Geología, Topografía y Minas
Filtro de Kalman
EL FILTRO DE KALMAN:
Facultad de Ingeniería Civil - Universidad Nacional de Ingeniería
LIMA-PERÚ
Desde su introducción en 1,960 el Filtro Kalman ha llegado a ser un componente integral dentro de miles de Sistemas de navegación tanto militares como civiles. Este algoritmo digital recursivo aparentemente simple, ha sido el favorito desde antes para integrar convenientemente (o fusionar) los datos de los sensores de navegación para alcanzar un rendimiento óptimo de todo el sistema. Para proveer estimados corrientes de las variables del sistema tales como coordenadas de posición el filtro usa modelos estadísticos para ponderar apropiadamente cada una de las mediciones nuevas relativas a la información pasada. También determinar incertidumbres actualizadas de los estimados, para evaluaciones cualitativas en tiempo real ó para estudios de los sistemas de cálculos no convencionales. A causa de que éste da un óptimo rendimiento, versatilidad y fácil implementación, el Filtro Kalman ha sido popular especialmente en los GPS.
En ésta columna del mes, Larry Levy nos va a introducir en lo que respecta al Filtro Kalman y nos dará una explicación breve sobre su aplicación en la navegación en GPS.
El doctor Levy es el científico principal (investigador) del Departamento de Sistemas Estratégicos de la Universidad John Hopkins del laboratorio de Física Aplicada. El recibió su doctorado en Ingeniería Electrica en la Universidad del Estado de Iowa en 1,971. Levy ha trabajado en la aplicación del Filtro Kalman por más de 30 años, ha ayudado a desarrollar el concepto del traductor GPS en SATRACK (un GPS basado en un sistema de seguimiento de misiles), y fue un instrumento importantísimo en el desarrollo de la metodología de Fin a Fin, para evaluar la precisión del TRIDENT II. El conduce los cursos para graduados sobre el Filtro Kalman y la justificación del sistema en la universidad John Hopkins, de la facultad Whiting de ingeniería, además enseña un seminario corto de NAVTECH sobre el Filtro Kalman.
Innovación es una columna regular que discute acerca de los avances más recientes de la tecnología en GPS y sus aplicaciones, así como también, el posicionamiento fundamental del GPS. La columna es coordinada por Richard Langley del Departamento de Geodesia y de Ingeniería Geomática de la Universidad New Brunswick, quien apreciará recibir sus comentarios así como también tópicos de sugerencia para una futura columna. Para contactarse con él, vea la sección el columnista, en la página 4 de éste reporte.
Cuando Rodolfo Kalman introdujo formalmente el Filtro Kalman en 1960, el algoritmo fue bien recibido : La computadora digital ya había progresado lo suficiente y existían muchas necesidades importantes (por ejemplo la navegación inercial asistida por operadores) y el algoritmo fue aparentemente sencillo dentro de su forma.
Los ingenieros reconocieron pronto, sin embargo, pensaron que la aplicación práctica del algoritmo iba a requerir una atención cuidadosa a los modelos estadísticos adecuados y precisión numérica. Con éstas consideraciones por delante, ellos desarrollaron subsecuentemente miles de maneras de usar el Filtro ya sea en la navegación, topografía, vehículos de transporte (aviones, naves espaciales, misiles), geología, oceanografía, Dinámica de fluidos, industrias del Acero/Papel/Energía y estimación demográfica, por mencionar unas pocas, de las miles de áreas de su aplicación.
Nosotros los humanos hemos estado filtrándo las cosas a travez de nuestra historia. La filtración de agua es un ejemplo simple, podemos filtrar las impurezas del agua tan simplemente como usando nuestras manos para desechar la suciedad como las hojas que esten en la superficie del agua. Otro ejemplo está al filtrar el ruido de nuestros ambientes, si prestáramos la atención a todos los ruidos pequeños alrededor de nosotros entonces nos volveríamos locos. Nosotros aprendemos a ignorar los sonidos superfluos (el tráfico, etc.) y por ejemplo nos enfocamos en los sonidos importantes, como la voz de la persona cuando estamos hablando con alguien.
Hay también muchos ejemplos donde el diseño de un filtro es deseable. Los signos de comunicaciones de radio están a menudo corrompidos con el ruido. Un algoritmo de la filtración bueno puede quitar el ruido de los signos electromagnéticos mientras todavía esta reteniendo la información útil. Otro ejemplo es los voltajes. Muchos países requieren en-casa que se filtra de voltajes de la línea para impulsar computadoras personales y periféricos. Sin filtrarse, las fluctuaciones de poder acortarían la vida útil de los dispositivos en forma drástica.
El filtro de Kalman es relativamente reciente (1960) el desarrollo del filtro aunque recupera sus raíces como lejano, Gauss (1795). el filtro de Kalman ha sido aplicado en las diversas areas como la navegación aerospacial, marina, la instrumentación de planta de poder nuclear, planeamiento demográfico, la fabricacion, y muchos otras aplicaciones.
El propósito de un filtro de Kalman es estimar el estado de un sistema de medidas que contiene los errores del azar. Un ejemplo está estimando la posición y velocidad de un satelite de los datos del radar. Hay así 3 componentes de posición y 3 de velocidad, hay 6 variables por lo menos para estimar. Estas variables se llaman las variables estatales. Con 6 variables de estado el filtro de Kalman resultante se llama un filtro de Kalman de 6 dimensiones.
En esta introducción, nosotros empezaremos con un problema mucho más simple. Nosotros empezaremos con un filtro Kalman de una dimension. En otros términos asumiremos que nosotros tenemos sólo una constante a estimar.
DESCRIPCION DE LA ECUACION LIBRE.
El filtro Kalman es un filtro digital de emisión y recepción múltiple que puede estimar en forma óptima, en tiempo real, los estados de un sistema basados en la salida del ruido (ver figura 1).
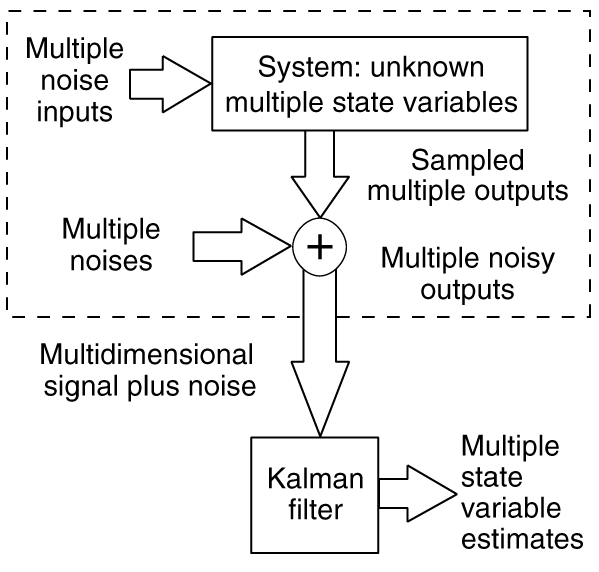
Figura 1. El propósito de un filtro de Kalman es estimar los valores de variables que describen el estado de un sistema de un signo multidimensional contaminados por el ruido óptimamente.
Estos estados son todas las variables que necesita para describir completamente el comportamiento del sistema como una función del tiempo (tales como posición, velocidad, niveles de voltaje y salidas). En efecto, uno puede pensar en emisiones múltiples ruidosas, como una señal multidimensional más el ruido, con los estados del sistema que son las señales desconocidas deseadas.
El filtro Kalman, filtra el ruido midiendo la estimación de las señales deseadas. Las estimaciones son estadísticamente óptimas en el sentido que ellos minimizan la estimación del error medio cuadrático. Esto ha sido visto desde o por un criterio muy general dentro de muchos otros criterios razonables (el intervalo de cualquier incremento monótono, función del error simétrico tal como el valor absoluto) pudiendo devolver el mismo estimado. El filtro Kalman tuvo un perfeccionamiento dramático sobre su predecesor el error medio cuadrático mínimo inventado por Norbert Wienner en los años 40, el cual fue limitado primeramente a señales escalares dentro de ruidos con estadísticas estacionarias.
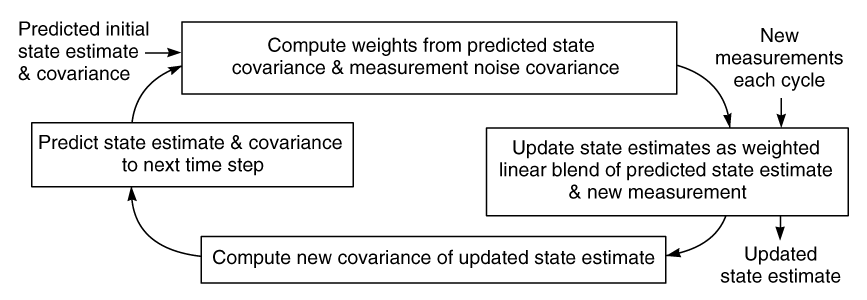
Figura 2 - El filtro Kalman es recursivo, es un filtro lineal. En cada ciclo, el estado estimado es actualizado por nuevas medidas combinadas con los estimados del estado predecidos de medidas previas.
En la figura 2, ilustra el algoritmo del filtro Kalman. Porque el estado (o señal) es un vector escalar de variables fortuitas (contrario a una variable simple), el estimado del estado de la incertidumbre es una matriz de varianza y covarianza o simplemente una matriz de covarianza. Cada termino de la diagonal de la matriz es la transformación de una variable escalar escogida al azar - una descripción de su incertidumbre. El término es la desviación de las variables del medio cuadrático, proveniente del intervalo y el origen del su intervalo es su desviación standart. Los términos de la matriz fuera de su diagonal son las covarianzas que describen cualquier correlación entre pares de variables.
Las medidas múltiples (cada punto en un tiempo) son también vectores que tienen un algoritmo recursivo de un proceso secuencial dentro de un tiempo. Esto intervalo que repite el algoritmo iterativo de sí mismo para cada medida nueva del vector, usando solo valores copiados provenientes de un ciclo previo (o anterior). Este procedimiento se distingue de algoritmos de procesamiento por partes el cual debe guardar todas las mediciones anteriores.
Comenzando con un estado estimado predecido (como se ve en la figura 2) y su covarianza asociada obtenida de una información anterior o pasada, el filtro calcula los pesos (ponderaciones) que van a ser usados; cuando se combine esta estimado con la primera medida del vector se obtiene un dato actualizado o mejor estimado. Si la medida de la covarianza del ruido es mucho mejor que lo que predijo la estimación del estado, los pesos de las medidas van a ser mas altos y la estimación del estado mas bajo.
Así mismo, el ponderado relativo entre los estados escalares serán una función de cuan "notables" son estas en las mediciones. Los estados que pueden verse rápidamente en las mediciones recibirán los pesos más altos. Porque el filtro calcula una estimación del estado actualizado usando la nueva medida, la covarianza estimada debe estar cambiada para reflejar la información que acaba de añadirse, resultando una reducción de la incertidumbre. Las estimaciones del estado actualizado y sus covarianzas asociadas forman las emisiones del Filtro Kalman.
Finalmente, para prepararse para la siguiente medición del vector, el filtro debe proyectar la estimación del estado actualizado y su covarianza asociada al tiempo de la siguiente medición. El sistema real del vector del estado se asume que cambia con tiempo de acuerdo a una transformación lineal determinante más un ruido fortuito independiente. Por consiguiente, la estimación del estado predecido sigue solamente una transformación determinada, porque el valor del ruido real es desconocido. La predicción de la covarianza da cuenta de ambos, puesto que la incertidumbre de los ruidos fortuitos son conocidos. Por consiguiente, la incertidumbre de la predicción aumentará, puesto que la predicción de la estimación del estado no puede dar cuenta del ruido fortuito adicionado. Este último paso completa el ciclo del filtro de Kalman.
QUE DIJO GAUSS
Si las observaciones astronómicas y otras magnitudes están basadas en el cálculo de las órbitas, siendo absolutamente correctas y los elementos también, ya sean los deducidos a partir de tres o cuatro observaciones, serian estrictamente precisos (en realidad hasta donde se supone que el movimiento ha tenido lugar exactamente según las leyes de Kepler), y, por consiguiente, si se usaran otras observaciones, ellas podrían confirmarse, pero no corregirse. Pero si todas nuestras medidas y observaciones no fueran más que aproximaciones a la verdad, estas deben ser verdad con respecto a todos los cálculos en que ellas se basan; y el objetivo principal de todos los cálculos hechos relacionados al fenómeno en concreto deben ser solo aproximaciones, tan cerca como sea factible a la verdad. Pero esto puede obtenerse, no de otra manera que combinando convenientemente de más observaciones que el número que se requieren absolutamente para la determinación de las cantidades desconocidas. Este problema puede ser solucionado apropiadamente solo cuando se haya obtenido un conocimiento aproximado de la órbita, qué después será corregido para satisfacer todas las observaciones de la manera más precisa posible.
Uno puede observar que como los vectores medidos son procesos recursivos, la incertidumbre de los estimación del estado generalmente debe disminuir (si todos los estados son notables) debido a la información acumulada de las medidas. Sin embargo, algunas veces porque la información se perdió (o la incertidumbre aumenta) en el paso predecido, la incertidumbre alcanzará un estado fijo o constante. Cuando la magnitud de la incertidumbre incrementa en el paso predecido, esta es equilibrada por la disminución de la incertidumbre en el paso actualizado. Si no existe ruido aleatorio en el modelo real cuando el estado evoluciona hacia la proxima etapa entonces la incertidumbre va a aproximarse con el tiempo a cero. Debido a que la incertidumbre de la estimación del estado varía con el tiempo, lo mismo sucederá con los pesos. Generalmente hablando, el filtro de Kalman es un filtro digital con incrementos de variación en el tiempo. Los lectores interesados deben consultar "Las Matematicas del Filtro de Kalman" en el anexo donde se encuentra el resumen del algoritmo.
Si el estado de un sistema es constante, el filtro de Kalman se reduce a una forma secuencial de mínimos cuadrados determinísticos con una matriz de peso igual al inverso de la medición de la matriz de la covarianza del ruido. En otras palabras, el filtro de Kalman es esencialmente una solución recursiva del problema de los mínimos cuadrados. Carl Friedrich Gauss fue el primero que resolvió el problema en 1795 y publicó sus resultados en 1809 en su Theoria Motus, donde aplicó el método de los mínimos cuadrados para encontrar las órbitas de cuerpos celestiales (vea el párrafo Que Dijo Gauss). Todas las declaraciones de Gauss sobre la efectividad de los mínimos cuadrados en el analisis de las mediciones se aplican igualmente muy bien al Filtro Kalman.
UN EJEMPLO SIMPLE
Un ejemplo hipotético simple puede ayudar a aclarar los conceptos dados en esta sección. Considere el problema para determinar la resistencia real de una resistencia nominal de 100-ohm por medio de mediciones repetidas en el ohmnímetro y procesándolos en el filtro de Kalman.
Primero, uno debe determinar los modelos estadísticos apropiados del estado y los procesos de medición para que el filtro pueda calcular los pesos apropiados de Kalman (o los incrementos). Aquí, sólo una variable del estado--la resistencia, x--es desconocida pero asumimos que va a ser constante. Para que el proceso del estado evolucione con el tiempo de la siguiente manera:
Xk+1 = Xk [1]
Notar que ningún ruido aleatorio adultera el proceso del estado a medida que evoluciona con el tiempo. Ahora, el código coloreado, en una resistencia indica su precisión, o tolerancia, a partir de la cuál puede uno puede deducir--asumiendo que el conjunto de resistencias tiene un Gaussiano o el histograma normal--que la incertidumbre (variación) del valor de 100-ohm es,2 (2 ohm). De modo que nuestra mejor estimación de x, sin las medidas, es x0/ = 100 con una incertidumbre de P0/ = 4. Mediciones repetidas con el ohmnímetro nos dará:
Zk = Xk + Vk [2]
Dan directamente el valor de la resistencia con algún ruido de la medición, vk (se asume que los errores de medición de encendido-encendido no estan relacionados). El fabricante del ohmnímetro nos indica que la medición de la incertidumbre del ruido debe ser Rk = (1 ohm)2 con un valor promedio de cero alrededor de la resistencia verdadera.
Comenzando con un K=0 del filtro Kalman con un estimado inicial de 100 y una incertidumbre de 4, siendo el peso para actualizar con la primera medición de:
[3]
con la estimación del estado actualizado como:
[4]
donde x0/0 es la mejor estimación en un tiempo cero, basada en la medición a un tiempo cero. Notar que las medidas reciben un peso relativamente alto porque es mucho más preciso (menos incierto) que la estimación del estado inicial. La incertidumbre asociada o variación de la estimación actualizada es:
[5]
Nótese también que justo en una buena medición disminuye la varianza de la estimación del estado de 4 a 4/5. Según la ecuación [1], el estado real se proyecta identicamente al tiempo 1, de tal manera que la proyección del estado y la proyección de la variación para la siguiente medición en un tiempo 1 es:
; [6]
Repitiendo el ciclo una y otra vez el nuevo incremento es:
[7]
y la nueva varianza actualizada es:
[8]
Figure 3. Las mediciones individuales de la resistencia de un resistor nominal de 100-ohm son repartidos alrededor del valor verdadero ligeramente menor a 102 ohm. El estimado del filtro Kalman converge gradualmente hacia este valor.
La figura 3 representa una simulación de este proceso cuando el estimado converge hacia el valor verdadero. La incertidumbre del estimado para este problema que proporciona el filtro de Kalman, aparece en Figura 4. Uno puede ver que la incertidumbre convergerá eventualmente a cero.
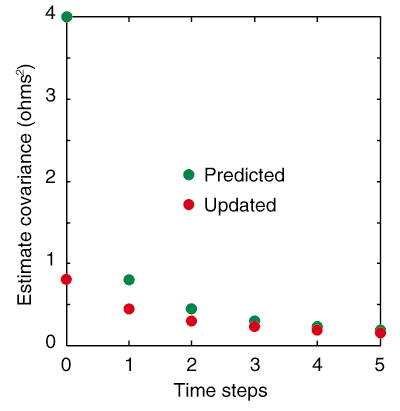
Figure 4. Inicialmente, la incertidumbre predecida (varianza) del valor de la resistencia es 4 ohms2 y es basada simplemente en el valor de la tolerencia dado por el fabricante. Sin embargo, después de seis mediciones, la variación estimada cae por debajo de los 0.2 ohms2.
Un Nuevo Grupo de Condiciones. Ahora cambiemos el problema asumiendo que las medidas se toman de año en año cuando el resistor colocado en condiciones de medio ambiente extremas, de tal modo que la resistencia verdadera cambie hasta una cantidad pequeña. El fabricante indica que el pequeño cambio es independiente de año a año con un promedio de cero y una variación de 1/4 ohms2. Ahora el proceso del estado evolucionará con el tiempo tal como:
Xk+1= Xk+Wk. [9]
donde el ruido aleatorio, wk, tiene una variación de Qk = 1/4. En el caso anterior, la predicción de la varianza de un tiempo cero a un tiempo uno fue constante como en la ecuacion 6. Aquí, debido al ruido aleatorio de la ecuación [9], la varianza predecida es:
[10]
Ahora los cálculos del incremento y de la varianza actualizada se procesan en las ecuaciones [7] y [8] pero con valores más grandes para la varianza predecida. Esto se va a repetir durante todo el ciclo dado que aquellas mediciones actualizadas van a decrecer la varianza, mientras tanto el paso predecido va incrementar la varianza. Figure 5 ilustra esta tendencia. Eventualmente, el filtro alcanza un estado fijo o constante cuando la varianza incrementa en la etapa de la predición coincidiendo con el decrecimiento de la medición en la etapa actualizada, con Pk+1/k = 0.65 y Pk/k = 0.4. El Qk representa una parte muy importante del modelo del Filtro Kalman, porque este filtro te dice cuanto puede retroceder en el tiempo para ponderar las mediciones. Un valor incorrecto de este parámetro puede afectar drásticamente el rendimiento.
Figure 5. La verdadera resistencia de un resistor en un ambiente con una temperatura variable no es suficientemente constante. Si este es modelado asumiendo una variación con un promedio de cero y una varianza de 0.25 ohms2, el Filtro Kalman estima que la varianza de la resistencia converge a 0.4 ohms2 después de sólo unas pocas mediciones.
INTEGRACIÓN de GPS/INS
Nosotros podemos ver que el filtro de Kalman está provisto de un algoritmo simple que puede prestarse fácilmente a los sistemas integrados y solo requiere de un modelo estadístico adecuado de las variables de estado y ruidos asociados para optimizar el rendimiento. Este hecho lleva a un uso entusiasta y amplio en aplicaciones asistidas por la inercia.
La integración de los GPS con un sistema de navegación inercial (INS) y un filtro de Kalman proporcionan un resultado global mejorado en toda la navegación. Esencialmente, el INS proporciona rendimientos casi silenciosos que se arrastran lentamente con el tiempo. El GPS tiene un arrastre mínimo pero con mucho más ruido. El Filtro de Kalman usando los modelos estadísticos de ambos sistemas, puede aprovechar las características de los diferentes errores y minimizar optimamente sus tendencias.
Como se observa en el anexo de "Las Matemática del Filtro de Kalman", el filtro de Kalman es un algoritmo lineal y asume que el proceso que genera las mediciones es también lineal también. Porque la mayoría de los sistemas y procesos (incluso GPS y INS) son no lineales, se necesita un proceso de referencia ya conocido para utilizarlo como método de linealización.
Figure 6 ilustra la solución para integrar GPS y navegadores inerciales . Note que los valores verdaderos de cada sistema se cancelan mutuamente cuando se miden en el filtro Kalman de que solo el GPS y los errores inerciales necesitan ser modelados. La trayectoria de referencia, se espera sea lo suficientemente cercano a lo verdadero de tal forma que los modelos de error sean lineales y el filtro Kalman sea óptimo. Para la mayoría de las aplicaciones del GPS este es el caso.
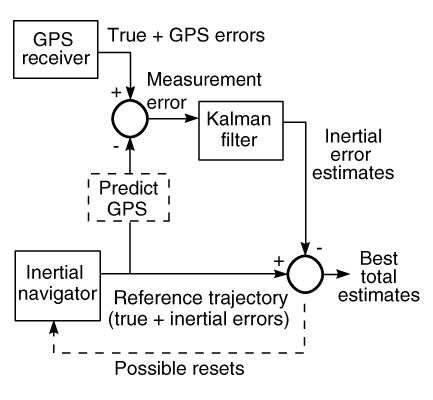
Figure 6. Un receptor de GPS integrado y el navegador inercial usan un filtro de Kalman para mejorar la ejecución global de la navegación.
De este modo aunque todos los sistemas son no lineales, el filtro Kalman sigue operando dentro del dominio lineal. Por supuesto que variables de estado del Filtro Kalman deben modelar adecuadamente todas las variables de errores de ambos sistemas. Los errores GPS podrían incluir al reloj receptor, la disponibilidad receptiva, ionósfera, troposfera, multipath y las efemerides de los satelites y los errores del reloj. Las imprecisiones inerciales por otro lado pueden incluir posición, velocidad, orientación, giro, acelerómetro y errores debido a la gravedad. La calidad el equipo y los requisitos de su aplicación determinarán hasta donde deben extenderse los modelos de error.
Si las emisiones del GPS están en la posición del usuario, uno designa la arquitectura de integración unida débilmente. Una arquitectura acoplada firmemente, registra una en la cual las emisiones GPS son seudorangos (y fases portadoras posiblemente) y la trayectoria de referencia se usa (junto con las efemerides del receptor GPS) para predecir las mediciones GPS. En el sistema acoplado muy firmemente los errores de la medición podrían estar dentro del dominio del rango mas que dentro del dominio de la posición. Usualmente el ensamblaje acoplado muy firmemente se prefiere porque es menos sensitivo a las pérdidas de la señal de un satélite y los modelos del Filtro Kalman adecuados son más simples y más precisos. Una debe emplear el ensamblaje acoplado débilmente cuando las recepciones del receptor proveen de una posición sin mediciones de prueba.
El método de corrección del circuito abierto se llama Filtración Kalman Linealizada.
Un método alternativo en el cual el algoritmo vuelve a alimentar los estimados al sistema inercial para mantener la trayectoria de referencia cerca a la verdad, lo que es un ejemplo de la Filtración extendida de Kalman.
GPS - SOLO NAVEGACION
En algunas aplicaciones, un INS no se desea o no puede estar disponible, como en un receptor de GPS autosuficiente (o estacionado solo). En tales casos, el filtro de Kalman reside dentro del receptor, y algunas ecuaciones conocidas (o supuestas) para el receptor de su movimiento reemplazarán al sistema inercial en una versión acoplada firmemente de la Figura 6. La extensión hasta la cual las ecuaciones de movimiento (de medición inactiva para un receptor en movimiento) modela de manera precisa la trayectoria del receptor y determinará el modelo del error que se necesita en el filtro Kalman.
Las ecuaciones simples de movimiento generalmente exhiben grandes errores que causan un bajo rendimiento relativo de las trayectorias de referencia de base inercial en situaciones en que el receptor se encuentre en movimiento. Desde luego las ecuaciones de la ubicación fija del movimiento son triviales y muy precisas. Aquí, la ventaja de usar la filtración Kalman contra la del punto crítico y la de determinación de mínnimos cuadrados es que las acuaciones de movimiento pueden suavizar el ruido GPS, mejorando el funcionamiento.
LAS MATEMÁTICAS DEL FILTRO KALMAN
El filtro de Kalman asume que el vector del estado del sistema Xk , evoluciona con el tiempo:
Xk+1 = FkXk + Wk
con el vector de la medida dado por
Zk = HkXk + Vk
donde x0, wk, y vk son mutuamente vectores no correlativos. Los últimos dos corresponden a secuencias de ruidos blancos, que significan m0, 0, y 0 y covarianzas definitivas no negativos de S0, Qk, y Rk, respectivamente. El filtro de Kalman óptimo correspondiente es dado por el algoritmo recursivo de la Figura 7, la cual corresponde al diagrama del bloque de la Figura 2. El vector xk/j denota la estimación óptima de x en un tiempo tk, basado en mediciones hasta tj, y Pk/j es la matriz covarianza de la estimación del error optimo correspondiente, en donde el modelo del filtro desarrollado coincide con el sistema del mundo real que realmente genera los datos.
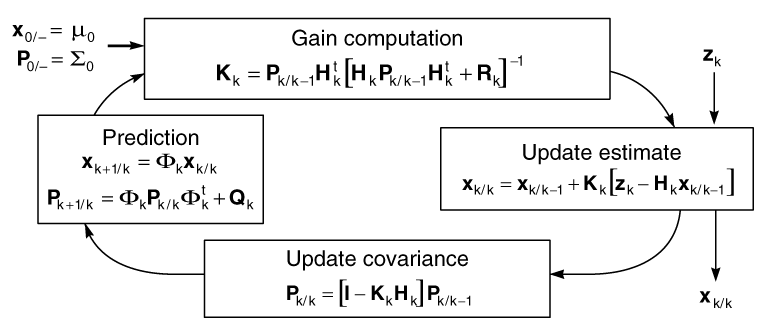
Figure 7. el algoritmo del Filtro Kalmann comprende cuatro pasos: cálculos incrementados, actualización de la estimación del estado, actualización de la covarianza, y predicción.
Uno puede derivar las ecuaciones del filtro usando varios métodos. Minimizando el error medio cuadrático generalizado, E[etk/j Aek/j], donde el ek/j[xk xk/j y A es cualquier matriz ponderada semidefinida positiva, resultan en las ecuaciones de Kalman si todas las variables y ruidos son Gaussianos. Para los casos no-Gaussianos, una restricción adicional requiere que tenga una estrecha relación lineal entre la estimación del estado, las mediciones, y el estado predecido.
CALCULOS PRÁCTICOS
Sin tener en cuenta las aplicaciones del equipo --sea él GPS, INS, u otros dispositivos--el desarrollo de un sistema práctico de navegación basado en el Filtro Kalman requiere atención a una variedad de consideraciones de los cálculos.
La porción que se analiza de la covarianza del filtro (no requiriendo datos actuales; vea Figura 2 y 7) usa modelos de error predeterminados de los sistemas potenciales (GPS, inercial, etc.) para predecir el comportamiento de una configuración en particular. El diseñador del filtro repite esto para los diferentes equipos (modelos) que potencialmente se usarían hasta que los requisitos estén satisfechos. En algunos casos, uno debe implementar el Filtro Kalman en una pequeña computadora con sólo unos pocos estados para modelar el proceso. Este filtro suboptimo debe ser evaluado por algoritmos especiales de análisis de la covarianza que reconozcan las diferencias de los modelos del mundo real que producen las mediciones, así como el modelo de filtro implementado. Finalmente, una vez que el filtro reúne todos los requisitos del funcionamiento deberán hacerse algunas simulaciones de todos los procesos para evaluar la precisión del método de linealización y de búsqueda de errores computacionales numéricos.
En la mayoría de los casos, el filtro Kalman extendido (con reajustes después de cada ciclo) van a mejorar cualquier error en la linealización. Los errores numéricos computacionales causadas por la longitud de la palabra terminal de la máquina, se manifiesta en las matrices de las covarianzas que llegan a ser no simétricas o tienen elementos negativos en la diagonal causando potencialmente desastres en el rendimiento. Este problema puede ser aliviado por incremento de la precisión de la computadora o por el empleo de un algoritmo que teóricamente valga a otro má s fuerte numericamente.
El filtro de Kalman
Esta página se significa ser una introducción breve a Kalman se filtra con unos ejemplos simples para ilustrar el uso y aplicación de cosas así se filtra. La meta es aplicar el Kalman fíltrese la técnica a cinemática que encaja en el MINOS datos análisis.
El filtro de Kalman es una técnica recursiva de obtener la solución a un menor ataque de los cuadrados. Este método recursivo tiene la ventaja de eficacia del computacional. N dado pega, con 2 dimensiones (el x,y) por el golpe, un menor ataque de los cuadrados tradicional involucra una inversión de la matriz cuyas dimensiones son 2N x 2N. Además, deben conocerse los golpes a ser incluidos en el ataque anterior al ataque. Los Kalman se filtran el acercamiento realiza un cálculo como cada golpe se agrega al ataque. Esto tiene la ventaja de una inversión de la matriz muy más simple (2 x 2 contra 2N x 2N). además, el filtro de Kalman puede extrapolar la huella en buen salud al próximo punto del golpe a que tiempo que los golpes reales pueden buscarse en alguna ventana de la extrapolación. Para las referencias en el filtro de Kalman , vea [1] [2] [3] [4] [5] [6].
El filtro de Kalman básico se trata de los sistemas lineales (los sistemas non-lineales son tratados por una aproximación lineal que usa el Kalman extendido fíltrese, para ser discutido después). Nosotros usamos la anotación de Fruhwirth [4], y hace las definiciones siguientes:
el xk = el vector estatal filtrado al punto k
el xk+1k = el vector estatal extrapolado del punto k para apuntar el k+1
Ck+1k = la matriz de la covarianza de xk+1k - xk+1t dónde el xk+1t está el verdadero valor del vector estatal en el k+1 del punto
Ck = la matriz de la covarianza filtrada al punto k
Fk = vector propagador de estado del punto k hacia el k+1
el wk = el ruido del proceso (la perturbación del azar) al vector estado al punto k
Qk = la matriz de la covarianza de wk
el mk = el vector de la medida al punto k
el ek = el ruido de la medida al punto k
Vk = la matriz de la covarianza de ek
Las dos ecuaciones básicas son
xk = xk-1Fk-1 + wk-1
mk = xkHk + ek
Típicamente, el vector estatal sería un vector de longitud 5, con dos posiciones transversas y tres velocidad adquirida como sus componentes. El vector de la medida podría ser de longitud 3, mientras consistiendo en uno pegaron que los scintillator despojan, el tiempo del golpe, y el cargo integrado. Éstos son meramente los ejemplos para ilustrar los dos tipos del vector.
Empezar el Kalman se filtran, lo siguiente debe definirse primero:
el x0 = una estimación inicial del vector estado
Fk = matriz propagador de estado para todos los puntos
Qk = el proceso ruido covarianza matrices para todos los puntos
Vk = el medida ruido covarianza matrices para todos los puntos
Hk = el matrices que convierte un vector estatal al punto k en un vector de la medida
La matriz de la covarianza estatal inicial que C0 puede ponerse a la matriz de identidad multiplicada por un factor de la balanza grande. El más pequeño esto es, el más el peso se pone en el vector estado inicial, tan en general nos gustaría hacer C0 tan grande como posible. Sin embargo, debido a redondo-fuera de los errores, nosotros necesitamos restringir esta matriz a un valor razonable que depende del ataque particular bajo la consideración.
Nosotros estamos ahora listos aplicar el filtro de Kalman. A cada punto k, un cuatro proceso del paso es aplicado:
Ckk-1 = Fk-1 Ck-1 Fk-1T + Qk-1
Kk = Ckk-1 HkT (Vk + Hk Ckk-1 HkT)-1
xk = xk-1Fk-1 + Kk (mk - Hkxk-1Fk-1)
Ck = (1 - Kk Hk)Ckk-1
He combinado la extrapolación y el filtrádo del vector estado en un paso (3). En la mayoría de las referencias, estos dos procesos se presentan separadamente. Al final del proceso reiterativo, el xk del vector estatal final representa los valores en buen salud que usan todos los puntos de los datos. Para obtener los valores en buen salud a cualquier punto k, el usuario puede encajar entonces al revés, mientras empezando con el último punto. El valor en buen salud a algún punto k es entonces el promedio entre el xk de los vectores estatal entre los dos ataques.
El ejemplo: El promedio
El primer programa presentado aquí toma el promedio pesado de un juego de valores. En este ejemplo, el estado y vectores de la medida tienen longitud 1. los Vectores y matrices son entonces equivalentes al scalars. El mk de los dimensiones que puse a los datos de la entrada apunta para ser promediado. Inicializo la matriz (el scalar) Vk a las variaciones (los cuadrados de los errores). Porque el vector estatal es el vector de la medida, la matriz Hk se vuelve la unidad, como hace la matriz del propagador Fk. No hay ningún ruido del proceso, para que Qk desaparece.
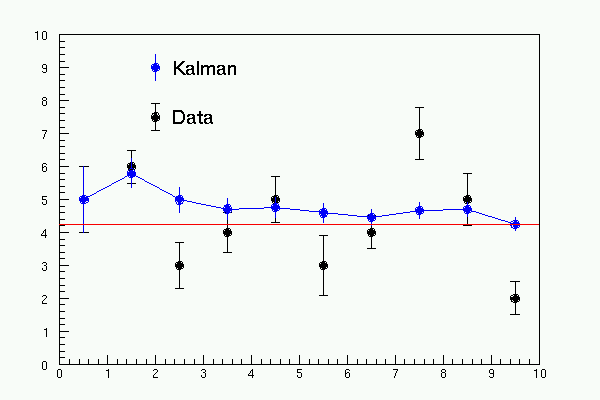
Los puntos negros representan los datos moderados; los puntos azules representan el vector estatal filtrado como calculado por el filtro de Kalman al punto k. se obtiene La incertidumbre en el vector estatal filtrado de la matriz de la covarianza Ck y se ve para crecer más pequeño con k creciente, como esperado. El valor final del ataque de Kalman es 4.24835+-0.20320, considerando que el verdadero valor de un menor cálculo de los cuadrados (mostrado como una línea roja horizontal en la parcela) es 4.24838+-0.20320, un acuerdo fraccionario en el promedio pesado de 10-5.
El programa principal está en average.cc. La clase de Kalman se define en kalman.h y es el corazón del Kalman que se filtra la rutina. Otros archivos del título necesitados compilar y ejecutar este ejemplo son misc.h, definitions.h, y simplearray.h.
El ejemplo: La partícula cobrada en un campo del dipolo
En este ejemplo, varias coordenadas del x,y están moderadas en las regiones de ningún campo magnético en z fijo posiciona upstream y " downstream de un imán del dipolo (con el componente primario transverso al eje de la viga). UN total de 20 estaciones rastreando con un espacio uniforme de 1 metro es simulado; cada uno rastreando la estación proporciona una resolución de 5 mm a una medida de ambos posición transversa en cada coordenada. Cada uno rastreando la estación representa una longitud de la radiación de 1%. Ninguna pérdida de energía es simulada. El campo magnético se localiza después de la 10 estación rastreando y antes de los 11. Hay sólo un componente, la magnitud de que es una función de Gaussian de la posición longitudinal, con un valor máximo de 5 Tesla y un RMS espaciales de 0.1 metro, representando un puntapié de velocidad adquirida de 0.376 GeV/c. Nosotros escogemos nuestro vector estatal para ser de dimensión 5, mientras representando las dos posiciones transversas, las cuestas transversas, y el cargo a la proporción de velocidad adquirida. A cada iteración del filtro salvo el uno que los travesaños el campo magnético, las ecuaciones de movimiento son lineales. La única complicación involucra múltiplo esparciendo que se tiene en cuenta a través de la proceso ruido covarianza matriz. Nosotros usamos el cálculo de Wolin y Ho [5]. La propagación del vector estatal entre los 10 y 11 aviones es casi lineal, pero no realmente. Nosotros el linearize el sistema calculando derivado del vector estatal primero con respecto a sí mismo. En el filtro de Kalman, la propagación no se hace tomando el producto de la matriz del propagador con el vector estatal, sino nadando el vector estatal a través del campo magnético. La matriz de propagador de linearized se usa calculando la matriz de la covarianza estatal y los Kalman ganan la matriz.
El filtro de Kalman aplicó a la partícula cobrada en un campo del dipolo. La distribución de velocidad adquirida se traza en (un). La diferencia entre la velocidad adquirida en buen salud y verdaderas divididas por la verdadera velocidad adquirida se muestra en (b). El valor malo de la proporción de velocidad adquirida en buen salud se muestra como una función de velocidad adquirida en (c). El cuadrado del RMS de la proporción de velocidad adquirida en buen salud se muestra como una función de velocidad adquirida cuadrada en (d).
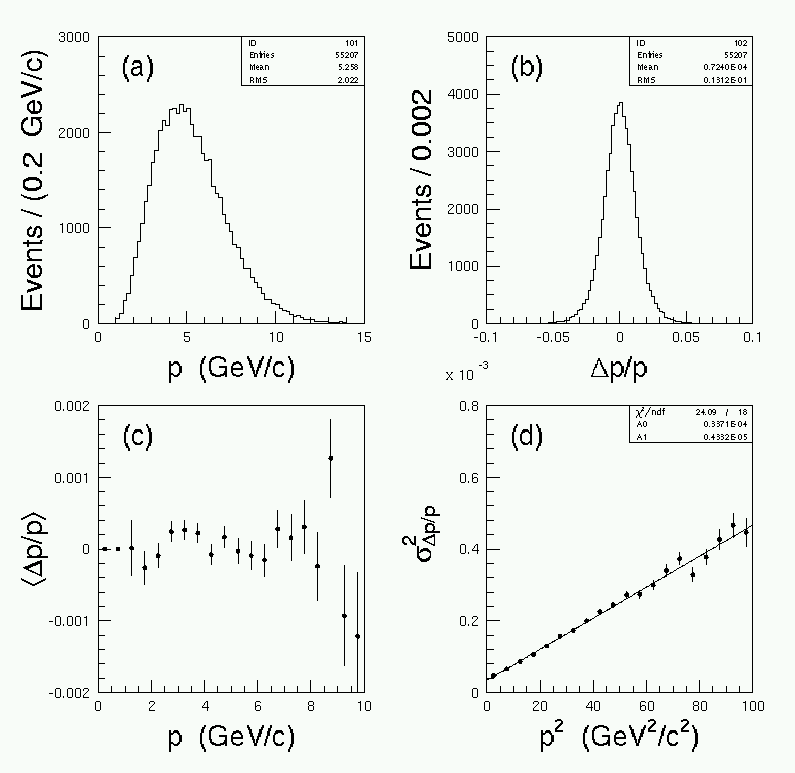
El campo magnético representa un pT simple da saltos en la dirección de x:
p theta = px2 - px1 = pT
De esto nosotros calculamos que se relaciona la incertidumbre fraccionaria en la velocidad adquirida a la incertidumbre en la theta del ángulo por
edp/p2 = (p2 / pT2) ptheta2
La incertidumbre en el theta tiene dos componentes: uno de la resolución espacial en la medida y otro del múltiplo esparcir. El componente de la resolución espacial es independiente de velocidad adquirida, considerando que que por el múltiplo esparcir es proporcional al lo inverso de velocidad adquirida. N dado allana, la incertidumbre angular debido a la resolución espacial es.
etheta = ex / L [12 / (N (N2 - 1))]1/2
Donde el ex = 5 mm es la resolución espacial y L = 1 m es la distancia entre los aviones. Para la mitad del descubridor (N = 10), nosotros encontramos la incertidumbre angular para ser 0.00055. La incertidumbre en el theta es 0.00078 que son la raíz 2 veces la incertidumbre angular por la mitad el descubridor. La incertidumbre angular debido a múltiplo que esparce en un avión es.
etheta = [0.0136 / p] (x/x0)1/2 [1 + .038 log(x/x0)]
Donde el x/x0 = 0.01 son la longitud de la radiación de un avión. Múltiplo que esparce en los primeros ocho o últimos ocho aviones no contribuye a la incertidumbre en theta que es la diferencia angular entre las dos mitades del descubridor. Por consiguiente, la incertidumbre en el theta es dos veces igual a (raíz 4) el solo avión la incertidumbre angular, y es igual a 0.0022/p. Agregando los dos componentes de incertidumbre angular en la cuadratura, nosotros encontramos que la incertidumbre del fragmento en la velocidad adquirida tiene dos componentes: uno que es la deuda constante al múltiplo esparcir, y otra de la resolución espacial y qué tiene una dependencia en la velocidad adquirida:
edp/p2 = 0.34e-4 + .43e-5 p2
Esto está de acuerdo bastante bien con los valores observados en (d). Así, nosotros estamos seguros que en este ejemplo de una partícula cobrada en un campo del dipole con múltiplo que esparce incluido, el filtro de Kalman está dando los resultados sensatos.
Considere el problema de estimar las variables de algún sistema. En los sistemas dinámicos (es decir, sistemas que varían con tiempo) las variables del sistema se denotan a menudo por las variables de estado de término. Asuma que las variables del sistema, representadas por el vector x, son gobernadas por la ecuación xk+1 = Axk + wk dónde el wk es el ruido del proceso al azar, y los subíndices en los vectores representan el paso del tiempo. Por ejemplo, si nuestro sistema dinámico consiste en una nave espacial que está acelerando con los estallidos del azar de gas de su Reacción, el vector x podrían consistir en posición p y velocidad v. Entonces la ecuación del sistema sería
Ecuación 1
donde el ak es el azar, la aceleración tiempo-variante y T es el tiempo entre el paso k y el paso k+1 . Ahora supongamos que podemos medir la posición p, entonces nuestra medida en el tiempo k podemos denotarla como:
zk = pk + vk
dónde el vk es el ruido de medida de azar.
La pregunta que se hace al filtro de Kalman es: ¿Dado nuestro conocimiento de la conducta del sistema, y dado nuestras dimensiones, cual es la mejor estimación de posición y velocidad? ¿Nosotros sabemos cómo se comporta el sistema según su ecuación, y si tenemos las medidas de la posición, cómo podemos determinar la mejor estimación de las variables del sistema? Ciertamente hacemos mejoras en cada medida a su valor, sobre todo si nosotros sospechamos que se tiene mucho ruido de la medida.
El filtro de Kalman se formula como sigue. Supongamos que asumimos a wk como ruido del proceso ó ruido del gaussiano blanco con una matriz de la covarianza Q. Further asume que el ruido de la medida es el ruido del gaussiano blanco con una matriz de la covarianza R, y que no se pone en correlación con el ruido del proceso. Nosotros podríamos formular un algoritmo de estimación tal que el sostenimiento de las condiciones estadísticos sea el siguiente:
1. El valor esperado de nuestra estimación es igual al valor esperado del estado. Es decir, "en el promedio," nuestra estimación del estado igualará el verdadero estado.
2. Nosotros queremos un algoritmo de estimación, de todo los posibles algoritmos de estimación, nuestro algoritmo minimiza el valor esperado del cuadrado del error de estimación. Es decir, "en el promedio," nuestro algoritmo da el "más pequeño" posible error de estimación.
Él para que pasa que el filtro de Kalman es el algoritmo de estimación que satisface éstos el criterio. Hay que muchas maneras alternativas de formular el Kalman se filtran las ecuaciones. Se da una de las formulaciones en las ecuaciones siguientes.
Las ecuaciones 2 - 5
Sk=Pk+R (2)
(3)
(4)
(5)
En las ecuaciones anteriores, el exponente -1 indica inversión de la matriz y el exponente que T indica la transposición de la matriz. S se llama la covarianza de la innovación, K se llama la matriz de ganancia, y P se llama la covarianza del error de la predicción.
La ecuación 5 es bastante intuitiva. El primer término derivaba la estimación estatal al k+1 de tiempo es simplemente A veces la estimación estatal en momento k. Ésta sería la estimación estatal si nosotros no teníamos una medida. En otros términos, la estimación estatal propaga a tiempo sólo como el vector estatal (vea Ecuación 1). El segundo término en la ecuación 5 se llama el término del corrector, y representa cuánto corregir la deuda estimada propagada a nuestra medida. La inspección de la ecuación 5 indica que si el ruido de la medida es muy mayor que el ruido del proceso, K será pequeño (es decir, nosotros no daremos mucha creencia a la medida); si el ruido de la medida es mucho más pequeño que el ruido del proceso, K será grande (es decir, nosotros daremos mucha creencia a la medida).
El filtrado Kalman es un campo grande cuyo profundidades que nosotros no podemos esperar empezar a aplomar en semejante papel breve como esto. Los miles de papeles y docenas de libros de texto han sido escrito en este asunto desde que su principio en 1960. Algunos problemas que complican la aplicación del filtro de Kalman son como sigue.
¿1. nosotros hemos asumido que la ecuación del sistema es lineal (vea la ecuación 1). Si la ecuación es no lineal?
¿2. si el ruido de la medida y el ruido del proceso Gaussiano son, no blanco, y no independiente de nosotros?
¿3. si las estadísticas (por ejemplo, la matriz de la covarianza) del ruido no es conocido?
4. las ecuaciones 2--5 son las ecuaciones de la matriz, y como tal puede imponer una carga grande para los sistemas computacionales alto-dimensionales.
¿5. Si las características del ruido cambian con el tiempo? ¿Nosotros podemos formular un filtro de Kalman que se adapta con el tiempo a los cambios en las características del ruido de algún modo?
Aprendiendo el algoritmo de Kalman
El Filtro de Kalman dimensional
Suponga que nosotros tenemos una variable al azar el x(t) de quien nosotros queremos estimar sus valores para t0 ,t1, t2, el t3, etc. También, supongamos que sabemos que x(tk) satisface una ecuación dinámica lineal.
x(tk+1) = ð x(tk) + u(k) (la ecuacion dinamica)
En la ecuación anterior ð es un número conocido. Para trabajar a través de un ejemplo numérico permítanos asumir
ð = 0.9
Kalman asumió ese u(k) que es un número al azar seleccionado escogiendo un número de un sombrero. Suponga los números en el sombrero es tal que la media de u(k) = 0 y la variación de u(k) es Q. Para nuestro ejemplo numérico, nosotros tomaremos Q como 100.
Esto es:
Eu(k)=0
E[u(k) ]2 = 100
Donde E es el operador de valor esperado.
Desde el u(k) es determinado escogiendo un número de un sombrero, su valor es independiente del valor de x o cualquier otro azar inconstante y el más sobre todo es independiente de los valores pasados de u. Una variable del azar cuyo valor es independiente de los valores de todas las otras variables del azar al cual se le llama llama el ruido blanco.
En las lecciones más tarde nosotros nos extenderemos los Kalman se filtran a casos dónde la ecuación dinámica no es lineal y donde u no es el ruido blanco. Pero para esta lección, la ecuación dinámica es lineal y w es el ruido blanco con media cero.
Para aquéllos que son un poco mohoso en la teoría de probabilidad: si el x(k) y u(k) es dos variables del azar independientes, entonces el valor esperado de su producto se da por
Ex(k)u(k)=Ex(k) Eu(k)
Para nuestro caso Eu(k)=0 para que
Ex(k)u(k) =0
Cuando el valor esperado del producto de dos variables es cero, se dice que las variables no esta en correlacion.
Ahora suponga eso al t0 de tiempo alguien vino y le dijo él pensó el x(t0)=1000 pero que él podría estar en el error y él piensa la variación de su error es igual a P. suponga que usted tenía mucho confianza en esta persona y, por consiguiente, se convenció que ésta era la posible estimación mejor de x(t0). Ésta es la estimación inicial de x. a veces se llama el a priori la estimación.
Un filtro de Kalman necesita una estimación inicial para empezar. Esta como un artefacto automovilístico que necesita un motor del juez de salida para conseguir la ida. Una vez consigue la ida que no necesita el motor del juez de salida ya. Mismo con el filtro de Kalman. Necesita una estimación inicial para conseguir la ida. Entonces no necesitará más estimaciones de fuera. En las lecciones más tarde nosotros discutiremos posibles fuentes de la estimación inicial pero para ahora sólo asuma alguna persona vino y lo dio a usted.
Así que nosotros tenemos una estimación de x(t0), que nosotros llamaremos xe. para nuestro ejemplo.
xe = 1000
La variación del error en esta estimación se define por
P = E [(x(t0) -xe)2]
donde E es el operador de valor esperado. el x(t0) es el valor real de x al t0 de tiempo y el xe es nuestra estimación mejor de x. Así el término en los paréntesis es el error en nuestra estimación.
Para construir un filtro de Kalman, nosotros necesitamos saber el valor de P. De nuevo nosotros asumiremos que la persona que nos dijo que el xe = 1000 también nos dijeron el valor de P. De nuevo, éste es simplemente un artificio para conseguir el filtro de Kalman empezado. Para el ejemplo numérico, nosotros tomaremos P = 40,000.
Ahora nos gustaría estimar el x(t1). Recuerda que la primera ecuación nosotros escribimos (la ecuación dinámica) era
x(tk+1) = ð x(tk) + u(k)
Por consiguiente, para el k=0 nosotros tenemos
x(t1) = ð x(t0) + u(0)
Dr. Kalman dice nuestra nueva estimación mejor de x(t1) se da por
newxe = ð xe (ecuacion 1)
o en nuestro ejemplo 900 numérico.
Haga que usted ve por qué Dr. Kalman tiene razón. Nosotros tenemos ninguna manera de estimar el u(0) excepto para usar su valor malo de cero. Cómo sobre el x(t0 de F). Si nuestra estimación inicial de x(t0) = 1000 eran entonces correctos el x(t0 de F) sería 900. Si nuestra estimación inicial fuera alta, entonces nuestra nueva estimación será alta pero nosotros tenemos ninguna manera de saber si nuestra estimación inicial era alta o baja (si nosotros tuviéramos alguna manera de saber que era alto que nosotros lo habríamos reducido). Para que 900 son la estimación mejor que nosotros podemos hacer. ¿Cuál es la variación del error de esta estimación?
newP = E [(x(t1) - newxe)2]
Sustituya las ecuaciones anteriores en para el x(t1) y el newxe y usted consiguen.
newP = E [(ð x(t0) + u -ð xe)2]
= E[ð 2(x(t0) - xe)2 ]+ E u2 + 2ð E (x(t0)- xe)*u]
El último término es el cero porque se asume que u es el no correlativo con ambos x(t0) y xe.
Así que, nosotros nos salimos con
newP = Pð 2 + Q (ecuacion 2)
Para nuestro ejemplo, nosotros tenemos
newP = 40,000 X .81 + 100 = 32,500
Ahora, permítanos asumir nosotros hacemos una medida ruidosa de x. Llame la medida y y asuma y se relaciona a x por una ecuación lineal. (Kalman asumió que todas las ecuaciones del sistema son lineales. Esto se llama la teoría del sistema lineal. En las lecciones más tarde, nosotros nos extenderemos los Kalman se filtran a los sistemas non-lineales.)
y(1) = Mx(t1) + w(1)
donde w es el ruido blanco. Nosotros llamaremos la variación de w, "R". para construir un filtro de Kalman es necesario saber los valores de R y M.
Nosotros usaremos para nuestro ejemplo numérico M = 1, R = 10,000 y y(1) = 1200
Note que si nosotros hubiéramos querido estimar el y(1) antes de que nosotros miráramos el valor moderado que nosotros usaríamos
ye = Mnewxe
para nuestro ejemplo numérico nosotros tendríamos ye = 900
Dr. Kalman dice la nueva estimación mejor de x(t1) se da por
newerxe = newxe + K*(y(1) -M*newxe)
= newxe + K*(y(1) - ye) (ecuacion 3)
donde K es que un número llamó la ganancia de Kalman.
Conocemos que y(1)-ye es simplemente nuestro error estimando el y(1). Para nuestro ejemplo, este error es igual a ventaja 300. La parte de esto es debida al ruido, w y parte a nuestro error estimando x.
Si todo el error fuera debido a nuestro error estimando x, entonces nos convencerían que el newxe era bajo por 300. K=1 poniendo corregirían nuestra estimación por el lleno 300. Pero subsecuentemente alguno de este error es debido a w, nosotros haremos una corrección de menos de 300 proponer el newerxe. Nosotros pondremos K a algún número menos de uno.
¿Qué valor de K nosotros debemos usar? Antes de que nosotros decidamos, permítanos computar la variación del error resultante
E (x(t1) - newerxe)2 = E [(x - newxe - K(y - M newxe)]2
= E [(x - newxe - K(Mx + w - M newxe)]2
= E [(1 - KM)(x - newxe) +Kw]2
= newP(1 - KM)2 + RK2
donde las condiciones del producto cruzadas dejaron caer fuera porque se asume que w es el no correlativo con x y newxe. Así que el más nuevo valor de la variación se da ahora por
newerP = newP(1 - KM) 2 + RK2 (equation 5)
Si nosotros queremos minimizar el error de estimación que nosotros debemos minimizar el newerP. Nosotros hacemos eso diferenciando el newerP con respecto a K y poniendo al igual derivativo para poner a cero y resolviendo entonces para K. un poco muestras de álgebra por que el K óptimo se da
K = MP/[P(M2) + R] (Equation 4)
Para nuestro ejemplo, K = .7647
newerxe = 1129
el newerP = 7647
la variación de nuestro error de estimación está disminuyendo.
Éstas son las cinco ecuaciones del filtro de Kalman. Al t2 de tiempo, nosotros empezamos usando el newerxe de nuevo para ser el valor de xe para insertar en ecuación 1 y newerP como el valor de P en ecuación 2. Entonces nosotros calculamos K de ecuación 4 y usamos eso junto con la nueva medida, y(2), en ecuación 3 para conseguir otra estimación de x y nosotros acostumbramos ecuación 5 a conseguir los P. correspondientes Y esto persigue en ciclo de la computadora ciclo de la computadora.
En el filtro de Kalman multi-dimensional, x es una matriz de la columna con muchos componentes. Por ejemplo si nosotros estuviéramos determinando la órbita de un satélite, x tendrían 3 componentes que corresponden a la posición del satélite y 3 más correspondiendo a la velocidad más otros componentes que corresponden a otras variables del azar. Entonces ecuaciones 1 a través de 5 se volverían las ecuaciones de la matriz y la simplicidad y lógica intuitiva del filtro de Kalman se disimula. Las lecciones restantes se tratan de la naturaleza más compleja del filtro de Kalman multi-dimensional.
CONCLUSIONES
Debido a su ilusoriamente simple y fácilmente programado algoritmo optimo el Filtro Kalman continúa siendo el método de la integración adecuado en sistemas de navegación basados en el GPS. Requiere modelos estadísticos de todas las variables y ruidos multidimensionales suficientemente exactos apropiados a los pesos de los datos de las mediciones de los ruidos. Estos modelos permiten al filtro considerar para el carácter disipar de los errores en sistemas diferentes y mantienen una combinación integrada óptima de sistemas de gran potencia. La naturaleza de la recursividad del filtro permite un proceso de tiempo real eficaz. Los estudios de la covarianza de fuera de-línea permiten predecir la actuación del sistema integrada antes del desarrollo y proporcionan un conveniente y fácil uso de la herramienta del plan de sistema.
| PREDICCIÓN MEDIANTE LA APLICACIÓN DEL FILTRO DE KALMAN DE MODELOS LINEALES |
| Esta tecnología permite, mediante la metodología Bayesiana, hacer predicciones a lo largo del tiempo de cualquier suceso sujeto a incertidumbre. Este suceso puede ser el caudal que baja por un río en régimen de avenida, la demanda de material a un almacén, etc.
|
| El modelo consiste en suponer que las observaciones a predecir ðt son funciones lineales de observaciones realizadas que dependen de los parámetros ðt en la forma ðt=F'tðt+ðt
ðt=Gtðt-1+ðt
|
| En muchas situaciones, el "estado de la naturaleza" es cambiante a lo largo del tiempo, por lo que los modelos lineales ajustados para un momento no sirven para instantes sucesivos. El filtro de Kalman supera esta dificultad al ir reajustando automáticamente el modelo, con lo que se logran mejores predicciones que con otros modelos clásicos.
|
| La investigación ha sido realizada en el Departamento de Estadística e Investigación Operativa I de la Facultad de CC. Matemáticas. Se ha diseñado un algoritmo, que se ha implementado en un programa de ordenador, para poder hacer predicciones en tiempo real. Ha sido aplicado con éxito a la cuenca del río Ebro y del Duero para realizar predicciones de la evolución de caudales y avenidas para la empresa IBERDROLA S.A. |
| Dentro del campo de la predicción dinámica el Departamento de Estadística e Investigación Operativa I, ha abordado distintos proyectos de colaboración con empresas y puede prestar diversos servicios que incluyen:
|

Señales unidimensionales
-
Filtro de Kalman en navegación
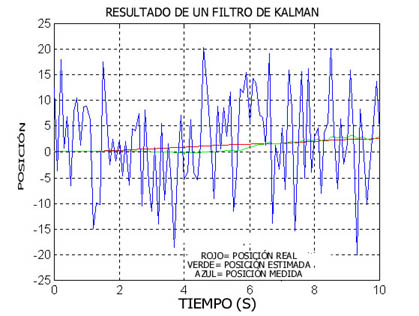
Un filtro de Kalman es esencialmente una versión recursiva y en tiempo real de un algoritmo de estimación. Un ejemplo tipico de aplicación de estos filtros es en navegación. Dado nuestro conocimiento de las ecuaciones dinámicas de p.e. un avión o un satelite y dada una serie de medidas ruidosas de su posición ir determinando en tiempo real (es decir, actualizandose con cada nueva medida, en vez de esperar a tenerlas todas).
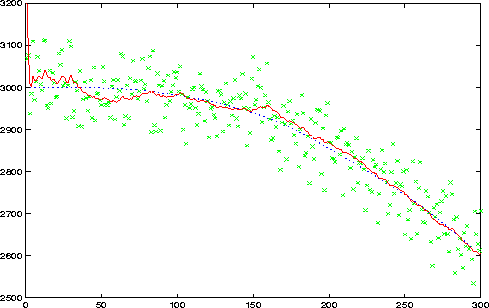
La gráfica siguiente refleja el resultado de aplicar nuestro filtro de Kalman a la estimación de la altura de un avión a partir de unos datos (más o menos erróneos) de un acelerómetro y un altímetro. La línea discontinua muestra la verdadera altura, mientras que las cruces indican las mediciones del altímetro, que como se observa forman una banda de unos 100 mt alrededor de la verdadera posición. La línea continua nos dá la estimación del filtro de Kalman. Vemos que en un aterrizaje es mucho mejor que nuestro piloto haga caso al Dr. Kalman y no al altímetro.
-
Eliminación adaptativa de ruido
Un filtro adaptativo es aquel en el que podemos variar sus parámetros para intentar satisfacer un cierto criterio. Tienen numerosas aplicaciones, de entre las cuales aquí ilustramos la reducción de ruido en una señal de voz. En la fila superior tenemos una señal de voz (la s[n] original que desconocemos). En la segunda mostramos lo que grabamos en nuestro micro, la señal anterior y un gran ruido superpuesto. Finalmente el la tercera fila mostramos el error e[n] del algoritmo adaptativo, que como hemos visto es muy similar a la señal original (en todo caso muchísimo mejor que la versión inicial).

Más allá la Lectura
La literatura del Filtro Kalman abunda, con aplicaciones que van de la navegación de una nave espacial al demográfico de la carne francesa de la manada ganadera. Para aliviarlo en él, aquí están unas sugerencias:
BIBLIOGRAFIA Y DIRECCIONES DE INTERNET
http://www.cs.unc.edu/~welch/kalmanIntro.html
P. Maybeck, Modelos Estocásticos, Estimación, y Mando. La Prensa académica, Nueva York, 1979.
De la Teoría del Movimiento de los cuerpo celestes que se mueven alrededor del Sol en Secciones Cónicas, una traducción por C.H. Davis de C.F. los 1809 Theoria Motus Corporum de Gauss
Coelestium en Sectionibus Conicis Solem Ambientium. La traducción de Davis de 1857 que fue publicada por Publicaciones de Dover, Inc., Nueva York, en 1963.
"The Kalman Filter," a site maintained by G. Welch and G. Bishop of the University of North Carolina at Chapel Hill's Department of Computer Science: http://www.cs.unc.edu/~welch/kalmanLinks.html
Descargar
| Enviado por: | José Francisco Espinoza Matos |
| Idioma: | castellano |
| País: | Perú |
Todos los derechos reservados.