Ingeniero Técnico en Informática de Sistemas
Estructura de datos
Introducción
¿Qué es una Estructura de Datos?
Cuando hablamos de tipos de datos básicos nos referimos a un conjunto de valores más sus operaciones asociadas, por ejemplo, dentro del computador un número entero se representa con un par de bytes (16 bits), con ello, sólo puede almacenar valores en un rango de [-2 16/2, +216/2] y disponer de los operadores aritméticos: +, -, *, / y mod. Extendiendo el concepto, si agrupamos un conjunto de valores de igual o distinto tipo de dato básico y enseguida definimos la manera de cómo operar sobre ellos, es decir, sus métodos de acceso, estaríamos en presencia de una ESTRUCTURA DE DATOS.
La definición de una Estructura de Datos posee un primer nivel de abstracción en donde simplemente se identifica la colección de elementos a agrupar y sus operaciones de acceso. En un segundo nivel, el de implementación, ya pensamos en un lenguaje de programación específico y es ahí donde surgen preguntas como ¿cuál es la estructura óptima? o ¿qué funciones y/o procedimientos definir?
Ejemplo: Suponga que se necesita implementar un juego entretenido para 2 jugadores.
Nivel #1:Lógico o de abstracción.
Si sugerimos el famoso juego del "El Gato" pensemos en un nivel abstracto que se trata de una colección de casilleros en donde se deberá marcar X ó O a medida que el jugador le toque su turno. Ya tenemos la colección de elementos X ó O y la operación marcar (X ó O según sea el caso).
Nivel #2:De Implementación
A nivel de implementación ¿qué estructura sería factible en este caso?. Por las características del juego, (después de analizar ventajas y desventajas) concluimos que una arreglo bidimensional de 3 x 3 de tipo carácter sería una solucion mas factible.Netcyrus Página 2 03/05/01
Type
TableroGato = Array [1..3, 1..3] of char;
Var
TableroJuegoEntretenido:TableroGato;
A este arreglo se le podría asociar el procedimiento MarcaJugador(turno: integer)
Define otros para poder jugar más tarde!
Arreglos
¿Qué son los arreglos?
Son una agrupación de datos homogéneos, es decir, con un mismo tipo de dato básico asociado. Se almacenan en forma contigua en la memoria y son referenciados con un nombre común y una posición relativa.
Ejemplos:
Arreglo Lineal (1 dimensión ó vector)
Vista gráfica
| [1] | [2] | [3] | [4] | [5] |
Definición de tipo
Type
Linea:Array [1..5] of TipoBasico;
Var
MiArreglo:Linea;
| Arreglo Bidimensional (matriz) [1,1] [1,2] [1,3] [1,4] [2,1] [2,2] [2,3] [2,4] [3,1] [3,2] [3,3] [3,4] | Definición de tipo Type | ||||||
Para pensar
Para pensarlo...
-
Determina el mecanismo de acceso a cada posición de las estructuras definidas.
-
¿Existirán arreglos de más de 2 dimensiones?
-
Investígalo o piénsalo, dibuja su gráfica y constrúyele ladefinición de tipo con tu grupo de trabajo.
Para implementar
Para implementar...
-
Recorre la diagonal secundaria de un arreglo bidimensional.
-
Almacena los antecedentes bibliotecarios en un arreglo tridimensional.(NombreLibro, Código Libro, FechaPublicación, Autor(es))
Registros (TDU)
¿Qué son los registros?
Son un tipo de datos formado por una colección finita de elementos no necesariamente homogéneos. El acceso se realiza a través del nombre del registro seguido del campo específico al que se desea acceder.
Supongamos la sgte. vista gráfica de un registro cualquiera:
| Año | Marca | Precio |
| 1997 | OPEL CORSA SWING 1.4 | 4.150.000 |
Definición de tipo asociada:
| TYPE TipoAuto = RECORD Var |
¿Cómo acceder a los campos individuales de un registro?
Para acceder a cada uno de los campos se utiliza la siguiente función de acceso:
NombreRegistro.nombre del campo
Para el registro AUTOMOVILES revisado anteriormente se tiene que el acceso a cada uno de sus campos se realiza como sigue:
AUTOMOVILES.año
AUTOMOVILES.marca
AUTOMOVILES.precio
La principal ventaja del uso de registros es que posibilitan modelar objetos que contienen varias características y acceder a ellas mediante un nombre único.
Para Implementar
Definir la estructura de datos que represente las cuentas bancarias para 500 clientes del Banco Della Plaza. Ellas deben contener un saldo cuenta corriente y otro en línea de crédito. Identifica las operaciones básicas asociadas a la estructura.
Definir la estructura de datos que represente un hotel 5 estrellas de 5 pisos y 10 habitaciones por piso. Identifica las operaciones básicas asociadas a la estructura.
Definir una estructura de datos para representar una agenda diaria. Plantear la solución estática y dinámica. Identificar las operaciones básicas asociadas a la estructura.
Alternativa solución Cajero Automático (1):

-
Operaciones básicas
Procedure Giro (var Clientes:Cta;tipocuenta,indice:integer;Monto:real)
{*Extrae dinero desde alguna de las cuentas*}
Procedure Deposito (var Clientes:Cta;tipocuenta,indice:integer;Monto:real)
{*Abona a alguna de las cuentas*}
Procedure Inicializacion (var Clientes:Cta;tipocuenta,indice:integer; Monto:real)
{*Almacena los montos iniciales para cada cliente*}
Procedure Transferencia (var Clientes:Cta;sentido,indice:integer; Monto:real)
{*Transfiere dinero entre cuentas de un mismo cliente*}
Asignación de Memoria Dinámica
Métodos de Asignación de Memoria
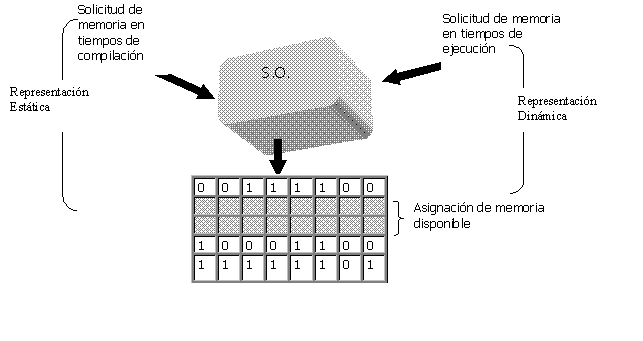
¿Cuáles son los métodos de asignación de memoria utilizados por el S.O.?
Cabe destacar que el almacenamiento y procesamiento de todos los datos es realizado en memoria RAM, en un segmento destinado a ello (DS), por ello, es importante conocer los métodos de asignación de memoria utilizados para su almacenamiento. Por un lado, se tiene la asignación estática de memoria en donde se reserva la cantidad necesaria para almacenar los datos de cada estructura en tiempo de compilación. Esto ocurre cuando el compilador convierte el código fuente (escrito en algún lenguaje de alto nivel) a código objeto y solicita al S.O. la cantidad de memoria necesaria para manejar las estructuras que el programador utilizó, quien según ciertos algoritmos de asignación de memoria, busca un bloque que satisfaga los requerimientos de su cliente. Por otro lado se tiene la asignación dinámica en donde la reserva de memoria se produce durante la ejecución del programa (tiempo de ejecución). Para ello, el lenguaje Pascal cuenta con dos procedimientos: NEW() y DISPOSE() quienes realizan llamadas al S.O. solicitándole un servicio en tiempos de ejecución. El procedimiento NEW ,por su parte, solicita reserva de un espacio de memoria y DISPOSE la liberación de la memoria reservada a través de una variable especial que direccionará el bloque asignado o liberado según sea el caso.
Ejemplo : Cuando se compilan las sgtes. líneas de código se produce una asignación estática de memoria:
var linea: string [80];
(*Se solicita memoria para 80 caracteres --> 80 bytes)
operatoria: Array[1..100,1..100] of real;
(*Se solicita memoria para 100x100 reales -> 100 x 100 x 4 bytes)
interes : integer;
(*Se solicita memoria para 1 entero --> 2 bytes)
¿Cuántos bytes se reservarían para:?
datos: array [1..25] of double;
Para explicar con mayor detalle el concepto de memoria dinámica es necesario conocer el concepto ¡PUNTEROS!
Punteros
¿Qué son los Punteros?
Son tipos de datos simples capaces de almacenar la posición de una variable en memoria principal. Se dice que ellos direccionan a otras variables.
Ejemplo:
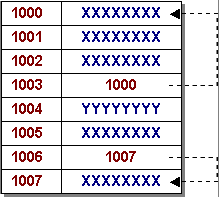
Se dice que las variables ubicadas en las posiciones 1003 y 1006 son punteros, pues direccionan o "apuntan a" las posiciones 1000 y 1007 respectivamente.
Definición de Tipo
Type Puntero = ^TipoDato;
Expresa que los valores de tipo Puntero son punteros a un tipo de dato básico o estructurado
Type puntero = ^Automoviles;
Var pauto1, pauto2: puntero;
Expresa que Puntero un tipo de dato capaz de direccionar al Registro Automoviles (definido en el tópico anterior) y que pauto1, pauto2 son dos variables de tipo puntero)
Asociado al concepto de punteros está el de nodo de memoria que habíamos enunciado en el tema de asignación dinámica. Este nodo cuenta con la siguiente vista gráfica:
![]()
Cuya definición de tipo es:
Type
TAuto=Record
anho:integer;
marca:string[30];
preciobruto:longint;
End;
puntero = ^nodo; {*Expresa que puntero es capaz de direccionar a un nodo.*}
nodo = RECORD; {*Definición del nodo.*}
info:TAuto; {*Contenido informativo*}
sgte:puntero; {*Enlace al sgte. nodo de la estructura*}
End;
Estos nodos de memoria son la base para la construcción de estructuras de datos dinámicas que, como ya recordarán, son aquellas para las cuales no se asigna inmediatamente memoria, en lugar de ello, se utiliza el concepto de asignación dinámica a través de procedimientos incorporados al lenguaje. Así, el campo enlace mostrado en la gráfica direccionará a otro nodo que contiene a su vez información relacionada a un nuevo automóvil y así sucesivamente.
¿Cómo acceder a los campos individuales de un nodo?
Para referenciar a los componentes individuales de un nodo es necesario, sin duda, que exista un puntero libre direcionándolo de manera de hacerlo a través de él.

Para acceder a cada uno de los campos se utiliza la siguiente función de acceso:
NombrePuntero^.nombre del campo
Para este caso:
Inicio^.TAuto.anho : Hace referencia al año de fabricación del vehículo.
Inicio^.TAuto.marca : Hace referencia a la marca del vehículo.
Inicio^.TAuto.preciobruto : Hace referencia al precio del vehículo.
Inicio^.enlace : Corresponde a la posición en MP del próximo nodo de la estructura (conteniendo datos sobre otro vehículo).
Notar que en este caso se hace doble referencia por tratarse de un registro anidado.
Convenciones:
Para Pensar
Investiga con tu grupo de trabajo
¿Cuáles son los procedimientos de asignación dinámica y cómo se utilizan para Lenguaje Pascal y Lenguaje C ?
PILAS O COLAS LIFO
Definición
¿Qué es una Pila?
Imagina un montón de platos "apilados" o bien fichas de dominó formando una torre e intenta eliminar una desde el centro, ¿qué ocurre?, naturalmente esta operación no está permitida si queremos mantener intactos a los platos o a la torre construida. Por esta razón, una pila se asocia a una estructura de datos LIFO (LAST IN FIRST OUT). En base a lo anterior, construye la definición de una PILA y discútela con el profesor.
En general, podemos definir para cada una de las estructuras de datos una representación estática y otra dinámica según el método de asignación de memoria utilizado.
CLASIFICACIÓN
Definición
Pila estática
¿Cómo representar estáticamente una pila?
Sin duda tendremos que utilizar arreglos o registros que como ya sabemos son la base para estructuras de datos más complejas. Considera la siguiente figura:
Vista gráfica

Suponiendo que Dato pertenece a un mismo tipo de datos y CuentaDato corresponde a un entero que se incrementa a medida que un nuevo elemento se incorpora a la pila. Intenta construir la definición de tipo para la estructura Pila.
TYPE
______________________________
______________________________
______________________________
END;
Pila Dinámica
¿Cómo representar dinámicamente una pila?
Sin duda tendremos que utilizar nodos con punteros. Considera la siguiente figura:
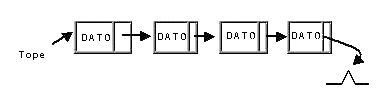
Suponiendo que los punteros que aparecen en la figura son capaces de apuntar a un nodo y que Dato pertenece a cualquiera de los tipos básicos o estructurados, la definición de tipo sería:
TYPE
Puntero=^NodoPila;
NodoPila=Record
Info:AlgunTipo;
sgte:Puntero;
End;
Var tope:Puntero;
Para Pensar
Establece la diferencia entre el puntero tope y el puntero sgte ubicado denntro del NodoPila.
¿Cuál es la relación entre el puntero Tope y el entero CuentaDatos de la representación Estática?
¿Cuáles son los mecanismos de acceso a los datos almacenados en una pila?
Operaciones Básicas
-
Inicialización
-
Verificar si la pila está llena
-
Verificar si la pila está vacía
-
Empilamiento o PUSH
-
Desempilamiento o POP
A continuación presentaremos las operaciones básicas para la representación dinámica de una pila. Haz lo mismo para la estática. Grafica las operaciones a un costado del algoritmo.
procedure InicializaPila(var s: puntero);
begin
s:= nil;
end;
function pilavacia( s: puntero):boolean;
begin
pilavacia:=(s=nil);(La función asume el valor de verdad de la condición*)
end;
function pilallena:boolean;
begin
pilallena:=(sizeof(nodo) >MAXAVAIL);
end;
Donde sizeof(nodo) devuelve el tamaño en bytes que ocupa la estructura del tipo nodo y MAXAVAIL contiene el bloque de tamaño máximo disponible para ser asignado.
procedure push (var s: puntero; nuevoelemento:tipo);
var p:_puntero;
begin
if not pilallena(s) then
begin
new(p);
p^.info := nuevoelemento;
p^.sgte:= nil;
if pilavacia(s) then(*Creando el primer nodo de la pila*)
s:=p;
end
else(*Anexando un nuevo nodo a la pila*)
p^.sgte:=s;
s:=p;
end;
else write ('Overflow');
end;
procedure pop (var s: puntero; var viejoelemento:tipo);
var p:puntero;
begin
if PilaVacia(s) write('Underflow')
else
begin
viejoelemento:= s^.info;
p:= s;
s:= s^.sgte;
dispose(p);
end;
End;
Un concepto por introducir es el de encapsulamiento, que significa que una vez definida la estructura e implemetadas las operaciones básicas, uno se remite a utilizarlas sin importar su codificación interna, es decir, las llamadas a PUSH(pila, x) o POP(pila, y) empilarán a x o desempilarán en y sin importar cómo lo hagan.
Investiga que mecanismo ofrecen los lenguajes para implementar el concepto de encapsulamiento.
Listas Enlazadas
¿ Qué es una lista enlazada ?
Corresponde a una estructura lineal compuesta por una colección de datos homogéneos con alguna relación entre ellos. Dicha estructura se crea a través del método dinámico de memoria.
En una lista enlazada el orden de los elementos está determinado por un campo enlace (puntero) explícito en cada elemento, por ejemplo: pilas y filas dinámicas.
La representación de lista enlazada es la más óptima debido a que cualquier proceso de actualización (modificación inserción o eliminación) se realiza en base a reasignación de punteros. En este capítulo trataremos sólo con las listas enlazadas ya que las listas secuenciales ya son bien conocidas por ustedes.
Tipos de Listas Enlazadas
-
Listas lineales simplemente enlazadas
-
Listas Circulares
-
Listas doblemente enlazadas
-
Listas múltiplemente enlazadas
Listas Simplemente Enlazadas
Una lista lineal simplemente enlazada es una estructura en la que el cada elemento enlaza con el siguiente. El recorrido se inicia a partir de un puntero ubicado al comienzo de la lista. El último elemento (nodo) de la lista apunta a una dirección vacía que indica el fin de la estructura.
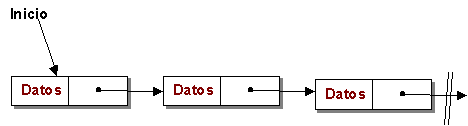
Donde p=^Nodolista (apunta al sgte. nodo de la lista)
Definición de tipo Lista simplemente enlazada
Type
puntero = ^NodoLista;
NodoLista = Record
info: AlgunTipo;
siguiente: puntero;
end;
Cabe destacar que en una lista lineal enlazada, sólo es posible acceder a los elementos sucesores pero no antecesores, además, siempre es necesario mantener un puntero a la cabeza de la lista para acceder a los demás elementos
Listas Circulares
Una lista circular es una lista lineal en la que el último elemento enlaza con el primero. Entonces es posible acceder a cualquier elemento de la lista desde cualquier punto dado.
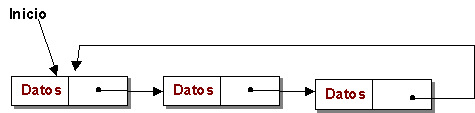
Donde p=^Nodolista (apunta al sgte. nodo de la lista)
La definición de tipo es equivalente a la anterior sólo se debe modificar la dirección a la que apunta el enlace ubicado en el último nodo.
Las operaciones sobre una lista circular resultan más sencillas. Cuando recorremos una lista circular, diremos que hemos llegado al final de la misma cuando nos encontremos de nuevo en el punto de partida; suponiendo que en este punto se deja un puntero fijo. Otra solución al problema anterior sería ubicar en cada lista circular un elemento especial identificable, como lugar de parada. Este elemento especial recibe el nombre de cabeza de la lista. Esto presenta la ventaja de que la lista circular no estará nunca vacía.

Ejemplo:
Realizaremos la suma de ecuaciones algebraicas o polinómicas de las variables x, y, z. Por ejemplo:
(2x3y + 4xy3 - y4 ) + ( 2xy3 - xy)
Cada polinomio será representado como una lista cuyos nodos representan los términos no nulos, como se indica a continuación:
| Coeficiente | ||||
| ± | A | B | C | p |
Donde coeficiente corresponde al coeficiente del término xAyBzC. suponiendo que los coeficientes y exponentes están dentro de los rangos permitidos. La notación A B C se utilizará para representar el campo ABC de cada elemento tratado como un número entero. El ABC y Exponente serán siempre positivos, el campo signo indicará de esta manera el signo de cada término. Los elementos de la lista aparecerán sobre la misma en orden decreciente del campo ABC, siguiendo la dirección de los enlaces. Ahora bien, ¿podría indicar gráficamente como quedaría representado el polinomio (2x3y + 4xy3 - y4) ?
Listas Doblemente Enlazadas
Una lista doblemente enlazada es una lista lineal en la que cada elemento tiene dos enlaces, uno al elemento siguiente y otro al elemento anterior. Esto permite recorrer la lista en cualquier dirección.

Donde p =^Nodolista (apunta al sgte. nodo de la lista)
Donde q =^Nodolista (apunta nodo anterior de la lista)
Definición de tipo Lista Doblemente enlazada
Type puntero = ^NodoLista
NodoLista = Record
info: AlgunTipo;
siguiente: puntero;
anterior: puntero;
End;
Las operaciones sobre una lista doblemente enlazada se realizan sin ninguna dificultad. Sin embargo, casi siempre es mucho más fácil la manipulación de las mismas, cuando se añade un elemento de cabeza y existe un doble enlace entre el último elemento y el primero. Esta estructura recibe el nombre de lista circular doblemente enlazada.
Listas Múltiplemente Enlazadas
Este tipo de listas contiene más de dos enlaces por nodo, los que tienen la posibilidad de apuntar a más de dos listas enlazadas.
Vista gráfica de un nodo
| p | ||
| p | Dato | p |
| p | ||
Donde p=^nodo
Intenta construir su definición de tipo considerando la vista gráfica.
Type
_________________________
_________________________
_________________________
_________________________
_________________________
_________________________
End;
Operaciones Basicas
-
Crear una lista vacía.
-
Recorrer la lista.
-
Buscar un elemento en la lista.
-
Insertar nuevos elementos.
-
Eliminar elementos ya existentes.
Crear una lista
Inicio:=NIL; (*Inicializar Lista*)
Recorrer la Lista
p:=inicio; (*El puntero p es ubicado al principio de la lista*)
while p<>NIL do
begin
write(p^.info); (*Se vacía todo el contenido de la lista por pantalla*)
p:=p^sgte;
end;
Búsqueda de un Elemento
(*Del nodo con info = x*)
p:=inicio;Encontrado:=FALSE;
while (p<>NIL) and (NOT ENCONTRADO) do
begin
if p^.info = x then ENCONTRADO:=TRUE;
p:=p^sgte;
end;
busqueda:= p
Esta función devuelve un puntero a la primera ocurrencia de nodo con campo info = x o en su defecto apuntando a NIL.
Incorporar Elementos
(* Antes del nodo apuntado por inicio*, estrategia LIFO)
new(p); p^.sgte:=inicio;
inicio:= p;
(* En otro punto de la lista, antes de nodo con info=x
y con el puntero p ubicado antes del punto de inserción*)
begin
new(t); t^.sgte:=p^.sgte;
p^.sgte:=t;
end;
(* Después del ultimo elemento*, estrategia FIFO)
p:=inicio;
while (p^.sgte<>NIL) do
begin
p:=p^sgte; (*Ubica a p en el último nodo*)
end;
new(t); t^.sgte:=p^.sgte;
end;
Eliminar Elementos Existentes
(*Nodo con info=x*)
Busqueda(p);(*Deja el puntero p un nodo antes del que será eliminado*)
t:= p^.sgte;
p^.sgte:= t^.sgte;
dispose(t);
(*Verificar si está vacía o llena*)
EstaVacía:= (Inicio=NIL);
EstaLlena:= (sizeof(nodo)>MAXAVAIL);
Esta función devuelve un TRUE o un FALSE dependiendo del valor de verdad de cada expresión
RECURSIVIDAD
Técnica que permite definir un procedimiento o función en términos de sí mismo, en otras palabras, se dice que un subprograma es recursivo si para cumplir su labor realiza una llamada a sí mismo dentro del código. Del latín:
recur
re- = volver (back)+
currere = a ejecutar (to run)
Características
- Cara en términos de tiempo de ejecución, debido a los sucesivos empilamientos de variables y direcciones de retorno.
- En ciertos casos reemplaza a los ciclos repetitivos debido a su caracter sintético.
-
Soportada sólo por lenguajes que manejan asignación dinámica de memoria.
Interatividad V/S Recursividad
El problema del factorial de un Entero + Seguimiento
Problema del FACTORIAL DE UN ENTERO
Solución Iterativa
function factorialIterativa (n: integer): integer;
var
fact, contador: integer ; (*no negativo*)
BEGIN
fact := 1;
for contador := 2 to n do fact : = fact * contador;
factorialIterativa: = fact
END;
Solución Recursiva
function factorialRecursiva (n: integer): integer;
BEGIN
if n=0 then
factorialRecursiva := 1
else (* para N>0*)
factorialRecursiva : = n * factorialRecursiva (n-1)
END;
Seguimiento Iterativo (Factorial)
| n | contador | Fact | Factorial Iterativo |
| 4 | 2 | 1 |
|
|
| 3 | 2 |
|
|
| 4 | 6 |
|
|
|
| 24 | 24 |
Seguimiento Recursivo (Factorial)
| n | salida |
| 4 | 4*fact(3) |
| 3 | 4*(3*fact(2)) |
| 2 | 4*(3*2*fact(1)) |
| 1 | 4*(3*2*1*fact(0)) |
| 0 | 4*(3*2*1*1) |
Problema de la Potencia de 2 numeros enteros positivos + seguimiento
Problema de la POTENCIA pot(a,b)
Solución Iterativa
function PotenciaIterativa (a,b: integer): integer;
Begin
var p:integer;
p:=1;
if b=0 then PotenciaIterativa:= 1
else
begin
for i:=1 to b do p:= p*a
end
PotenciaIterativa:= p
end
End;
Solución Recursiva
function PotenciaRecursiva (a,b: integer): integer;
Begin
var p:integer
p:=1;
if b=0 then PotenciaRecursiva:= 1
else
begin
PotenciaRecursiva:= a * PotenciaRecursiva(a,b-1)
end
End;
Seguimiento Iterativo (Potencia)
| a | b | i | p | Potencia Iterativa |
| 2 | 3 | 1 | 2 |
|
|
|
| 2 | 4 |
|
|
|
| 3 | 8 | 8 |
Seguimiento Recursivo (Potencia)
| a | b | Salida |
| 2 | 3 | 2*pot(2,2) |
| 2 | 2 | 2*(2*pot(2,1)) |
| 2 | 1 | 2*(2*2*pot(2,0)) |
| 2 | 0 | 2*(2*2*1) |
¿Podrán implementarse procedimientos recursivos para resolver ambos problemas? Desarróllalos y coméntalos con el profesor.
¿Cómo verificar una función o procedimiento recursivo?
Metodo de las 3 preguntas
¿Cómo determinar si un problema puede resolverse recursivamente?.
Para verificar funciones y procedimientos recursivos utilizaremos el método de las tres preguntas:
La pregunta caso-base: ¿Hay una salida no recursiva para el procedimiento o función? ¿la rutina funciona correctamente para este caso base?
La pregunta valor más pequeño: ¿Cada llamada recursiva al procedimiento o función se refiere a un caso más pequeño del problema original?
La pregunta caso general: Suponiendo que las llamadas recursivas funcionan correctamente ¿Funciona correctamente todo el procedimiento o función? (puede verificarse a través de un procedimiento)
Para el ejemplo de la función factorial:
Condición caso base : n = 0
Condición caso general: n > 0
¿Funciona correctamente?
Sí, ya lo demostramos.
ÁRBOLES
Introducción
Es una estructura de datos no lineal que posee raíz, ramas y hojas, técnicamente constituye un grafo finito y sin ciclos. Un árbol define ciertos niveles jerárquicos precedidos por la raíz (1er. nivel), en donde las hojas constituyen el nivel más bajo.
Componentes
Raíz: Nodo que constituye la única entrada a la estructura (por ello es necesario tener un puntero sobre él).
Ramas o Arcos: Conexión entre dos nodos del árbol que representa una relación de jerarquía.
Hojas: Nodo sin hijos.
Características
Nivel o profundidad de un nodo: Longitud del camino para ir desde la raíz al nodo. Por definición la raíz está en el nivel 0. Por ejemplo: profundidad(Y)=2, profundidad(raíz)=0, profundidad(árbol)= profundidad(hoja más profunda).

Altura de un nodo: Longitud del camino más largo desde el nodo a una hoja. Por ejemplo:
Altura(X)=1, Altura(Y)=0, Altura(arbol)=Altura(raíz)=profundidad(árbol)
Grado de nodo: Cantidad de hijos de un nodo cualquiera.
Grado de árbol: Cantidad máxima de hijos posibles de asociar a un nodo del árbol
Clasificación
Según Número de Hijos

Según Estructura de Niveles
-
Arbol completo: Es un árbol binario en el cual cada nodo es una hoja o posee exactamente 2 hijos.
-
Arbol lleno: Es un árbol binario con hojas en a lo más dos niveles adyacentes l-1 y l, en las cuales los nodos terminales se encuentran ubicados en las posiciones de más a la izquierda del árbol.

Si un árbol binario es completo, necesariamente es lleno
Según Funcionalidad
-
Arbol binario de búsqueda (ABB)
-
Arbol binario de expresión
Arboles Binarios de Búsqueda
Definición de un ABB
Un árbol binario de búsqueda es un árbol ordenado. Las ramas de cada nodo están ordenadas de acuerdo con las siguientes reglas: para todo nodo X, las claves ubicadas en el subárbol izquierdo son menores que la clave de X, y todas las claves del subárbol derecho de X son mayores que la clave de X.
Un árbol de estas características permite determinar si una clave determinada existe o no, de manera muy simple. Por ejemplo, si observamos la siguiente figura, localizar la clave 12 es aplicar la definición de árbol de búsqueda, esto es, si la clave buscada es menor que la clave del nodo en el que estamos, se recorrerá el subárbol izquierdo o de lo contrario el subárbol derecho. Este proceso continúa hasta encontrar la clave o hasta llegar a un subárbol vacío cuya raíz tiene un valor NIL.

Para Completar

Operaciones Básicas
-
Crear un ABB vacío.
-
Insertar nuevos elementos al ABB.
-
Eliminar elementos ya existentes.
-
Recorrer el ABB.
Definamos en primer lugar la estructura que soportará a este árbol:
------------------------------------------------------------------------
TYPE
TipoPuntero = ^TipoNodoABB;
TipoNodoABB = RECORD
info : TipoInfo;
izquierdo : TipoPuntero;
derecho: TipoPuntero;
End;
------------------------------------------------------------------------
-
Crear un ABB vacío.
Procedure InicializaArbol(var RaizArbol: TipoPuntero);
Begin
RaizArbol := NIL;
End;
------------------------------------------------------------------------
-
Insertar nuevos elementos al ABB.
Procedure Insertar_arbol_binario( var Raizarbol: TipoPuntero;InfoNodo: TipoInfo);
Var
NuevoNodo: TipoPuntero; (*puntero para nodo nuevo*)
Ptr, Anterior:TipoPuntero; (* usado para buscar en el ABB*)
ClaveNueva: TipoClave;(* clave del nuevo nodo a insertar*)
BEGIN
(* Crear un nuevo nodo*)
New(NuevoNodo); NuevoNodo^.izquierdo:= NIL; NuevoNodo^.derecho:= NIL;
NuevoNodo^.info:= InfoNodo;
(* Buscar el lugar de inserción*)
ptr: = RaizArbol; Anterior: = NIL;
While ptr <> NIL Do
begin
anterior : = ptr;
if ptr^.info.clave > ClaveNueva then
ptr := ptr^.izquierdo
else
ptr := ptr^.derecho
end;
if anterior = NIL then
raizarbol = NuevoNodo
else
if anterior^.info.clave > ClaveNueva then
anterior^.izquierdo: = Nuevonodo
else
anterior^.derecho: = Nuevonodo
END;
------------------------------------------------------------------------
-
Eliminar elementos ya existentes.
(a)Eliminación de un nodo hoja sólo consiste en anular el puntero de su nodo padre
(b)Eliminación de un nodo con un hijo, es necesario reasignar el puntero del padre hacia el hijo.
(c)Eliminación de un nodo con dos hijos : Reemplazar el nodo que deseamos suprimir con el nodo de valor más próximo al valor del nodo suprimido. Así será posible hacer el reemplazo por "El mayor más cercano" o "El menor más cercano", dependiendo de qué subárbol sea escogido el nodo.
Procedure Suprimir (Var RaizArbol: TipoPuntero;ValorClave: TipoClave);
(* Suprime el valor que contiene ValorClave del árbol, apuntado por RaizArbol, supondremos que este nodo existe en el árbol*)
Var
ptr, anterior: TipoPuntero;
BEGIN
ptr := RaizArbol; anterior:= NIL;
While ptr ^.info.clave<> ValorClave Do
begin
anterior : = ptr;
if ptr^.info.clave > ValorClave then
ptr := ptr^.izquierdo
else
ptr := ptr^.derecho
end;
(* Suprimir nodo apuntado por ptr*, anterior apunta al padre de este nodo*)
SuprimirNodo(RaízArbol, ptr, Anterior)
END;
Procedure SuprimirNodo (Var RaízArbol : Tipo_Puntero; ptr, anterior: Tipo_ Puntero);
(* Suprime el nodo apuntado por Ptr sobre el árbol binario con puntero RaizArbol, Anterior es un puntero al nodo padre ( NIL si el nodo a suprimir es el nodo Raiz)*)
Var
temp: Tipo_Puntero;
BEGIN
(*Caso b.1 Supresión de una hoja*)
if(ptr^.derecho = NIL) AND (ptr^.izquierdo = NIL) then
IF Anterior = NIL then (*Nodo(ptr) es el último en el árbol)
RaizArbol:= NIL
else
if anterior^.derecho = Ptr then
anterior^.derecho : = NIL
else anterior^.izquierdo: = NIL
else (* Caso b.3 supresión de nodo con dos hijos*)
if(ptr^.derecho <> NIL) AND (ptr^.izquierdo <> NIL) then
begin (* Encontrar el valor para reemplazar, valor más próximo al eliminado*)
anterior: = ptr;
temp := ptr^.izquierdo;
While temp^.derecho<> NIL Do
begin
anterior:= temp;
temp : = temp^.derecho
end;
(* Copiar la información a reemplazar en el nodo*)
ptr^.info:= temp^.info;
if anterior = Ptr then
anterior^.izquierdo:= temp^.izquierdo
else
anterior^.derecho:= temp^.izquierdo;
ptr:= temp;
end
else (* Caso b.2 Nodo con un hijo*)
(* Inicializa uno de los campos punteros de nodo (anterior) dependiendo si el nodo que se está suprimiendo tiene un hijo a la derecha o izquierda*)
if ptr^.derecho <>NIL then (* Hay un hijo derecho*)
if anterior = NIL then
RaizArbol:= Ptr^.derecho
else
if anterior^.derecho=ptr then
anterior^.derecho := ptr^.derecho
else
anterior^.izquierdo := ptr^.derecho
else(* hay un hijo izquierdo*)
if anterior = NIL then
RaizArbol:= Ptr^.izquierdo
else
if anterior^.derecho=ptr then
anterior^.derecho := ptr^.izquierdo
else
anterior^.izquierdo := ptr^.izquierdo;
dispose (ptr);
END;
------------------------------------------------------------------------
-
Recorrer un ABB( extensible a cualquier árbol binario)
Procedure InOrden (ptr: Tipo_puntero);
Begin
(* CASO BASE: SI PTR ES nil, no hacer nada*)
if Ptr <>NIL then
begin(* Caso general*)
InOrden(ptr^.izquierdo);
writeln(ptr^.info);
InOrden(ptr^.derecho);
end
End;
Procedure Preorden(ptr: Tipo_puntero);
Begin
(* CASO BASE: SI PTR ES nil, no hacer nada*)
if Ptr <>NIL then
begin(* Caso general*)
writeln(ptr^.info);
PreOrden(ptr^.izquierdo);
PreOrden(ptr^.derecho);
end
End;
Procedure PostOrden (ptr: Tipo_puntero);
Begin
(* CASO BASE: SI PTR ES nil, no hacer nada*)
if Ptr <>NIL then
begin(* Caso general*)
PostOrden(ptr^.izquierdo);
PostOrden(ptr^.derecho);
writeln(ptr^.info);
end
End;
Arboles de Expresión
Definición
Un árbol de expresión es una estructura que representa una operación aritmética conteniendo dentro de su campo info un operando (numérico) o bien sus operadores asociados.
Si pensamos que los nodos del árbol contienen algunos de los operadores +,-,x y / debemos intuir que se trata de un árbol binario de expresión como el que se indica en la figura:

¿Cómo obtener la expresión aritmética a partir de un AE?
Resp: Recorre el árbol en Inorden y parentiza cada subexpresión así obtendrás lo que necesitas.
ORDENAMIENTO Y BUSQUEDA
Ordenamiento
Un método de ordenamiento consiste en un algoritmo que recibe como entrada a un conjunto de datos que son necesarios de ordenar según cierto(s) criterio(s). El objetivo fundamental de éstos métodos es el de facilitar la búsqueda de datos según estos mismos criterios.
Clasificación de Métodos
Según lugar físico donde residen los datos
-
Ordenamiento Interno: Es aquel que ocurre sobre estructuras de datos residentes en memoria principal. Entre otros se tiene al de Inserción directa, Selección directa, Shell Sort, Bubble Sort, Quick Sort, Merge Sort, Heap Sort.
-
Ordenamiento Externo: Es aquel que ocurre sobre estructuras de datos residentes en memoria secundaria. Entre otros se tiene al método de Intercalación, Mezcla directa, Mezcla Equilibrada.
Segœn movimientos de claves de ordenamiento
-
Ordenamiento Estable: Es aquel que una vez efectuado mantiene el orden relativo de dos o más registros cuyo criterio de ordenamiento es el mismo. Es beneficioso para ordenamientos en donde se utilice más de un criterio de ordenamiento.
-
Ordenamiento No estable: Es aquel que una vez efectuado pierde el orden relativo de dos o más registros cuyo criterio de ordenamiento es el mismo.
Comparación de los Métodos de Ordenamiento
Una alternativa sería comparar tiempos de ejecución, sin embargo, esto sólo sería una medida de eficiencia sobre un computador en particular. (dependiendo la arquitectura de la máquina, set de instrucciones etc.).
Mayor validez tendría aislar la operación básica realizada en el algoritmo y determinar el n° de veces que se realiza. Por ejemplo, si estuviéramos sumandos los elementos de un arreglo podríamos contabilizar el n¼ de operaciones realizadas para un arreglo de tamaño n, así como en este caso el número de operaciones realizadas es función del número de elementos del arreglo.
Usualmente se utiliza la notación O( ) para indicar el grado u orden del algoritmo que está dado en términos de comparaciones realizadas. Esto representa cuantitativamente la complejidad de un algoritmo.
Las complejidades más usuales son O(n), O(n2), O(n3), O(log2n). Para que se entienda mejor:
O(n):LLenar un arreglo lineal
O(n2):Llenar un arreglo bidimensional
O(n3):Llenar un arreglo Tridimensional
O(log2n):Recorrer un árbol binario de búsqueda
Tabla comparativa de eficiencia entre algoritmos de ordenación
| Método de Ordenación | Orden de Magnitud | ||
| Mejor Caso | Media | Peor Caso | |
| Selección directa | O(n2) | O(n2) | O(n2) |
| Burbuja | O(n2) | O(n2) | O(n2) |
| Burbuja_Mejorado | O(n) | O(n2) | O(n2) |
| Ord_Mezcla | O(nlog2n) | O(nlog2n) | O(n2) |
| Ord_Rápida | O(nlog2n) | O(nlog2n) | O(n2) (depende de orden de división) |
| Ord_Shell | O(n2) | O(n2) | O(n2) |
Búsqueda Secuencial
Comenzando desde el inicio de la lista se busca registro a registro (elemento a elemento) hasta encontrar el elemento buscado o en su defecto terminar de revisar toda la estructura. Este tipo de búsqueda es aplicable a listas secuenciales(arreglos) y listas enlazadas.
El siguiente algoritmo realiza la búsqueda de un campo clave sobre un arreglo de registros.
Procedure Busqueda_Secuencial(Lista: Tipo_array;Numelementos: integer; Valclave: Tipo_clave; var posicion: integer);
Var
indice: integer;
Encontrado: boolean;
Begin
Indice:=1; Encontrado:= FALSE;
While NOT ENCONTRADO AND indice <= Numelementos do
begin
if lista[indice].clave = valclave then ENCONTRADO:= TRUE
else indice:=indice+1;
end;
if ENCONTRADO then Posicion :=indice else posicion:=0;
End;
Consideraciones
-
En el peor de los casos, deberíamos buscar en el último registro de la lista o sobre uno no existente. O(N)
-
En promedio, si supusiéramos igual probabilidad de búsqueda para cualquier item, se harían N/2 comparaciones (mitad de la lista)
-
Si la lista estuviese ordenada (en base al campo clave) la eficiencia del algoritmo anterior se vería mejorada ya que detendríamos nuestra búsqueda cuando se haya sobrepasado su posición lógica dentro de la lista.
Búsqueda Binaria
Este tipo de búsqueda se basa en el hecho que la estructura se encuentra originalmente ordenada en base a su campo clave. La idea es la siguiente: Si deseamos buscar al un tal Sr. Donoso, abriremos la guía, supuestamente en la mitad y al notar que los nombres empiezan por M, que es mayor que D, haremos una búsqueda binaria desde A hasta M, con ello, volvemos al punto medio y por el hecho que los nombres empiezan con G, que es mayor que D, rehacemos la búsqueda binaria entre A y G. Este tipo de búsqueda es aplicable a estructuras estáticas como los arreglos y dinámicas como los ABB.
------------------------------------------------------------------------
Procedure Busqueda_Binaria(Lista: Tipo_array;Numelementos: integer; Valclave: Tipo_clave; var posicion: integer);
Var
indice: integer;
puntomedio, primero, ultimo: integer;
Encontrado: boolean;
Begin
ENCONTRADO:= FALSE; primero:= 1;ultimo:= numelementos;
While (primero<= ultimo) AND NOT ENCONTRADO do
begin
puntomedio:=(primero+ultimo) DIV 2;
if lista[puntomedio] = valclave then encontrado:= TRUE
else
begin
if lista[puntomedio] > valclave then ultimo:=puntomedio-1
else primero:= puntomedio +1;
end;
end;
if ENCONTRADO then Posicion :=puntomedio else posicion:=0;
End;
Búsqueda Hash
¿Cómo poder mejorar la eficiencia de los algoritmos antes mencionados?, ¿será posible encontrar un algoritmo más eficiente que de O(log2 n) ? Supongamos que se tiene una lista de empleados con el campo RUT como clave ¿sería factible tener un arreglo con 15.000.000 posiciones?.
Lo lógico sería tener un arreglo con el tamaño realmente necesario (por ejemplo 0..99) y ordenar los elementos en base a los dos últimos dígitos del RUT. Por ejemplo, al empleado con RUT 10905867 le correspondería la posición 67 del arreglo y a otro con RUT 18632655 la posición 55. De esta forma, sería posible decir que los elementos se encuentran ordenados en base a una función aplicada sobre el campo clave. Dicha función tiene dos objetivos, el primero: ser utilizada como un medio de direccionamiento mediante la cual es posible ordenar la lista (es decir, decidir en qué lugar del arreglo se almacenará un elemento determinado) y el segundo: ser utilizada como método de acceso al registro. A esta función se le denomina Función HASH o de Hashing, para el caso anterior la función sería f(clave) = clave MOD 100, donde el remanente del cuociente entre la clave y 100 genera la posición de almacenaje.


Las funciones de Hashing más comunes utilizan el método de la división (MOD) para calcular las direcciones transformadas. La forma general es:
DireccionHash := Clave MOD TamañoLista
(o DireccionHash := Clave MOD (tamañoLista+1)) cuando el índice de la tabla comienza en 1 y no en 0)
Otro método más sofisticado es dividir la clave, en notación binaria, en varios trozos y concatenarlos mediante un XOR (OR exclusivo). Supongamos que deseamos construir una función de HASH que nos genere índices entre 0 y 255 y la representación interna de la clave es de 32 bits., se necesitan 68 bits para representar los 256 valores de índices. Por ejemplo, para la clave 618403, cuya representación binaria es 00000000000010010110111110100011, dividiéndola en grupos de 8 bits se obtendría:
00000000
00001001
01101111
10100011
O exclusivo entre la primera y la última, las centrales y los resultados de éstas resulta 11000101 que representa el número decimal 197, por lo cual se transforma en el índice 197.
-
Colisiones
Cabe destacar que este esquema no garantiza unicidad de índices ya es posible que para dos RUT distintos la función devuelva la misma posición dentro del arreglo de registros. A este problema se le denomina colisión, en la práctica es imposible evitarla en un 100%, sin embargo, es posible minimizarlas y manejarlas.
-
Aumento tamaño de la estructura
Una de las formas que se tiene para minimizar las colisiones es utilizar una estructura de datos que tenga más espacio que el realmente necesario, con la intención de ampliar la función de hashing. Por ejemplo si se mantiene e una serie de registro sobre un arreglo que contiene el doble de espacio que empleados, se tendrán la mitad de colisiones que si se tuviera la misma cantidad. (Otra de las formas de minimizar estas colisiones es cuando el tamaño de la lista es primo.)
-
Encadenamiento
Otra solución es mantener por cada elemento un puntero para generar (eventualmente) una lista enlazada con todos aquellos elementos para los cuales la función Hash devuelve la misma posición. (Se debe mantener un arreglo de punteros)

-
Rehashing
Una tercera solución llamada Rehashing, se utiliza una dirección transformada como entrada a la función Rehash y se calcula una nueva dirección. Si [clave mod 100]está ocupada, podemos utilizar la función (Direccion +1) mod100 para producir una nueva dirección. En nuestro primer ejemplo la clave 10567804 genera la dirección 4 que ya se encuentra ocupada, así, aplicando la función Rehash (04+1) MOD 100 =5, si está desocupado almacenamos el nuevo elemento allí sino nuevamente utilizamos la función Rehash con entrada 5. Para la función Rehash podemos utilizar:
(clave +constante) MOD numero de espacios
Mientras constante y números de espacios sean primos entre sí (1 como único divisor común) esta función producirá sucesivas transformaciones que cubrirán eventualmente todo el arreglo.
ARCHIVOS
Introducción
Definición y Componentes
Es una es estructura de datos que reside en memoria secundaria o almacenamiento permanente (cinta magnética, disco magnético, disco óptico, disco láser, etc.). La forma de clasificación más básica se realiza de acuerdo al formato en que residen estos archivos, de esta forma hablamos de archivos ASCII (de texto) y archivos binarios. En este capítulo nos centraremos en estos últimos.
Definición archivo binario:
Estructura de datos permanente compuesto por registros (filas) y éstos a su vez por campos (columnas). Se caracteriza por tener un tipo de dato asociado, el cual define su estructura interna.
Definición archivo texto:
Estructura de datos permanente no estructurado formado por una secuencia de caracteres ASCII.

Ejemplo: Definición y creación de un archivo en Pascal.
Type {Definición de la estructura del registro}
Reg_archivo = Record
Key : Integer; {Campo clave o identificador}
data : String[20] ;{Campo de datos}
End;
Var
R : reg_archivo; {Declaración de variables asociadas al archivo}
A : File of reg_archivo; {Nombre lógico del archivo}
Program prueba;
Type
Reg_archivo = Record
Key : Integer;
Data : String[20];
End;
Var
R : reg_archivo;
A : File of reg_archivo;
I : Integer;
Begin
Assign(a,'archivo.dat'); {se asigna el nombre lógico `a' al archivo}
Rewrite(a); {se crea el archivo, si éste existe borra el contenido, dejándolo listo para el ingreso
registros}
For i:= 1 to 10 do
Begin
Write('ingrese clave ',i:2,':');
readln(r.key);
Write('Ingrese datos: ');
readln(r.data); {se ingresa la información correspondiente al registro utilizado por el programa}
write(a,r) {se `traspasa' el registro al archivo definido (al buffer asociado)}
End;
reset(a); {se posiciona un puntero en el primer registro del archivo}
For i:= 1 to 10 do
Begin
read(a,r); {se lee del archivo a el registro indicado por el puntero, traspasando los datos
al registro r y el puntero avanza al siguiente registro}
writeln(r.key,' ',r.data);
End;
close(a) {se `cierra' el archivo traspasando, si fuera necesario, el buffer al archivo}
End.
Investiga otras funciones y procedimientos para el manejo de archivos.
Tipos de Acceso a los Archivos
Secuencial
Se accesan uno a uno los registros desde el primero hasta el último o hasta aquel que cumpla con cierta condición de búsqueda. Se permite sobre archivos de Organización secuencial y Secuencial Indexada.
Random
Se accesan en primera instancia la tabla de índices de manera de recuperar la dirección de inicio de bloque en donde se encuentra el registro buscado. (dentro del rea primaria o de overflow). Se permite para archivos con Organización Sec.Indexada.
Dinámico
Se accesan en primera instancia la tabla de índices de manera de recuperar la dirección de inicio de bloque en donde se encuentra el registro buscado. (dentro del rea primaria o de overflow). Se permite para archivos con Organización Sec.Indexada.
Directo
Es aquel que utiliza la función de Hashing para recuperar los registros. Sólo se permite para archivos con Organización Relativa.
Clasificación de los Archivos Según su Uso
La siguiente tabla resume las distintas denominaciones dadas a los archivos según la utilización dada:
| Tipo | Definición | Ejemplo |
| Maestros | Perduran durante todo el ciclo de vida de los sistemas. | Archivo de empleados en un sistema de Remuneraciones. |
| Transaccionales | Se utilizan para actualizar otros archivos. Pueden ser eliminados al término de este proceso o conservados como respaldos. | Archivo de ventas diarias en un sistema de ventas. |
| De respaldo | Son copias de seguridad de otros archivos |
|
| De paso | Son creados y eliminados entro de un proceso computacional. |
|
| Históricos | Registran acontecimientos a través del tiempo. | Registros de movimientos diarios de CC en un Sistema Bancario de CC. |
| De referencia | Corresponden a los archivos de consultas de parámetros. | Registro % imposiciones % descuentos isapre, etc. |
| Informes o Reportes | Son respuestas del sistema computacional cuyos contenidos deben ser interpretados por personas. Pueden ser en forma escrita, por pantalla e incluso hacia algún archivo con formato editable. | Planillas de sueldos en un sistema de Remuneraciones. |
Organizaciones Básicas de Archivos
Secuencial
Es la organización más común. Los registros se almacenan uno tras otro por orden de llegada. Para accesar un registro determinado se deben leer todos los registros que están almacenados antes que él.
Se recomienda: para archivos de procesamiento batch (aquellos para los cuales se debe realizar la misma operación sobre la mayor parte de sus registros)
Secuencial Indexada
Los registros son almacenados en una distribución tal que permiten ser consultados a través de índices. En ellos se distinguen 3 áreas de almacenamiento:
1.De índices: Mecanismo de acceso a los registros de datos.
2.Primaria o de datos: En donde se encuentran los datos propiamente tal.
3.De overflow: Encargada de recibir aquellos registros que no pueden ser almacenados en el área primaria.
Se recomienda : Para archivos de consulta
Relativa
Existe una relación directa entre la ubicación lógica de un registro y su ubicación física. Para ello necesita una función matemática que asigne a un valor de clave una dirección física única. El encontrar una Fh óptima es tarea compleja por lo que esta organización es poco utilizada.
Se recomienda: Para archivos en donde sea crucial minimizar tiempos de acceso.
Operaciones Básicas de Archivos
Consiste ordenar el archivo a partir de uno o más criterios impuestos sobre sus campos. Es normal que los archivos estén ordenados por clave o por algún campo alfabético ascendente o descendentemente
Concatenación
Consiste en unir 2 ó más archivos en uno (uno a continuación del otro).
Antes de...


Después de...

Intercalación
Consiste en generar un archivo ordenado según algún criterio preestablecido a partir de dos ó más archivos que pueden o no encontrarse en la misma secuencia.
Antes de...


Después de...

Pareamiento
Consiste en ubicar registros correspondientes entre 2 ó más archivos. Consiste en ubicar aquellos pares de registros pertenecientes a dos archivos diferentes que cumplen una cierta relación de correspondencia.
Edición
Consiste en preparar los datos que constituyen a uno ó más archivos para que sean interpretados por personas. Se asocia generalmente a la generación de listados en papel impreso.
Validación
Consiste en asegurar la veracidad e integridad de los datos que ingresan a un archivo. Existen numerosas técnicas de validación tales como: Dgito verificador, chequeo de tipo, chequeo de rango.
Actualización
Consiste en agregar y eliminar registros desde un archivo, así como también modificar el valor de uno ó más campos. También se conoce como mantención de uno o más archivos.
Bases de Datos
-
Una base de datos es un conjunto de archivos o tablas relacionadas almacenados en forma estructurada. Está formada además por consultas e índices.
-
Existen ciertos enfoques para el diseño de BD: Relacional, Jerárquica y de Red.
-
Las aplicaciones que permiten administrar una base de datos se denominan DBMS (Data Base Manager System), entre ellos podemos citar a: Access, SQL Server, ORACLE Server etc. Estas œltimas se conocen también como RDBMS (Relational Data Base Manager System) ya que siguen el enfoque relacional.
-
En empresas de gran envergadura, se habla de Base de Datos Corporativa conformada por múltiples modelos de bases de datos pertenecientes a distintas instancias e interrelacionados entre sí.
-
En general, el diseño de las bases de datos se rige según ciertas normas, algunas creadas por E. Codd permiten evitar redundancias, e inconsistencias como consecuencia del proceso de actualización. Estas reglas son las denominadas FORMAS NORMALES.
Ejemplo: Esquema físico relacional

P: Primary Key
F: Foreing Key
Notar que existe una relación entre las tablas reparación y producto representada la tabla relación prod_reparpor, debido a que en una reparación se pueden utilizar varios productos como insumos y éstos a su vez pueden participar en más de una reparación.
Formas Normales
Las formas normales definidas en la teoría de bases de datos relacionales representan lineamientos para el dise-o de registros. Las reglas de normalización estón dirigidas a la prevención de anomalías de actualización y de inconsistencias en los datos. Ellas no reflejan ninguna consideración de rendimiento. En cierta forma, pueden ser visualizadas como orientadas por el supuesto de que todos los campos no-clave serán actualizados frecuentemente. No hay obligación de normalizar completamente todas las relaciones cuando se deben considerar aspectos de rendimiento (tiempo de acceso por consulta).
Finalmente, podemos decir que estas formas normales también son aplicables al diseño de archivos tradicionales con clave, con lo que abarcaríamos todos los sistemas.
Aquí enunciamos las 2 primeras FN:
PRIMERA FORMA NORMAL: Bajo la primera formal normal, todas las ocurrencias de un registro deben contener el mismo número de campos. La primera forma normal excluye campos de repetición variable.
Ejemplo: Archivo = LIBROS Registro = Reg_libros
| Cod_lib | Nom_lib | Autor | Num_cop | Materia | Idioma | Precio |
Este registro transgrede la primera forma normal, debido a que pueden existir varios autores para un mismo libro (igual sucede con el campo materia). Una solución a este problema separa los campos "conflictivos", agrupándolos en otras tablas:
| Cod_lib | Nom_lib | Num_cop | Materia | Idioma | Precio |
|
|
| Cod_lib | Autor |
SEGUNDA FORMA NORMAL: Todo campo no clave debe depender directamente del campo clave.
Ejemplo:
| Articulo | Bodega | Cantidad | Direc_bod |
La clave está compuesta de 2 campos ARTICULO y BODEGA, sin embargo, DIRECCION-BODEGA, está relacionado exclusivamente con BODEGA. Los problemas básicos de diseño son: La dirección de la bodega se repite en cada registro para cada parte almacenada en esa bodega (redundancia).Si la dirección de la bodega cambia, cada registro que se refiera a una parte almacenada en esa bodega debe ser actualizado. Debido a la redundancia, los datos pueden llegar a ser inconsistentes, con diferentes registros indicando diferentes direcciones para la misma bodega (integridad). Si en algún momento no hubiera partes almacenadas en alguna bodega, no habría un registro para anotar la dirección de la bodega (anomalía).
BIBLIOGRAFÍA
Utilizada
-
Susan Lily & Nell Dale, Estructuras de Datos, Mc Graw Hill, 1995
-
Cairó & Guardati, Pascal y Estructuras de Datos, Mc. Graw Hill 2» edición, 1989
-
Niklaus Wirth, Algoritmos + Data Structures = Programs, Prentice Hall, 1976
-
Joyanes, Programación en Turbo/Borland Pascal 7, 3» Edición, 1997
Recomendada
-
Susan Lily & Nell Dale, Estructuras de Datos, Mc Graw Hill, 1995
-
Luis Joyanes, Problemas de Metodologías de Programación 2a edición, Mc. Graw Hill, 1989
-
Cairó & Guardati, Pascal y Estructuras de Datos, Mc. Graw Hill 2a edición, 1989
-
Niklaus Wirth, Algoritmos + Data Structures = Programs, Prentice Hall, 1976
-
Joyanes, Programación en Turbo/Borland Pascal 7, 3a. Edición, 1997
INTERNET
[Estructuras de Datos en general]
-
http://dgicii.mty.itesm.mx:8095/%7Empadilla/Estructura/abstrac.htm
-
http://guiafe.com.ar/aedd/teoria.htm
-
http://www.programmersheaven.com/
[Estructuras de Datos PILAS y FILAS]
-
http://dgicii.mty.itesm.mx:8095/%7Empadilla/Estructura/EJ_PILAS.HTM
[Recursividad]
-
http://dgicii.mty.itesm.mx:8095/%7Empadilla/Estructura/recursiv.htm
-
http://193.145.249.7/Informat2/clases/list_vincs/sld0003.htm
[Arboles Binarios]
-
http://dgicii.mty.itesm.mx:8095/%7Empadilla/Estructura/EJ_ARBIN.HTM
[Ordenamiento]
-
http://dgicii.mty.itesm.mx:8095/%7Empadilla/Estructura/sorts.htm
-
http://www.cc.ece.ntua.gr/%7Egkaval/applets/sortdemo.html
Glosario
a
ASCII: "Código Americano de Normalización para el Intercambio de Información". Un sistema de
codificación para convertir caracteres del teclado e instrucciones en el código de número binario, el que entiende el computador.
b
Biblioteca: Es el archivo que contiene las funciones estándares que se pueden usar en los programas. Estas funciones incluyen todas las operaciones de entrada/salida (E/S), manejo de pantalla en modo texto o modo gráfico así como otras rutinas útiles.
Bit: La porción más pequeña de información "representable" en un computador. Es un 0 ó 1. Mediante el lenguaje de los computadores se interpretan series de 1 y 0's para formar símbolos, signos de puntuación, caracteres y números.
Byte: Corresponde a un set de 8 bits que representa un caracter de dato. Es la unidad más pequeña "referenciable" en un computador.
c
Caché: Una porción de memoria en donde se ubica la información utilizada con mayor frecuencia para permitir un acceso más rápido.
CASE: "Computer Aided Software Design". Herramienta Computacional que apoya a alguna de las fases del desarrollo del Sw
Chip (o Ship): Pastilla de silicona quer contiene circuitos eléctricos en miniatura que pueden almacenar millones de bits de información.
Ciber Espacio: Parte de la sociedad y cultura humana que existe en los sistemas de computadores conectados en red, a diferencia de las comunidades con una ubicación física definida.
Cliente: Usuario de una aplicaciíon en red ejecutada desde un servidor. Una arquitectutra cliente servidor permite un gran número de individuos conectados a la vez. El componente principal de programa reside en un servidor centralizado, con componentes más pequeños (interfaz del usuario) en cada cliente.
Código Fuente: Es el texto que un usuario puede leer. Normalmente considerado como el programa.
Código Objeto:Es la traducción del código fuente de un programa a código máquina, que es el que la Computadora puede leer y ejecutar directamente. El Código Objeto es la entrada al enlazador.
Cuadro de diálogo: Ventana que aparece y requiere entrada de datos por parte del usuario (las más básicas muestran sólo un mensaje). Cuando el usuario completa la información necesaria o hace click en los botones correctos, el cuadro de diálogo desaparece.
d
DML: Data Manipulanting Language. Lenaguaje provisto por los Administradores de bases de Datos para la manipulación de las tablas que conforman una Base de Datos.Por ejemplo: SQL
Dominio: En Internet, conjunto de computadores cuyos nombres comparten sufijo común, el nombre del dominio. (Lo que est· despuÈs de la arroba en una direcciÛn de correo electrÛnico). Por ejemplo:
...@duoc.cl, ..@ing.udec.cl, ..@sunderland.uk
DVD (Digital Video Disk): Disco digital de capacidad 7 veces al de un CD convencional.
e
Eficacia:Se dice que un proceso es eficaz, si capaz de cumplir sus objetivos.
Eficiencia:Se dice que un proceso es eficiente, si es eficaz y adem·s utiliza una mÌnimo de recursos.
Enlazador: Es un programa que enlaza funciones compiladas por separado para producir un solo
programa (Combina las funciones de biblioteca est·ndar con el cÛdigo que se ha escrito). La salida del Enlazador es un programa ejecutable.
E-mail: Mensajes, memos, carta, enviados electrÛnicamente entre los computadores conectados en red que pueden estar a lo largo de la oficina o alrededor del mundo.
f
FTP (File Transfer Protocol): "Protocolo de Transferencia de Archivos". Mecanismo para descargar archivos desde Internet.
g
Giga Byte (GB): 1024 x 1024 x 1024 bytes
h
HTML (Hipertext Markup Language) Lenguaje estándar para la creación de documentos en World Wide Web.
l
Identificador :Nombre asignado a una variable, procedimiento o función dentro del código fuente.
IEEE:Instituto de Ingenieros ElÈctricos y Electrónicos. Reconocido por el desarrollo de estándares para la industria de la electrónicia y comunicaciones.
m
Mega Byte (MB): 1024 x 1024 bytes.
MICROSOFT Una de las más grandes compañías editoras de software, fundada en 1975 por Bill Gates. Creadora de Windows, Word, Excel y otras maravillas.
MICROSOFT WINDOWS 98 Sistema operativo basado en microprocesadores Intel 80386DX, 486 y Pentium. Está diseñado para correr aplicaciones de Windows, incluyendo aplicaciones multimedia. Con un diseño GUI (graphic user interface), permite un fácil mantenimiento y uso. Entre otras, algunas de sus innovaciones son los nombres largos de archivos, sistema de fólders y discos de 32 bits, soporte para el Microsoft Network e Internet y atributos generales de protección para el disco duro. Como ayuda para la complicada tarea de instalar nuevos
componentes de hardware, Windows 95 usa los atributos del Plug and Play que permiten una instalación y configuración casi automática de accesorios compatibles.
MODEM: Aparato que le permite a una computadora comunicarse con otras a través de la línea telefónica. Pueden ser internos y externos. Los internos se encuentran dentro de las computadoras y usted conecta la línea telefónica a la parte trasera.
MULTIMEDIA:Tecnología que combina sonido, textos, gráficos y animación en su computadora.
o
Online: Disponible al "instante" desde un computador al cual se está conectado. Por Ejemplo, la ayuda en línea es información acerca de un tópico que se puede obtener de inmediato en una ventana en vez de consultar un manual físico.
OOP (Object oriented programming)La programación orientada a objetos es una modalidad de programación usada para escribir programas como una colección de módulos y objetos. En lugar de escribir los programas línea por línea, se esciben programas con módulos prescritos. Los módulos disimulan la complejidad del lenguaje de programación y facilitan el proceso de copiar las instrucciones de un programa a otro. A pesar de que la programación orientada a objetos es mucho más sencilla de aprender y aplicar que otros lenguajes, es común que estos programas sean un poco más lentos, aunque con las rápidas computadoras de hoy, la diferencia en velocidad cada vez es menos notoria.
OS/2Siglas para Operating System/2. Este sistema operativo fue desarrollado originalmente por Microsoft e IBM en 1987, pero ahora es controlado por IBM. OS/2 cuenta con una interfase gráfica muy similar a la de Windows; también opera DOS y aplicaciones de Windows, además de programas diseñados expresamente para OS/2; y es un sistema apto para el uso de redes. Además, para computadoras 386 y 486, toma ventaja de algunos recursos para darle mayor velocidad cuando hay varios programas abiertos. A pesar de su excelencia tecnológica, OS/2 aún está muy retrasado con respecto a Windows y al parecer ahí se quedará.
p
Portabilidad [Transportabilidad]: Capacidad que tiene un programa o lenguaje para ser cambiado de plataforma con el mínimo núemro de modificaciones. Tiene relación directa con la independencia que posee el lenguaje de la máquina.
Programación modular: Los programas complejos se descomponen en módulos (partes independientes), que estos a su vez se analizan, codifican y se verifican por separado. Su codificación se realiza mediante programación estructurada u orientada al objeto.
PALETA: Es un programa gráfico, la paleta es el menú de colores o de patrones para colorear que se ofrece para que el usuario elija al dibujar o diseñar.
PANEL DE CONTROL: En plataforma Windows de Microsoft y en Macintosh, se refiere a una ventana en la cual se pueden hacer selecciones sobre ciertas características del ambiente en el que se trabaja. Por ejemplo, definir el color del fondo en la pantalla o la velocidad del cursor, así como elegir qué figuras queremos que aparezcan en el monitor mientras la computadora está prendida en los momentos en que no estamos trabajando.
PATH: Un mapa que le dice a su computadora dónde encontrar cierta información. Usando el sistema operativo DOS, usted puede utilizar esta instrucción para ejecutar un programa desde cualquier directorio sin necesidad de hallarse físicamente en el directorio donde se encuentra el programa.
PIRATERÍA: El uso de una copia de un programa sin la autorización de las compañías que lo desarrollaron. En Estados Unidos es una actividad muy penalizada; pero en México es una de las más comunes.
PLUG AND PLAY: Diseño de tecnología de software y hardware que permite añadir dispositivos a una computadora sin mucha complicación para el usuario. Si alguna vez has integrado un módem, un escáner, una tarjeta de audio o algún otro dispositivo a tu computadora, sabes la serie de problemas con los que te puedes enfrentar. Con esta tecnología del plug and play, conectas el dispositivo y la computadora por sí sola define todos los detalles para hacerlo funcionar.
POSTCRIPT: Es un “lenguaje de descripción de página” (PDL) creado por Adobe Systems para controlar la impresión de texto y de gráficas. Al utilizarlo el usuario procede como lo haría normalmente: selecciona estilos, mide los textos, elabora dibujos, etc. El sistema postscript trabaja automáticamente creando las instrucciones necesarias para formar todos los caracteres y la información gráfica. Otra ventaja importante de los programas postscript es que los archivos que ahí se trabajan son compatibles con un gran rango de impresoras. Esto permite al usuario llevar sus archivos a imprimir, en algún servicio externo de impresión, con alguna resolución que quizás él no pueda obtener en su propia impresora.
POWER MACINTOSH: Cualquier computadora Macintosh que use el microprocesador PowerPC, como la PowerPC 601.
PPM (Páginas por minuto): Unidad usada para medir la cantidad de páginas que una impresora es capaz de imprimir por minuto. Ocho páginas por minuto es buen número.
PROGRAMAS DE UTILERIAS (Utilitarios): Son programas auxiliares que ayudan a manejar archivos, a obtener información acerca de la computadora, a diagnosticar o reparar fallas comunes, o bien a mantener el sistema
operativo operando eficientemente. Los programas más populares de este tipo son el PC Tools y el Norton Utilities.
PROGRAMA RESIDENTE EN MEMORIA: Conocido también como TSR (Terminate-and-stay-resident program), es un programa que se mantiene abierto aunque no se esté utilizando y que permite abrir otro encima de él. Cuando este segundo programa se abre, sólo una porción pequeña del que ya estaba siendo utilizado ocupa memoria. Para cambiar de programas, es necesario oprimir algunas teclas designadas, por lo general ALT o CONTROL.
PROTECCIÓN CON CLAVE DE ACCESO Un método para limitar el acceso a un determinado programa, archivo, computadora o red que requiere de proporcionar una clave para poder entrar. Pero asegúrese de llevar un registro de sus claves de acceso, pues muchos usuarios han perdido trabajos completos porque han olvidado su palabra clave.
PROTOCOLO:Normas y estándares para transferir información entre computadores conectados en red.
PRUEBA ALFA: El primer paso de prueba de verificación para productos de cómputo antes de que éstos sean lanzados al mercado. Normalmente, los fabricantes de equipo o bien los encargados de la mercadotecnia de los programas son los responsables de llevar a cabo estas pruebas. Más adelante, se aplica la prueba beta en la cual ya participa un grupo seleccionado de usuarios.
PUERTO PARALELO: Conección en la parte trasera de su computador en donde por lo general se instala la impresora. La computadora trasmite datos a mayor velocidad a través de este puerto.
PUERTO SERIAL: Otra conección menos veloz, pero que permite trasmitir a distancias mayores por medio de un cable.
r
RAM (random access memory): Cuando usted carga un programa o abre un archivo, la computadora lee la información del disco y la copia en la memoria gracias a este acceso; luego utiliza la información en RAM para interpretar y dar salida a los comandos que se le solicite. La memoria RAM está hecha de chips que guardan la información. Esta se conserva, si no se grava la información, sólo mientras la computadora esté encendida.
RED: Dos o más computadoras unidas por un cable que permite el intercambio de información. Existen dos tipos de redes: LAN (Local Area Network), en donde las computadoras se encuentran en una misma oficina o edificio, y WAN (Wide Area Network), donde las computadoras pueden encontrarse a miles de kilómetros de distancia.
RESOLUCIÓN: Término que se refiere a la calidad en las impresiones y en el monitor. El texto y las imágenes en el monitor y en las hojas impresas consisten en modelos compuestos por puntos. Por lo general, mientras más puntos por pulgada (DPI) tenga un documento, mayor la resolución y más nítida la imagen. Por ejemplo, una impresora que imprime a 180 puntos por pulgada, tendrá menor resolución que una de 600 puntos.
RESPALDAR: Copiar archivos normalmente de un disco duro a cualquier tipo de diskette o cinta. Si los archivos originales se dañan por alguna causa, se pueden usar estos respaldos para restaurarlos a su condición original; por eso es importante tener respaldos actualizados. Algunos programas crean automáticamente copias que respaldan los archivos del usuario. Estos respaldos tienen la extensión .bak o .bk! Se graban en el mismo drive y directorio que los archivos originales
RUIDO: Señales indeseadas que interfieren con la comunicación entre hardware y software. El ruido en las computadoras es el equivalente al sonido de estática que se puede escuchar en la radio. Estos sonidos interfieren con lo que no se quiere escuchar, de la misma manera en que el RUIDO, por ejemplo, dificulta la trasferencia de archivos por vía telefónica o a través de los cables de una red de computadoras.
s
SERVIDOR: Es el computador central de una red que está instalada exclusivamente para alimentar de programas y de información a las "computadoras clientes" que conforman dicha red. Normalmente es la computadora más grande y con más potencia de toda la red.
SHAREWARE: Programas que pueden ser probados de manera gratuita durante un periodo determinado. Después de ese lapso, el usuario está obligado legalmente a adquirir el programa si desea continuar usándolo.
SÍNDROME DEL TÚNEL CARPIANO: Enfermedad de reciente aparición que afecta las muñecas a causa del repetitivo tecleo en la computadora. Quienes usamos constantemente un teclado corremos el riesgo de desarrollar esta lesión. Se puede prevenir haciendo constantes pausas durante el trabajo o usando teclados y aditamentos más cómodos.
Sistema Operativo (S.O.): Programa especializado que tienen por objeto tender un puente entre el Hw y el Sw de la máquina. Dentro de sus funciones principales se tienen: Definir la interfaz de usuario y Administrar la CPU y memoria. Ejemplos: Unix, DOS, MacOS
SISTEMA REMOTO: La computadora o red a la cual una computadora se conecta por vía de un módem. La computadora que se conecta a un sistema remoto se conoce como terminal remota.SMTPProtocolo de control de transferencia para correo electrónico.
SOBREESCRIBIR (Overwrite):Grabar información en la misma área donde otra información estaba almacenada, con lo cual queda destruída la información original.
t
TCP/IP:Protocolo de control de transferencia de datos establecido en 1982 como estándar de Internet.
Tera Byte (TB): 1024 x 1024 x 1024 x 1024 bytes
Terminal: Aparato que permite comunicarse con la unidad central de un computador que puede estar a gran distancia (Se trata generalmente de un teclado unido a un monitor -pantalla- más el sistema de transmisión). de compilación: Se refiere a lo que se produce durante el proceso de compilación.
Tiempo de ejecución: Se refiere a lo que sucede mientras el programa se está ejecutando realmente. Normalmente, estos términos aparecerán cuando se consideren posibles errores, encontrándose como "Errores de tiempo de Compilación" y "Errores de tiempo de ejecución".
Traductor: Se refiere a un programa que se encarga de convertir lenguajes de un nivel superior a otro inferior. Según el tipo de lenguaje se puede tratar de un traductor:Compilador o un traductor:intérprete.
Transceiver: Aparato que recibe y envía señales (p.ej. para conectar un computador a una red).
Transistor: Componente electrónico básico que detiene o deja pasar las señales eléctricas dependiendo de las pulsaciones anteriores. Un chip o circuito integrado contiene un gran números de transistores.
u
URL(Localizador de recursos uniformes):Dirección de internet para páginas WEB.
UseNet: Red de computadores que intercambian noticias en forma de artículos adscritos a grupos de discusión (newsgroups).
v
Virus:Sofware que se ejecuta en un PC, Mac o servidor sin control del usuario, con el fin de dañar la información existente. Se auto-reproduce al ejecutarse, multiplicándose así con gran facilidad.
w
World Wide Web (WWW):Red mundial de computadores por la cual se transmiten principalmente archivos hiper y multimediales.
#
4 GL: 4 Generation Language. También conocidos como lenguajes Visuales
2
Descargar
| Enviado por: | Cyrus Infers |
| Idioma: | castellano |
| País: | Chile |
Todos los derechos reservados.