conocido como mail, es la implementación del servicio de correo electrónico.
Las comunicaciones de información relacionada con Web tienen lugar a través del puerto 80 mediante protocolo TCP.
Teóricamente hay 65535 puertos disponibles, aunque los puertos del 1 al 1023 están reservados al uso de servicios estándar proporcionados por el sistema, quedando el resto libre para utilización por las aplicaciones de usuario. De no existir los puertos, solamente se podría ofrecer un servicio por máquina. Nótese que el protocolo IP no sabe nada al respecto de los números de puerto, al igual que TCP y UDP no se preocupan en absoluto por las direcciones IP. Se puede decir que IP pone en contacto las máquinas, TCP y UDP establecen un canal de comunicación entre determinados procesos que se ejecutan en tales equipos y, los números de puerto se pueden entender como números de oficinas dentro de un gran edificio. El edificio (equipo), tendrá una única dirección IP, pero dentro de él, cada tipo de negocio, en este caso HTTP, FTP, etc., dispone de una oficina individual.
Cortafuegos
Un cortafuegos(Firewall) es el nombre que se da a un equipo y su software asociado que permite aislar la red interna de una empresa del resto de Internet. Normalmente se utiliza para restringir el grado de acceso a los ordenadores de la red interna de una empresa desde Internet, por razones de seguridad o cualquier otra.
Servidores Proxy
Un servidor proxy actúa como interfaz entre los ordenadores de la red interna de una empresa e Internet. Frecuentemente, el servidor proxy tiene posibilidad de ir almacenando un cierto número de páginas web temporalmente en caché, para un acceso más rápido. Por ejemplo, si diez personas dentro de la empresa intentan conectarse a un mismo servidor Internet y descargar la misma página en un período corto de tiempo, esa página puede ser almacenada por el servidor proxy la primera vez que se accede a ella y proporcionarla él, sin necesidad de acceder a Internet, a las otras nueve personas que la han solicitado. Esto reduce en gran medida el tiempo de espera por la descarga de la página y el tráfico, tanto dentro como fuera de la empresa, aunque a veces puede también hacer que la información de la página se quede sin actualizar, al no descargarse de su sitio original.
URL, Uniform Resource Locator
Una URL , o dirección, es en realidad un puntero a un determinado recurso de un determinado sitio de Internet. Al especificar una URL, se está indicando:
-
El protocolo utilizado para acceder al servidor (http, por ejemplo)
-
El nombre del servidor
-
El puerto de conexión (opcional)
-
El camino (directorio)
-
El nombre de un fichero determinado en el servidor (opcional a veces)
-
Un punto de referencia dentro del fichero (opcional)
La sintaxis general, resumiendo pues, para una dirección URL, sería:
protocolo://nombre_servidor[:puerto]/directorio/fichero#referencia
El puerto es opcional y normalmente no es necesario especificarlo si se está accediendo a un servidor que proporcione sus servicios a través de los puertos estándar; tanto el navegador como cualquier otra herramienta que se utilice en la conexión conocen perfectamente los puertos por los cuales se proporciona cada uno de los servicios e intentan conectarse directamente a ellos por defecto.
Concluida la primera parte en la que sólo se pretendía presentar una variedad de conceptos de manejo imprescindible en lo que a redes y procesos de comunicación se refiere ya podremos pasar a la siguiente etapa que es el trabajo en sí ahora, ¿Porqué es necesario que rayemos la cancha?. Simple, este concepto proviene de UNIX, y pese a que se han implementado diferentes tipos de Sockets( o formatos descriptivos que emulan este comportamiento, tales como Winsocket para Windows, SSL en Netscape) en los más diversos medioambientes de trabajo, profundizaremos su estudio a este Sistema Operativo y, por lo tanto, a su protocolo de transmisión y se hace muy necesario que cuando hablemos de estos términos no tengamos vacíos en nuestro acervo tecnológico.
II Parte. UNIX y los Sockets
Sin duda habrás escuchado muchas veces el término Socket, pues bien, sin definirlo a la perfección todavía los Sockets son una forma de hablar con otros archivos usando los descriptores de archivos standard de UNIX. Lo más probable es que también hayas escuchado muchas veces la profundización de que en UNIX “todo es un archivo”, esto se explica por el hecho de que cuando UNIX hace cualquier tipo de ordenamiento de I/O, lo realiza mediante la lectura o escritura de un descriptor de archivo. Un descriptor de archivo es simplemente un entero asociado con el archivo abierto, pero he aquí el truco, ese archivo puede ser una conexión a redes, un FIFO, un Pipe, una terminal o cualquier otra cosa. Es debido a esto que se ha acuñado la frase ya mencionada. Una vez comprendido esto vamos a la captura de este descriptor, ¿Cómo lo hacemos?, La respuesta es la llamada Socket(), la cual te regresa el descriptor y entonces puedes comunicarte a través de él usando las llamadas especializadas sendto() y recvfrom(). Ahora ¿Porqué no usar las llamadas read() y write()normales para comunicarme a través del Socket? Simple, porque aunque puedes, perfectamente hacerlo, no obtendrás el máximo manejo que te ofrecen sendto() y recvfrom(), para la transmisión de datos.
¿Qué son los Sockets?
Ok, entrando en lo que a materia de trabajo se refiere, los Sockets tienen la más amplia y variada cantidad de definiciones que he visto, no he logrado encontrar un par de ellas en la red que compartan el mismo cuerpo, aunque si la misma filosofía en su enunciado, aunque todas ellas tienen un punto en común y es, que se les considera el componente sin el cual la transmisión de datos no sería posible. Pues bien veamos algunas definiciones antes de dar la nuestra:
-
“ Un Socket es un punto de comunicación, que se comunica con otro Socket para enviarle mensajes. Son bidireccionales, los hay de varios tipos y nos permiten comunicarnos con un proceso que está en otro computador” (Linux Actual, año 1, número 9)
-
“ Los Sockets son puntos finales de enlaces de comunicaciones entre procesos. Los procesos los tratan como descriptores de ficheros, de forma que se pueden intercambiar datos con otros procesos transmitiendo y recibiendo a través de Sockets. El tipo de Sockets describe la forma en la que se transfiere información a través de ese Socket.” (Tutorial de Java, Agustín Froufe, http://members.es.tripod.de/froufe/index.html)
-
“Un Socket es una entidad de software que provee el bloque de construcción básica para las comunicaciones interprocesos. Los Sockets permiten a los procesos reunirse en un nombre de espacio UNIX a través del cual producen un intercambio de información. Un Socket es el punto final de proceso de comunicación entre procesos. Para. Direcciones IPX un par de nombres bien definidos identifican el par de Sockets entre medios de comunicación.”(Esta la extraje de una página de la red, pero no tenía mayor info del autor, ni de dónde provenía).
-
Los Sockets son como los “hoyos de los gusanos” en la ciencia-ficción, cuando las cosas entran por una parte, deberían salir por otra. Diferentes tipos de Sockets tienen diferentes propiedades.(Grupo de noticias de UNIX, sacado de un FAQ, http://www.ibrado.com/sock-faq/)
Las definiciones demuestran que no me había desmandado en lo absoluto a la hora de describirles sobre el poco consenso que hay cuando de unificar criterios se trata. Intentando generar una definición propia podría decir que los Sockets son un concepto abstracto que define el punto final de una transmisión entre dos computadoras, por lo que resulta bidireccional. Cada uno de los Sockets tiene una única dirección que se describe genéricamente por el comando “sockaddr” de 16 bytes en la estructura de programación en C.
Este concepto se introdujo en UNIX Berkeley, si quisiésemos describirlo mediante un ejemplo consideremos lo siguiente: “Un Socket resultaría como un adaptador virtual entre un programa y un protocolo de red. Si tuviésemos un servidor FTP en línea, un Socket se crearía por el servidor del programa FTP, su trabajo consiste en escuchar en el puerto 21 del TCP, y si el IP pasa algún paquete, el Socket lo pasará al servidor FTP”.
Aunque no he sido muy “fino” en mis palabras, creo que el ejemplo ilustra bastante bien, lo que he intentado explicar.
Tipos de Sockets
Existen variados tipos de Sockets como intentaré explicar de ahora en adelante, pero generalizando, los hay como direcciones DARPA de Internet(Internet Sockets), nombre de camino en un nodo local(UNIX Sockets), direcciones CCITT X25(X 25 Sockets “estos los puedes ignorar sin ningún complejo”) y muchos otros todo esto depende del tipo de ambiente UNIX que corras. Siendo más técnicos diremos que “Un Socket tiene una categoría y uno o más procesos asociados. Los Sockets son categorizados por las propiedades de comunicación que le son visibles al programador”. Usualmente la categoría del Socket esta asociada al protocolo en particular que lo soporta y los procesos, por lo general, comunican Sockets del mismo tipo. Debido a estas características podremos ponernos en contacto con cualquier punto de comunicación de cualquier computador conectado a la red.
Concluyamos algunos puntos:
Hasta aquí ha quedado claro que si quiero transmitir información deberé crear mi Socket para poder enviarla, luego el receptor también deberá crear su Socket para recepcionarla.
Los datos que identificarán unívocamente a los puntos de transmisión que he señalado anteriormente son los siguientes:
-
La dirección IP del computador en donde reside el programa que está usando este punto de conexión.
-
Un número de puerto. El puerto en un número entero de 16 bits, cuyo uso es el de permitir que en un ordenador puedan existir 65536 puntos posibles de comunicación para cada tipo de Socket. Esto es suficiente para que no suponga un límite, en la práctica, al número de puertos de comunicación diferentes que puede haber al mismo tiempo en un ordenador.
-
El tipo de Socket, dato que no reside en la información de direccionamiento, ya que es algo implícito al Socket. Si usamos un Socket de un tipo, éste sólo se comunicará con otro del mismo tipo. Para referirnos a un Socket, usamos una dirección de Socket. Las direcciones de Sockets son diferentes según la familia. Llevan todos un primer parámetro que identifica la familia del Socket y, luego, según ésta, los datos correspondientes.
Generalmente disponemos de tres tipos de Sockets para Internet y estos son:
-
Stream Socket - SPX
-
Datagram Socket - IPX
-
Raw Socket (No trabajaré con estos aunque haré alguna referencia de ellos)
Con esto no quiero enfatizarles que existen sólo estos, cómo les he explicado existen muchos más, pero no quiero hacer eterno este trabajo.
Los Raw Sockets dan acceso directo a la capa de software de red subyacente o a protocolos de más bajo nivel. Se utilizan sobre todo para la depuración del código de los protocolos. Los Raw Sockets proporcionan acceso al Internet Control Message Protocol, ICMP, y se utiliza para comunicarse entre varias entidades IP.
Stream Sockets y Datagram Sockets
Comenzaremos haciendo un comparendo entre estos dos tipos de Sockets para que puedan quedar más claras las diferencias. Los Stream Sockets son los más confiables y representan una forma del flujo de comunicación bidireccional. Si envías dos ítems de información en el orden “1 2”, se recibirá la información en el lado opuesto en el orden “1 2”. Por conclusión diremos que la comunicación se produjo libre de errores que es lo que esperamos que siempre ocurra. Este uso está muy arraigado en cualquier aplicación de Internet, ya que todos los caracteres que se tipeen necesitan llegar en ese mismo orden a su destino.
Los navegadores de Internet usan el protocolo HTTP, con los Stream Sockets para poder obtener las páginas. Si te conectas a un sitio mediante el puerto 80 y tipeas “Get nombre de página” el html de la página se mostrará ante ti.
Para obtener la calidad necesaria de alto nivel que esta transmisión de datos requiere, utilizan el famoso protocolo “TCP”(Transmission Control Protocol) o Protocolo de Control de Transmisión, es este TCP el que se asegura que los datos lleguen secuencialmente y libres de error, pero de darse el caso de que no se pudiera enviar la información quien haya hecho el intento recibirá la notificación correspondiente. Otra característica radica en que no hay límites en la extensión de los registros. No esta de más agregar que este protocolo es la media mitad del “IP”(Internet Protocol) o Protocolo de Internet, mas el IP se maneja con el enrutamiento en Internet solamente.
Bien, que hay de los Datagram Sockets. No tienen tan buena fama como sus pares Stream y esto por que el protocolo usado por estos es el “UDP”(User Datagram Protocol) o Protocolo de Usuario de Datagramas. Este método consiste en enviar paquetes de datos a un destino determinado. Cada paquete que enviemos ha de llevar la dirección de destino, y será guiado por la red independientemente. Estos paquetes con dirección incluida son lo que llamamos datagramas. Los datagramas tienen una longitud limitada, por lo que los datos a enviar no pueden traspasar esa longitud. Otros detalles provienen del hecho que se transite por una red de área extensa, o sea que al transitar por estas grandes extensiones se puede llegar a producir los siguientes acontecimientos:
-
Pérdida de Paquetes : En el nivel de red, en los nodos de enrutamiento se puede perder paquetes debido a la congestión, problemas en la transmisión, etc.
-
Orden de los Paquetes : Debido a la distancia los paquetes deben atravesar por varios nodos para llegar a su destino. En estos nodos, los algoritmos suelen no ser estáticos y esto se traduce en que un paquete puede seguir diferentes caminos en un mismo instante, debido a que el nodo lo decide así. Este cambio de rutas lo decide el nodo al posiblemente encontrar problemas de congestión por la sobrecarga en las líneas. Como conclusión tenemos que dos paquetes que fueron enviados pueden llegar desordenados al haber seguido rutas distintas.
Para terminar agregar que este tipo de conexión es conocido también como “Connectionless Sockets” o Sockets sin Conexión, debido principalmente a que no se necesita tener una conexión abierta permanentemente, sólo se crea el paquete se le dice al IP donde tiene que llegar y se envía.
Figura Sockets de Datagramas
Transmisión de Datagramas
En este punto se puede entrar en la duda de si no hay seguridad en el envío de los datagramas, ¿Para qué utilizar este método?
Bueno, esto se subsana de la siguiente manera, cada tipo tiene su propio protocolo en la parte más alta del “UDP”. Por ejemplo, el protocolo TFTP dice que “por cada paquete que lleve el sent(), el recipiente debe enviar de vuelta un paquete en respuesta que diga “lo tengo” (un paquete “ACK”). Si quien envía no obtiene respuesta, en digamos 5 segundos, el paquete será retransmitido hasta obtener la señal de “ACK” este procedimiento de reconocimiento es muy importante durante la implementación de las aplicaciones SOCK_DGRAM.
En la figura siguiente se ejemplifica mediante un dibujo lo que acabamos de explicar, que es la transmisión segura de Datagramas con la espera de la respuesta de la llegada del datagrama en forma satisfactoria. Lo sabemos por:
-
ACK (Acknowledge) : Recibido.
-
NACK(Not Acknowledge) : No Recibido.
-
EOT (End of Transmission) : Fin de Transmisión.
Figura de una Transmisión Segura de Datagramas
Datagrama 1
Perdido
Datagrama 2
Perdido
Datagrama 3
-
Los datagramas 1, 2 y 3 llevan los mismos datos, pero diferente información de control.
-
Datagrama respuesta lleva el asentimiento sobre si se ha recibido o no.
-
Para transmitir el dato con seguridad, enviamos un datagrama. Si luego de un tiempo no nos llega el asentimiento lo reenviamos. Así hasta recibir el asentimiento o demos el destino por inalcanzable luego de varios intentos.
¿Cómo Creo un Socket?
Bien, hemos llegado a la sustancia misma del trabajo y desde aquí en adelante las cosas pueden que se compliquen un poco así que trataremos de hacer lo que se requiere con la tranquilidad y claridad necesarias.
La creación básica de un Socket requiere de dos pasos:
-
Obtener el descriptor del Socket.
-
La dirección del Socket para la correspondiente parte del envío de la información.
Obtención del Descriptor(Paso1)
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Aquí especificaremos lo siguiente:
-
Domain(Dominio) : Es la familia de la cual proviene nuestro Socket, para las comunicaciones en Redes usaremos AF_INET. Pero puede ser AF_UNIX, o AF_OSI, etc.
-
Type(Tipo) : Tipo de Socket usado. Nos permite diferenciar la situación de uso de un SOCK_STREAM(orientado a conexión), de SOCK_DGRAM(para datagramas) o SOCK_RAW (nivel IP).
-
Protocol(Protocolo) : Generalmente, implementaremos uno por cada tipo de Socket. Siempre pondremos un 0, que dice que elegiremos el protocolo por defecto para el tipo y dominio de Socket elegido.
Con esto podremos obtener el descriptor del Socket, que será un entero. En caso de fracasar nuestro intento recibiremos un -1.
Un ejemplo de una llamada típica a un Socket(Tipo Datagramas):
Int sd;
if ((sd = socket(AF_INET, SOCK_DGRAM, 0) < 0) {
perror("socket");
exit(1);}
Dirección del Socket(Paso2)
Ya obtenido el Socket necesitamos poder usarlo para comunicarnos, para esto debe corresponderse con una dirección Socket. La estructura que sigue permite almacenar la dirección Socket como se usa en el dominio AF_INET:
struct in_addr {
u_long s_addr;
};
struct sockaddr_in {
u_short sin_family; /*identifica el protocolo; en general AF_INET */
u_short sin_port; /*numero de puerto. 0 deja que el kernel elija*/
struct in_addr sin_addr; /*la dirección IP. Con INADDR_ANY nos deja la opción de obtener el que queramos dentro del Host en que ejecutamos*/
char sin_zero[8];}; /*Sin usos, siempre cero */
Para poder usar la parte del programa anterior necesitarías agregar:
#include <netinet/in.h>
Hemos ahora de unirlo, esto se hace mediante la función Bind
#include <sys/types.h>
#include <sys/socket.h>
int bind(int sd, struct sockaddr *addr, int addrlen)
Donde tenemos que:
sd: Es el descriptor del archivo del Socket local, que se creó mediante la función Socket.
addr: Apunta a la dirección del protocolo de este Socket. Usualmente es INADDR_ANY .El puerto es 0 para solicitar al kernel que entregue un puerto.
addrlen: Longitud en bytes de una addr. Regresa un entero, el código es (0 Exitoso, -1 Falla)
Este comando Bind, es usado para especificarle al Socket el número del puerto donde esperará por los mensajes. He aquí una típica llamada a este comando:
struct sockaddr_in name;
bzero((char *) &name, sizeof(name)); /*longitudes*/
name.sin_family = AF_INET; /*usa dominio Internet*/
name.sin_port = htons(0); /*pide al kernel que le otorgue un puerto*/
name.sin_addr.s_addr = htonl(INADDR_ANY); /*usa todos los IPs del host*/
if (bind(sd, (struct sockaddr *)&name, sizeof(name)) < 0) {
perror("bind");
exit(1);}
Una llamada Bind es opcional por el lado del Cliente, pero necesaria por el lado Servidor.
Quisiera llamar la atención a ciertos comandos puestos en la estructura anterior que quizás no les hayan quedado muy claros, así que explicaremos las razones del uso de las llamadas htons y htonl.
Los números en máquinas diferentes pueden ser representados en forma diferente. Entonces necesitamos asegurarnos sobre la correcta presentación en el medio que trabajemos. Para eso transformamos mediante funciones desde el Host a un formato de Redes antes de transmitir(htons para enteros de tipo short, y htonl para enteros de tipo long), y desde la Red a un formato del Host después de la recepción(ntohs para enteros de tipo short, y ntohl para enteros de tipo long).
La función bzero está fuera de la longitud especificada para un buffer. Es de un grupo de funciones para manejarse con arreglos de bytes. bcopy copia un número especificado de bytes desde un buffer fuente a uno objetivo. Bcmp Compara un número especificado de bytes de dos buffers.
Una última aclaración aquí es que aunque tú le dejes la tarea de la elección del puerto al comando bind, o quieras elegirla por ti mismo esta deberá estar encima del 1024 ya que esos ya están reservados, pero no olvides que tienes hasta 65535 para elegir(siempre y cuando no estén siendo ocupados por otros procesos).
Opciones de Sockets y Trabajo con Datagramas
Bien, quiero empezar a trabajar con mi famoso Socket, o sea, requiero enviar datos, pero podría encontrarme con la novedad de que este se encuentre demasiado cargado o, lisa y llanamente, no sea capaz de contener mi mensaje. Podría suceder que al querer leer un dato no tenga ninguno disponible en ese preciso momento. Lo que, inevitablemente, ocurriría es que me quedaría bloqueado y esperando que la operación se pudiese llevar a cabo, si no deseo esperar tengo la opción de usar la función fcntl para poder cambiar el modo de funcionamiento del Socket. Lo que debería hacer es lo siguiente:
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd);
int fcntl(int fd, int cmd, long arg);
Recopilando, entonces, este comando fcntl puede ser usada para especificar que un proceso de grupo reciba una señal SIGURG cuando los datos arrojen una señal fuera del ancho de banda. Lo que implementamos fue también que fuera capaz de no bloquear I/O y la notificación asíncrona de eventos de I/O vía SIGIO. Esto asegura que al querer usar mi Socket y me quedase bloqueado, este me enviaría un mensaje de error EWOULDBLOCK, que significa que no realizará la operación debido a que se bloquearía.
Para concluir con esta parte, explicaremos lo último concerniente a los datagramas y luego terminaremos con la conexión Cliente /Servidor.
Datagramas
Para el correcto trabajo aquí como ya explicamos en párrafos anteriores hay que usar las funciones sendto() y recvfrom()
Los cuerpos son como siguen:
Sendto
Int sendto(int s, const void *msg, int len, unsigned int flags, cosnt struct sockaddr *to, int, tolen);
S : Descriptor del Socket.
Msg : Es el puntero a la zona de memoria con los datos.
Len : Representa la longitud de los datos.
Flags : Modificadores del modo de operación. Hay que poner un 0.
To : Es el puntero a la dirección de destino. Cuando usamos direcciones AF_INET(struct sockaddr_in) deberemos realizar un cast.
Tolen : Es el valor de retorno.
Acordarse de que el valor de retorno es el número de los bytes que se envió y que tendremos -1 si es que hubo algún error.
Recvfrom
Int recvfrom(int s, void*buf, int lon, unsigned int flags, struct sockaddr *from, int *lonfrom);
S : Es el descriptor del Socket.
Buf : Zona de memoria donde queremos almacenar los datos recibidos.
Lon : Longitud del mensaje que queremos recibir.
Flags :Modificador del modo de operación. Usaremos un 0 desde el puntero hasta la variable donde queremos almacenar la dirección del origen de los datos. La utilidad de esto radica en que es necesario saberlo cuando queremos responder y necesitamos la dirección para mandar la respuesta.. Si usamos direcciones AF_INET(struct sockaddr_in), realizaremos un cast. Si from vale NULL no se escribirá nada en él.
Lonfrom : Es desde el puntero a un entero donde se nos escribirá la longitud del dato dirección.
La llamada sendto sirve para enviar datos. Si el tamaño de los datos que queremos enviar es demasiado grande, la función nos retornará un error, por lo que la variable errno será puesta al valor emsgsize. Los errores que se nos indicarán serán errores locales, como el excedernos en el ancho, algún parametro ingresado incorrectamente, etc. Si ocurre un error de comunicaciones, el paquete puede perderse en la red, y eso es algo que nosotros no sabremos. Ahora para tratar de evitar esto es que trataremos de pedir el asentimiento. Si el Socket está demasiado cargado y no tiene espacio para almacenar nuestro mensaje se producirá lo que ya comentamos, se bloqueará la llamada y ya sabemos lo que hay que hacer para que no se nos bloquee.
Para recibir datos usamos la llamada recvfrom. El funcionamiento es análogo al de sendto y cuando no haya datos se bloqueará solo, a no ser que nuestro Socket sea no bloqueante. Cuando haya datos disponibles, lo que es por defecto, dará como resultado todos los datos que tenga hasta el solicitado. O sea, que si hay 400 bytes y hemos solicitado 800 recibiremos los 400.
III Parte. Sockets Orientados a Conexión.
Los Sockets orientados a conexión se utilizan de modo muy diferente a los Sockets de Datagramas. Obedecen a una arquitectura Cliente/Servidor. Por consiguiente, habrá un extremo de la comunicación que actuará como servidor, en el que se esperarán las peticiones de conexión, y otro extremo que solicitará la realización de las comunicaciones desempeñando el rol del cliente.
Figura Relación Cliente Servidor
El Servidor
Muy bien ahora comienzas a querer conectarte a un servidor remoto para comenzar a recibir información y poder manejarla. El proceso servidor ha de crear un Socket y enlazar la dirección, algo que me imagino en este punto ya debe resultar más que obvio, debes sin embargo cambiar el tipo, o sea, ahora debemos poner SOCK_STREAM.
Los pasos para poder hacer lo que se pretende son dos y muy claros: Primero debes escuchar y luego aceptar las conexiones.
Ok, el cuerpo para poder realizar estas acciones es el que sigue:
Función Listen()
int listen(int sockfd, int backlog);
sockfd : Es el descriptor de archivo Socket usual.
Backlog : Es el número de conexiones permitidas en la fila entrante.
Ahora que significa que estén en cola, pues bien todas las conexiones entrantes van a esperar en esta fila hasta que tú aceptes. Ahora ¿Cómo saber el número de conexiones entrantes?, Bueno la mayoría de los sistemas silenciosamente limita este número a cerca de 20, probablemente puedas manejarte mejor con un número entre 5 a 10. Lo importante aquí es que cuando alcancemos ese número máximo las otras conexiones pendientes serán rechazadas.
Posiblemente ya te hayas imaginado que necesitamos realizar la llamada bind() antes de llamar a listen(), pues de lo contrario el Kernel nos tendrá escuchando en puertos al azar. Por lo tanto esta debe ser la secuencia que debes tener en mente para no pasarte la vida entera escuchando.
socket();
bind();
listen();
/* accept() esta llamada va aquí*/
Función Accept()
Esta llamada es algo extraña y te lo dirán en cada manual que leas, pero trataré de explicarlo lo más claro posible. ¿Qué sucede si alguien muy a lo lejos intentara una conexión contigo en el puerto en el cual tú estás escuchando?. Esta llamada quedará en cola hasta que tú aceptes. Ok, tú aceptas mediante accept() y este se encarga de confirmar lo que tú quieres, aquí se te regresa un nuevo descriptor de archivo Socket, repentinamente tiene que manejar 2 Sockets por el mismo precio. El original que siguen escuchando en tu puerto y el nuevo que esta finalmente listo para un send() y un recv(). Veamos esto en código:
La llamada es como sigue:
#include <sys/socket.h>
int accept(int sockfd, void *addr, int *addrlen);
sockfd : Este es el descriptor del Socket que escucha.
addr : Será usualmente un puntero a un struct sockaddr_in. local. Esto es donde la información sobre la conexión entrante se almacenará. (Y poder determinar que Host te llama y de qué puerto lo hace).
addrlen : Es un entero que establece el tamaño de sizeof(struct sockaddr_in) antes de que la dirección sea pasada a accept().Por lo tanto, la llamada accept no colocará más que estos bytes dentro de addr. Si colocara menos cambiaría el valor de addrlen lo que reflejaría que accept() regresó un -1 o sea un error.
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#define MYPORT 3490 /* Puerto al que se conectarán */
#define BACKLOG 10 /* cuantas conexiones pendientes se mantendrán en cola */
main()
{
int sockfd, new_fd; /* Escucha en sock_fd, la nueva en new_fd */
struct sockaddr_in my_addr; /* Mi información de dirección*/
struct sockaddr_in their_addr; /* Información de dirección de quien se conecta*/
int sin_size;
sockfd = socket(AF_INET, SOCK_STREAM, 0); /* Checa errores */
my_addr.sin_family = AF_INET; /* orden de bytes del Host*/
my_addr.sin_port = htons(MYPORT); /* tipo short, Orden en bytes de la red */
my_addr.sin_addr.s_addr = INADDR_ANY; /* Auto completa con mi IP */
bzero(&(my_addr.sin_zero), 8); /* zero resto de struct*/
/* no hay que olvidar chequeo de errores para estas llamadas*/
bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr));
listen(sockfd, BACKLOG);
sin_size = sizeof(struct sockaddr_in);
new_fd = accept(sockfd, &their_addr, &sin_size);
Notar que se usa el descriptor socketnew_fd para todos los send() y recv(). Si sólo se obtiene una conexión, se puede cerrar close() el sockfd original para prevenir la llegada de nuevas conexiones al mismo puerto, claro si es que esto se desea.
Otro aspecto interesante aquí es que como ya se sabe, el nuevo descriptor de Socket tiene las mismas características que el nuestro(para poder realizar la conexión). Ahora sabemos que a través de nuestro Socket podemos establecer varias conexiones con distintos orígenes y realizamos las conexiones pertinentes con el descriptor devuelto en cada caso. Esto se puede ejemplificar con los “demonios servidores”. Cuya misión consiste en estar escuchando en el Socket y aceptar conexiones con accepts. Cuando reciben una petición, guardan el descriptor del Socket devuelto y hacen un nuevo proceso hijo. Es este hijo quien se encarga de las comunicaciones, y de paso permite al padre seguir esperando nuevas conexiones.
Figura
Funcionamiento de un servidor atendiendo varias conexiones en paralelo
Creación de una conexión Situación en un momento dado
1 Proceso Padre escuchando
3 4
5
1.- Cliente pide conexión.
2.- Servidor atiende conexión por
3.- Se crea la conexión
4.- El servidor hace un hijo y sigue escuchando
5.- El hijo hereda la comunicación del padre y se comunica con el cliente.
El Cliente
El cliente ha de seguir los pasos de siempre al crear un Socket AF_INET y SOCK_STREAM, y luego enlazarlo a una dirección. En esto debe cumplimentar los datos de la dirección del servidor al que se quiere conectar y pedir establecer la conexión. Esto último se hace con la función Connect.
Función Connect()
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, struct sockaddr *serv_addr, int addrlen);
sockfd Es el descriptor del socket.
serv_addr Es una struct sockaddr que contiene el puerto de destino y la dirección IP.
addrlen Establece la longitud de la dirección (struct sockaddr).
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#define DEST_IP "132.241.5.10"
#define DEST_PORT 23
main()
int sockfd;
struct sockaddr_in dest_addr; /* Mantendrá la dirección de destino*/
sockfd = socket(AF_INET, SOCK_STREAM, 0); /*Chequeo de errores*/
dest_addr.sin_family = AF_INET; /* orden de bytes del host */
dest_addr.sin_port = htons(DEST_PORT); /* tipo short, orden de bytes de la red*/
dest_addr.sin_addr.s_addr = inet_addr(DEST_IP);
bzero(&(dest_addr.sin_zero), 8); /* zero el resto de struct */
/* Chequeo de errores para connect()! */
connect(sockfd, (struct sockaddr *)&dest_addr, sizeof(struct sockaddr));
Como ya se sabe si algo falla tendremos de vuelta un -1. También notar que no llamamos a bind(), esto básicamente por que no nos importa nuestro número de puerto local, sólo nos interesa hacia dónde vamos. El Kernel elegirá un puerto local para nosotros y el sitio al que nos conectemos automáticamente obtendrá esta información.
Funciones Close() y Shutdown()
Bueno supongo que ya has estado recibiendo y mandando información todo el día y ya es hora de terminar esta agotadora jornada. ¿Qué hacemos ahora?. Bueno eso resulta obvio cerramos y apagamos. Lo primero es muy fácil usamos el descriptor de archivo de Unix close():
close(sockfd);
Esto previene de hacer próximos reads y writes al Socket. Además cualquiera que intente un read o write al Socket desde el otro terminal recibirá un error.
Sólo en caso de que quieras más control sobre el cierre del Socket, puedes usar la función Shutdown(). Que te permite cortar la comunicación en una cierta dirección o en ambas direcciones.
int shutdown(int sockfd, int how);
sockfd : Es el descriptor de archivo que tú deseas cerrar.
Int how : Entero que realiza la acción.
Ahora, las acciones son:
-
0 - No se permiten próximos recibos.
-
1 - No se permiten próximos envíos
-
2 - No se permiten próximos envíos, ni recibos.
Shutdown() regresa un -1, en caso de error.
Función getpeername()
Básicamente es esta función quien te dice quién se encuentra el final de la línea.
#include <sys/socket.h>
int getpeername(int sockfd, struct sockaddr *addr, int *addrlen);
sockfd Es el descriptor de archivo.
addr Es el puntero a sockaddr (o a struct sockaddr_in) que almacenará la información sobre el otro lado de la conexión.
addrlen Es un puntero a int, que otorga la longitud(struct sockaddr).
Esta función como todas, regresa un -1 si hubo un error.
Función gethostname()
Regresa el nombre del computador donde se está corriendo el programa. Luego se puede usar gethostbyname(), para determinar la IP de tu máquina local.
#include <unistd.h>
int gethostname(char *hostname, size_t size);
hostname Es un puntero a un arreglo de caracteres que contendrán el nombre del Host.
size Es la longitud en bytes del arreglo del Host.
La Función regresa como todas la vistas un 0 si hubo éxito y -1 si fracasó
Ultimos Puntos a Tener en Cuenta
Para ya ir terminando, sólo nos resta tocar unos cuantos puntos que pueden ser muy necesarios a la hora de poder enfrentarnos con imprevistos y el primero a tener en cuenta es la señal “SIGPIPE”. Como se mencionó, al establecer una conexión, aunque nosotros no estemos enviando datos se transmiten paquetes cada cierto tiempo para verificar que la conexión sigue establecida. Con ello, el protocolo puede detectar que una conexión fue rota, debido a un fallo en la red, en el programa remoto al que nos conectamos, etc. Cuando esto suceda, si intentamos enviar datos por esa conexión rota, nuestro proceso recibirá una señal, SIGPIPE. El problema radica acá es que si no capturamos esta señal el comportamiento por defecto es terminar el programa. Por esto si queremos evitarnos que se nos caiga a cada rato nuestra conexión debemos tomar las medidas para reaccionar ante estas eventualidades, o sea, hay que capturar esta señal.
Estas señales son una especie de interrupciones de software. Un proceso puede recibir una señal en cualquier momento de su ejecución y pasar inmediatamente a atenderla. Cuando un proceso recibe una señal, según cual sea, se ejecutará un manejador, o sea, una función que realizará las acciones oportunas. Este proceso podría ser escrito por uno mismo, salvo en los casos de señales como SIGKILL y SIGSTOP, cuya recepción implica que el proceso se termine o pare.
Hay dos casos en los que es recomendable hacerlo siempre:
-
Cuando hagamos hijos que nos envíen la señal SIGCHLD para, por lo menos, matarlos y además realizar las operaciones oportunas de nuestro programa.
-
Cuando usemos flujos de comunicaciones, como Sockets orientados a conexión, debemos entonces obtener la señal para impedir una caída abrupta del programa.
Para poder capturar esta señal usamos la función signal()
Typedef void (*sighandler_t)(int);
Void signal(int signal, sighandler_t handler);
Por lo que para capturar la señal SIGCHLD haríamos:
#include<signal.h>
void hijos(int signal) {
…..
código nuestro para cuando se reciba la señal
signal(SIGCHLD, hijos); /* Es preciso restablecer nuestro manejador cada vez que se captura la señal*/
}
main(){
….
signal(SIGCHLD, hijos);
…
}
Cuando el programa recibe una señal y está ejecutándose una llamada al sistema, ésta se interrumpirá debido a que las llamadas al sistema han de realizarse en forma indivisible. Existe, no obstante, la posibilidad de modificar la forma de comportamiento de las señales para que cuando interrumpan una llamada al sistema ésta se reinicie automáticamente. También es posible ignorar algunas señales. Esto se logra con las funciones SIGACTION y SIGPROCMASK.
Señales más Importantes
-
SIGKILL No se puede capturar ni ignorar y el proceso muere al recibirla.
-
SIGTERM El comportamiento por defecto es morir, pero se puede capturar o ignorar.
-
SIGPIPE Canal de comunicaciones roto(sin lectores).
-
SIGALARM Señal programable.
-
SIGCHLD Terminación de un hijo.
-
SIGSTOP Parar la ejecución del programa. No es capturable, ni ignorable.
-
SIGCONT Continuar con la ejecución del programa si estaba parado.
Temporizaciones
Concluyendo ya el trabajo sólo resta hacer notar que esto se produce por las llamadas bloqueantes al sistema, y que nos mantienen suspendidos por un tiempo indefinido hasta que ocurra algo que nos permita salir del bloqueo(como que lleguen datos). Pero se puede dar el caso que necesitemos esperar a que llegue un dato por un tiempo limitado, y si no llegase, realizar una acción alternativa. Para esto usamos la función select(). Esta función trabaja con tres conjuntos de descriptores:
-
Descriptores en los que esperamos aparezcan datos para leer.
-
Descriptores en los que esperamos sea posible escribir datos.
-
Descriptores para posibles excepciones.
También durante esta espera se le pasará un puntero a un dato con el tiempo que queremos esperar, pudiendo esperar indefinidamente si en vez de pasar el puntero al parámetro temporal pasamos el valor NULL.
EL valor devuelto por select() es el número de descriptores que hay en los conjuntos si hubo algún cambio de estado en ellos. Devuelve 0 si expiró la temporización y -1 si sucedió algún error.
Estos descriptores se almacenan en unos structs de tipo fd_set. Para manejarlos existen unas macros que sirven para borrar todos los descriptores del conjunto, para añadir o quitar descriptores y para saber si un descriptor pertenece al conjunto. Esta funcionalidad puede resultar útil, pero hay que tener en cuenta que en otros sistemas UNIX select() no está implementado de esta forma. Así que, en caso de interesar la portabilidad del código de la aplicación hay que tener es cuenta esto.
También es posible que sea útil emplear la función select() aunque no queramos realizar temporizaciones. Si, por ejemplo, estamos esperando datos por más de un sitio(varios Sockets o un Socket y un pipe) podemos usar la función select() para esperar a tener datos disponibles por cualquiera de ellos. Si nos quedásemos escuchando por uno, al llegar datos por otro no nos enteraríamos y por consiguiente no podríamos atender la petición.
Función Select()
Int select(int n, fd_set *readfds, fd_set * writefds, fd_set * exceptfds, struct timeval * timeout);
N : Es el número de descriptores de ficheros más alto de los conjuntos más 1.
Readfds : Es el conjunto de descriptores para lectura.
Writefds : Es el conjunto de descriptores de escritura.
Exceptfds : Es el conjunto para ver si ocurren excepciones.
Timeout : Contiene el máximo tiempo que se esperará a que ocurra algo.
Struct timeval{
Int tv_usev; //Microsegundos
Int tv_sec; //segundos
}
FD_ZERO(fd_set *set); // Deja vacío el conjunto apuntado por set.
FD_SET(int fd, fd_set *set); // Añade el descriptor fd al conjunto.
FD_CLR(int fd, fd_set *set); // Quita el descriptor fd del conjunto.
FD_ISSET(int fd, fd_set *set); // Indica si el descriptor fd pertenece al conjunto.
Unos programas de Sockets
Bueno he hablado n de esto así que finalizaré este trabajo con un par de programas que hacen de cliente y servidor. No los escribí yo, sino que son sacados de aquí http://www.ecst.csuchico.edu/~beej/guide/net. Me ahorré la pega.
Todo lo que este servidor hace es enviar la cadena “Hello World!", Sobre una conexión Stream. Sólo se necesita para testear este servidor, correrlo en una ventana para comunicarte a él desde otra con:
$ telnet remotehostname 3490
Donde remotehostname es el nombre de la máquina donde estás corriendo
Servidor
/*
** server.c -- a stream socket server demo
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#define MYPORT 3490 /* the port users will be connecting to */
#define BACKLOG 10 /* how many pending connections queue will hold */
main()
{
int sockfd, new_fd; /* listen on sock_fd, new connection on new_fd */
struct sockaddr_in my_addr; /* my address information */
struct sockaddr_in their_addr; /* connector's address information */
int sin_size;
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
perror("socket");
exit(1);
}
my_addr.sin_family = AF_INET; /* host byte order */
my_addr.sin_port = htons(MYPORT); /* short, network byte order */
my_addr.sin_addr.s_addr = INADDR_ANY; /* automatically fill with my IP */
bzero(&(my_addr.sin_zero), 8); /* zero the rest of the struct */
if (bind(sockfd, (struct sockaddr *)&my_addr, sizeof(struct sockaddr)) == -1) {
perror("bind");
exit(1);
}
if (listen(sockfd, BACKLOG) == -1) {
perror("listen");
exit(1);
}
while(1) { /* main accept() loop */
sin_size = sizeof(struct sockaddr_in);
if ((new_fd = accept(sockfd, (struct sockaddr *)&their_addr, &sin_size)) == -1) {
perror("accept");
continue;
}
printf("server: got connection from %s\n",inet_ntoa(their_addr.sin_addr));
if (!fork()) { /* this is the child process */
if (send(new_fd, "Hello, world!\n", 14, 0) == -1)
perror("send");
close(new_fd);
exit(0);
}
close(new_fd); /* parent doesn't need this */
while(waitpid(-1,NULL,WNOHANG) > 0); /* clean up all child processes */
}
}
Programa Cliente
Este es mucho más fácil que el anterior. Todo lo que hace es conectarse al host que específicas en la línea de comando, puerto 3490. Luego obtiene la cadena que el servidor le envía.
/*
** client.c -- a stream socket client demo
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#define PORT 3490 /* the port client will be connecting to */
#define MAXDATASIZE 100 /* max number of bytes we can get at once */
int main(int argc, char *argv[])
{
int sockfd, numbytes;
char buf[MAXDATASIZE];
struct hostent *he;
struct sockaddr_in their_addr; /* connector's address information */
if (argc != 2) {
fprintf(stderr,"usage: client hostname\n");
exit(1);
}
if ((he=gethostbyname(argv[1])) == NULL) { /* get the host info */
perror("gethostbyname");
exit(1);
}
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1) {
perror("socket");
exit(1);
}
their_addr.sin_family = AF_INET; /* host byte order */
their_addr.sin_port = htons(PORT); /* short, network byte order */
their_addr.sin_addr = *((struct in_addr *)he->h_addr);
bzero(&(their_addr.sin_zero), 8); /* zero the rest of the struct */
if (connect(sockfd, (struct sockaddr *)&their_addr, sizeof(struct sockaddr)) == -1) {
perror("connect");
exit(1);
}
if ((numbytes=recv(sockfd, buf, MAXDATASIZE, 0)) == -1) {
perror("recv");
exit(1);
}
buf[numbytes] = '\0';
printf("Received: %s",buf);
close(sockfd);
return 0;
}
Conclusiones
Al término de este trabajo. Que en realidad resultó mucho más largo de lo que presupuesté. Me he encontrado con varias cosas que nunca manejé a cabalidad y las definiciones y demases intenté, por esto mismo, hacerlas lo más claras posibles ya que no sólo yo quién necesitará echar mano de este trabajo, sino que varios más se verán en la obligación de tirar las manos a este trabajo que les será de gran ayuda.
En general podemos concluir que es posible poder construir nosotros mismos los programas que se nos permitan comunicarnos con otros programas y poder mandarles información. La forma de realizar esto es mediante los Sockets.
Los Sockets concluimos que son una abstracción para poder definir el punto final de una comunicación entre interprocesos bidireccionales. Los Sockets son de varios tipos y dependiendo del uso que les queramos dar optaremos por cada uno de ellos.
Los Sockets sólo pueden comunicarse con Sockets de su mismo tipo y familia, por lo que debemos tener muy claro esto a la hora de querer codificar una transmisión.
A través de nuestros Sockets podemos establecer varias conexiones, pues a partir de un padre el servidor es capaz de crear un hijo, que se encargará de enlazar la información, dejando al padre en su tarea de escuchar.
Las señales y temporizaciones son un factor a tener en cuenta. Pero tenemos herramientas para poder interactuar con ellas y poder establecer nuestros criterios a la hora de su manejo.
No quiero concluir este trabajo sin mencionar que en verdad este tema me tuvo muy apasionado, durante unas buenas semanas( me gustó casi tanto como ver Serial Experiments Lain).
Bibliografía
-
Revista Linux Actual, Año 1 Número 9. Tema “Programación de Sockets(I)”, páginas 52 a 55.
-
Revista Linux Actual, Año 2 Número 10. Tema “Programación de Sockets(II)”, páginas 53 a 55.
-
Primer on Sockets by Jim Frost (Software Tool & Die)
-
Introductory tutorial on IPC in 4.4BSD-Unix (by S.Sechrest UC-Berkeley) (Postscript)
-
Advanced tutorial on IPC in 4.4BSD-Unix (by S.Leffler, R.Fabry, W.Joy, P.Lampsey UC-Berkeley, S.Miller, C.Torek U-Maryland) (Postscript)
-
Unix-faq/socket, URL: http://www.ibrado.com/sock-faq/
Programming UNIX Sockets in C - Frequently Asked Questions Created by Vic Metcalfe, Andrew Gierth and other contributers, January 22, 1998
-
Unix- Sockets F.A.Q.
http://packetstorm.securify.com/programming-tutorials/Sockets/unix-socket-faq.html#toc2
-
Microsoft Visual Basic 6.0. Fundamentals.
-
Tutorial de Java.
http://members.es.tripod.de/froufe/index.html
-
Sockets. Programa en Visual Basic 5.0.
http://guille.costasol.net/colabora.htm
-
Beej's Guide to Network Programming Using Internet Sockets
Version 1.5.5 (13-Jan-1999)
http://www.ecst.csuchico.edu/~beej/guide/net
-
BDS Sockets : A Quick and Dirty Primer
http://www.cs.umn.edu/~bentlema/unix/
Cliente
Proceso
Hijo
Cliente
Proceso
Hijo
Proceso
Hijo
Cliente
Proceso
Hijo
2Servidor
Cliente
Clien
Servidor
Entrega de
Información
Servidor
Cliente
Solicitud de
Información
Mensaje
Recibido
Socket
Socket
W
A
N
Proceso A
Proceso B
Datagram
Socket
Datagram
Socket
W
A
N
Datagram
Socket
Datagram
Socket
Descargar
| Enviado por: | Ivar León Espinoza |
| Idioma: | castellano |
| País: | Chile |
Todos los derechos reservados.