Informática
Arquitectura de computadores
Índice
INTRODUCCION
Introducción histórica
Introducción técnica
2. ORIGEN
3. ARQUITECTURAS CISC
4. ARQUITECTURAS RISC
4.1 Arquitectura
4.2 Tecnología
4.3 El Pipeline
4.4 Principios de diseño
4.5 Características generales
5. COMPARATIVA RISC vs CISC
5.1 Evaluación RISC vs CISC
5.2 Pentium, ¿RISC o CISC?
6. RENDIMIENTO EN RISC
6.1 Arquitectura load / store
6.2 Encadenamiento
6.3 Arquitecturas superescalares
7. COMPILADORES EN UN SISTEMA RISC
7.1 Objetivos
7.2 Compiladores optimizados del RISC
7.3 Técnicas de Optimización
8. APLICACIONES
9. EJEMPLOS DE PROCESADORES RISC
9.1 Apple Power Mac G4 a 500 MHz
9.2 Kripton - 5 O K5 DE AMD
9.3 Pentium pro de Intel
9.4 MIPS
9.5 SUN MICROSYSTEMS
10. CONCLUSIONES
11. EL FUTURO
ANEXO
Conceptos de multiproceso
Los sistemas de memoria caché y el multiproceso
1. INTRODUCCION
Introducción histórica
A lo largo de la historia de la industria de los ordenadores, la tendencia mayormente adoptada para conseguir un aumento de prestaciones, ha sido el incremento de la complejidad de las instrucciones. Es lo que se ha denominado "computación con conjuntos de instrucciones complejas" o CISC (Complex Instruction SetComputing).
Sin embargo, la tendencia actual, se esfuerza en conseguir procesadores con conjuntos de instrucciones de complejidad reducida o RISC (Reduced Instruction Set Computing). La idea es que un conjunto de instrucciones poco complejas son simples, y por tanto de más rápida ejecución, lo que permite crear un código más "aerodinámico".
Tanto la tecnología CISC como la RISC son acreditadas a IBM, aunque sus antecesores bien pueden ser John Von Neumman (inventor del primer programa de ordenador almacenado, y que promovía la velocidad inherente a conjuntos de instrucciones reducidas), Maurice Wilkes (padre de la microprogramación y de muchos conceptos de los diseños RISC), y Seymour Cray (primeros supercomputadores, empleando principios RISC).
En 1975, IBM inició el desarrollo de un controlador para un sistema de conmutación telefónica, que aunque fue abandonado, sirvió como punto de partida para el desarrollo de una CPU con tecnología ECL, corazón del sistema 801, precursor del IBM PC RT.
Los inicios de la tecnología RISC también surgen en el ambiente académico, ya que en 1980, la Universidad de Berkeley (California), el Dr. David A. Patterson inició un proyecto denominado RISC I, que obtuvo resultados en tan solo 19 meses, seguido por RISC II, SOAR (Smalltalk on a RISC) y SPUR (Symbolic Processing on a RISC). El resultado directo, además de la educación en la ingeniería y los fundamentos del diseño de microprocesadores, fue la creación de una máquina que fuese capaz de mayores velocidades de ejecución a menores velocidades de reloj y que requiriese menores esfuerzos de diseño.
Casi simultáneamente, en la Universidad de Stanford, el Dr. John Hennesy inició también un proyecto de implementación RISC, denominado MIPS, seguido por el sistema MIPS-XMP, enfocados hacia el proceso simbólico, demostrando las capacidades de velocidad de la arquitectura RISC. Ambos profesores se vieron envueltos rápidamente, en proyectos de productos comerciales, y en concreto, Hennesy fue uno de los fundadores de MIPS Computer Systems, mientras Patterson actuaba de asesor durante el desarrollo del primer SPARC.
Por otro lado, durante las pasadas décadas, el multiproceso, como medida de incrementar drásticamente las prestaciones de los sistemas a un coste razonable, se ha visto reducido al ámbito de los computadores de "alto nivel", en parte debido a los bajos niveles de integración del silicio, y a la falta de software que facilitase la ejecución paralela de las aplicaciones.
Las ventajas de los procesadores RISC, especialmente las ligadas a los sistemas abiertos (léase UNIX), los hacen plataformas ideales para explorar los puntos fuertes de los sistemas multiprocesadores.
1.2 Introducción técnica
Veamos primero cual es el significado de los términos CISC y RISC:
-
CISC (complex instruction set computer) Computadoras con un conjunto de instrucciones complejo.
-
RISC (reduced instruction set computer) Computadoras con un conjunto de instrucciones reducido.
Los atributos complejo y reducido describen las diferencias entre los dos modelos de arquitectura para microprocesadores solo de forma superficial. Se requiere de muchas otras características esenciales para definir los RISC y los CISC típicos. Aun más, existen diversos procesadores que no se pueden asignar con facilidad a ninguna categoría determinada. Así, los términos complejo y reducido, expresan muy bien una importante característica definitiva, siempre que no se tomen solo como referencia las instrucciones, sino que se considere también la complejidad del hardwaredel procesador.
Con tecnologías de semiconductores comparables e igual frecuencia de reloj, un procesador RISC típico tiene una capacidad de procesamiento de dos a cuatro veces mayor que la de un CISC, pero su estructura de hardware es tan simple, que se puede realizar en una fracción de la superficie ocupada por el circuito integrado de un procesador CISC.
Esto hace suponer que RISC reemplazará al CISC, pero la respuesta a esta cuestión no es tan simple ya que:
-
Para aplicar una determinada arquitectura de microprocesador son decisivas las condiciones de realización técnica y sobre todo la rentabilidad, incluyendo los costos de software.
- Existían y existen razones de compatibilidad para desarrollar y utilizar procesadores de estructura compleja así como un extenso conjunto de instrucciones.
La meta principal es incrementar el rendimiento del procesador, ya sea optimizando alguno existente o se desee crear uno nuevo. Para esto se deben considerar tres áreas principales a cubrir en el diseño del procesador y estas son:
* La arquitectura.
* La tecnología de proceso.
* El encapsulado.
La tecnología de proceso, se refiere a los materiales y técnicas utilizadas en la fabricación del circuito integrado, el encapsulado se refiere a cómo se integra un procesador con lo que lo rodea en un sistema funcional, que de alguna manera determina la velocidad total del sistema. Aunque la tecnología de proceso y de encapsulado son vitales en la elaboración de procesadores más rápidos, es la arquitectura del procesador lo que hace la diferencia entre el rendimiento de una CPU (Control Process Unit) y otra. Y es en la evaluación de las arquitecturas RISC y CISC donde centraremos nuestra atención.
Dependiendo de cómo el procesador almacena los operandos de las instrucciones de la CPU, existen tres tipos de juegos de instrucciones:
1.Juego de instrucciones para arquitecturas basadas en pilas.
2.Juego de instrucciones para arquitecturas basadas en acumulador.
3.Juego de instrucciones para arquitecturas basadas en registros.
Las arquitecturas RISC y CISC son ejemplos de CPU con un conjunto de instrucciones para arquitecturas basadas en registros.
2. ORIGEN
Los ordenadores etiquetados como CISC gozan de los privilegios y defectos del microcódigo. La CPU es considerablemente más rápida que la memoria principal. Esto significa que conviene manejar un amplio abanico de instrucciones complejas cuyo significado equivalga al de varias instrucciones simples, disminuyendo así los accesos a memoria. A esto se le añade la tendencia de aumentar el grado de complejidad de las instrucciones para acercarlas a los lenguajes de alto nivel (como Pascal, C, o Basic) ya que es mucho más fácil y barato programarlos frente a ensamblador.
Sin embargo, como resultado de ciertos estudios en los que se examino la frecuencia de utilización de las diferentes instrucciones, se observo que el 80 % del tiempo era consumido por solo el 20 % de las instrucciones, con prioridad de los almacenamientos (STORE), cargas (LOAD) y bifurcaciones (BRANCH).
Instrucciones mas usadas
Esto significa que se poseían soberbias memorias de control cuyo contenido era muy poco utilizado. Se estaba penalizando la velocidad de respuesta en aras de tener información poco útil.
La alternativa RISC se basa en este principio y propone procesadores cableados con un repertorio simple de instrucciones sencillas y frecuentes; todo código complejo puede descomponerse en varios módulos mas elementales en los que, para evitar los terribles efectos sobre los retardos de la memoria principal se recurre a numerosos registros (unidades de almacenamiento enclavada en la CPU y, por tanto, tan rápida como esta) y a memorias cache (pequeñas memorias de alta velocidad que se alimentan de la MP, de la que toman la información que está siendo más frecuentemente utilizada).
Otro de los objetivos del RISC fue lograr que a cada instrucción correspondiera un solo ciclo de reloj, a excepción, de aquellos casos que hay que mover datos.
Las principales mejoras que se buscan con el seguimiento de esta nueva metodología son:
- Reducción del numero de instrucciones ( ensamblador ).
- Uso intensivo de registros, diminuyendo los accesos a memoria.
- Simplificación de la CPU en aras de una mayor velocidad de proceso.
- Empleo de memorias cache.
- Utilización de "compiladores optimizados", generadores de código objeto
adaptado a los requerimientos de la CPU.
- Disminuir la probabilidad de fallo.
- Facilitar el diseño del procesador.
- Permitir maquinas más compactas y con menor consumo y coste.
Incluso con toda la amalgama de datos obtenidos a favor y en contra del CISC y del RISC, hay que tener siempre presente el importantísimo papel que juega “ La Eficacia del Software “.
3. ARQUITECTURAS CISC
La microprogramación es una característica importante y esencial de casi todas las arquitecturas CISC. Como por ejemplo:
-
Intel 8086, 8088, 80286, 80386, 80486.
-
Motorola 68000, 68010, 68020, 68030, 6840.
La microprogramación significa que cada instrucción de máquina es interpretada por un microprograma localizado en una memoria en el circuito integrado del procesador.
En la década de los sesentas la microprogramación, por sus características, era la técnica más apropiada para las tecnologías de memorias existentes en esa época y permitía desarrollar también procesadores con compatibilidad ascendente. En consecuencia, los procesadores se dotaron de poderosos conjuntos de instrucciones. Las instrucciones compuestas son decodificadas internamente y ejecutadas con una serie de microinstrucciones almacenadas en una ROM interna. Para esto se requieren de varios ciclos de reloj (al menos uno por microinstrucción).
4. ARQUITECTURAS RISC
4.1 Arquitectura
Buscando aumentar la velocidad del procesamiento se descubrió en base a experimentos que, con una determinada arquitectura de base, la ejecución de programas compilados directamente con microinstrucciones y residentes en memoria externa al circuito integrado resultaban ser mas eficientes, gracias a que el tiempo de acceso de las memorias se fue decrementando conforme se mejoraba su tecnología de encapsulado.
Debido a que se tiene un conjunto de instrucciones simplificado, éstas se pueden implantar por hardware directamente en la CPU, lo cual elimina el microcódigo y la necesidad de decodificar instrucciones complejas.
4.2. Tecnología
-
Arquitectura Von Neumann.
Como base de este tipo de procesadores .
-
Instrucciones divididas en 3 grupos
Aunque distintas a las de los procesadores CISC:
a) Transferencia.
b) Operaciones.
c) Control de flujo.
-
Reducción del conjunto de instrucciones:
Instrucciones simples, de formato fijo, con pocos modos de direccionamiento. Las instrucciones simples reducen de manera muy significativa el esfuerzo para su descodificación, y favorecen su ejecución en pipelines. Las instrucciones de longitud fija, con formatos fijos, implican que los campos de códigos de operación (opcodes) y de los operandos están siempre codificados en las mismas posiciones, permitiendo el acceso a los registros al mismo tiempo que se está descodificando el código de operación. Todas las instrucciones tienen una longitud equivalente a una palabra y están alineadas en la memoria en límites de palabra ya que no pueden ser repartidas en pedazos que puedan estar en diferentes páginas.
.
-
Arquitectura del tipo load-store (carga y almacena).
Sólo las instrucciones Load/Store acceden a memoria; las demás operaciones en un RISC, tienen lugar en su gran conjunto de registros. Ello simplifica el direccionamiento y acorta los tiempos de los ciclos de la CPU, y además facilita la gestión de los fallos de paginas (page faults) en entornos de memoria virtual. Además, permite un elevado nivel de concurrencia a consecuencia de la independencia de las operaciones de Load/Store de la ejecución del resto de las instrucciones.
-
Arquitectura no destructiva de tres direcciones.
Los procesadores CISC destruyen la información que existe en alguno de los registros, como consecuencia de la ejecución normal de instrucciones; esto es debido a su arquitectura de dos direcciones, por la cual el resultado de una operación sobrescribe uno de los registros que contenía a los operandos. Por contra, las instrucciones RISC, con tres direcciones, contienen los campos de los dos operandos y de su resultado. Por lo tanto, tanto los operandos origen como el destino, son mantenidos en los registros tras haber sido completada la operación. Esta arquitectura "no destructiva" permite a los compiladores organizar las instrucciones de modo que mantengan llenos los conductos (pipelines) del chip, y por tanto reutilizar los operandos optimizando la concurrencia.
-
Ausencia de microcódigo.
El microcódigo no se presta a la ejecución en ciclos únicos, ya que requiere que el hardware sea dedicado a su interpretación dinámica. La programación en microcódigo no hace que el software sea más rápido que el programado con un conjunto de instrucciones simples. Todas las funciones y el control, en los procesadores RISC, están "cableados" para lograr una máxima velocidad y eficiencia.
-
Ejecución en ciclos únicos (single-cycle).
El resultado directo de los conjuntos de instrucciones que ofrecen los procesadores RISC, es que cada instrucción puede ser ejecutada en un único ciclo de la CPU. Esto invalida la creencia de que las microinstrucciones en microcódigo, creadas para ser ejecutadas en un solo ciclo de procesador, son más rápidas que las instrucciones del lenguaje ensamblador. Ya que el caché esta construido partiendo de la misma tecnología que el almacenamiento de control del microprograma, una única instrucción puede ser ejecutada a la misma velocidad que una microinstrucción. La ejecución en ciclos únicos también simplifica la gestión de las interrupciones y los conductos (pipelines).
-
Uso de Pipeline (Ejecución simultánea de varias instrucciones)
Que permite reducir el número de ciclos de máquina necesarios para la ejecución de la instrucción, ya que esta técnica permite que una instrucción puede empezar a ejecutarse antes de que haya terminado la anterior.
-
Uso de Funciones Adicionales.
Como consecuencia de la reducción de la superficie del circuito integrado:
- Unidad para el procesamiento aritmético de punto flotante.
- Unidad de administración de memoria.
- Funciones de control de memoria cache.
- Implantación de un conjunto de registros múltiples.
4.3 El Pipeline
Todo el mundo conoce más o menos lo que es una cadena de montaje. Imaginemos que por ejemplo una cadena de montaje de una factoría es capaz de sacar un coche por minuto, a pesar de que cada coche tarda varias horas en fabricarse. El secreto es fabricar varios coches a la vez. A este concepto de cadena en el diseño de CPUs se le llama pipeline, que podemos traducir como tubería. La idea es sencilla: mientras ejecutamos una instrucción máquina vamos decodificando la siguiente, y buscando otra.
En el dibujo tenemos una tubería real, de 5 pasos (los coches representan instrucciones, por supuesto). Desgraciadamente esto de la tubería no es tan fácil como parece. Los RISC intentan hacer la tubería lo más eficiente posible.
Este principio lo emplean todos los micros de 16 bits en adelante.
4.4 Principios de diseño
En este apartado, se intenta presentar de una manera general la filosofía básica de diseño de estas maquinas, teniendo en cuenta que dicha filosofía puede presentar variantes.
El diseño de una máquina RISC se tienen cinco pasos fundamentales:
Analizar las aplicaciones para encontrar las operaciones clave.
Se refiere a que el diseñador deberá encontrar qué es lo que hacen en realidad los programas que se pretenden ejecutar. Ya sea que los programas a ejecutar sean del tipo algorítmicos tradicionales, o estén dirigidos a robótica o al diseño asistido por computadora.
Diseñar un bus de datos que sea óptimo para las operaciones clave.
La parte medular de cualquier sistema es la que contiene los registros, el ALU y los 'buses' que los conectan. Se debe optimizar este circuito para el lenguaje o aplicación en cuestión. El tiempo requerido, (denominado tiempo del ciclo del bus de datos) para extraer los operandos de sus registros, mover los datos a través del ALU y almacenar el resultado de nuevo en un registro, deberá hacerse en el tiempo mas corto posible.
3.- Diseñar instrucciones que realicen las operaciones clave utilizando el
bus de datos.
Las instrucciones deben hacer un buen uso del bus de datos. Por lo general se necesitan solo unas cuantas instrucciones y modos de direccionamiento; sólo se deben colocar instrucciones adicionales si serán usadas con frecuencia y no reducen el desempeño de las más importantes.
Agregar nuevas instrucciones sólo si no hacen más lenta a la máquina.
Siempre que aparezca una nueva y atractiva característica, deberá analizarse y ver la forma en que se afecta al ciclo de bus. Si se incrementa el tiempo del ciclo, probablemente no vale la pena tenerla.
Repetir este proceso para otros recursos.
Por último, el proceso anterior debe repetirse para otros recursos dentro del sistema, tales como memoria caché, administración de memoria, coprocesadores de punto flotante, ...
Por otra parte, es necesario considerar otros factores tales como:
-
La disponibilidad de memorias grandes, baratas y con tiempos de acceso menores de 60 ns en tecnologías CMOS.
-
Módulos SRAM (Memoria de acceso aleatorio estática) para memorias cache con tiempos de acceso menores a los 15 ns.
-
Tecnologías de encapsulado que permiten realizar más de 120 terminales.
-
.......
4.5 Características Generales
Aunque los RISC son distintos e incompatibles entre si, mantienen unas características generales comunes, ya que todos se basan en los mismos principios. En general todo está orientado a hacer un pipeline eficiente y a facilitar la tarea del compilador:
-
Producen 2 accesos a memoria por ciclo: leer instrucción y leer dato. Esto hace imprescindibles memorias muy rápidas y obliga a usar memorias caché.
-
El mecanismo tubería tiene un grave problema: a veces necesitamos en el paso 2 cosas que calculamos en el 3; tenemos que incorporar circuitería que adelante resultados. Todas las instrucciones de los RISC están pensadas para minimizar estos problemas.
-
Debemos evitar los posible atascos; una instrucción lenta atasca a las demás. Los RISC tienen todas las instrucciones agrupadas en duración en unos pocos tipos. Esto simplifica enormemente la lógica interna.
-
En los no-RISC o CISC hay instrucciones que pueden ocupar de un byte o más. A su vez tenemos separados de la instrucción un número variable de direcciones de memoria, de operandos, etc... Esto hace que interpretar la instrucción sea muy complicado, ya que no sabemos lo que hay que leer de memoria hasta no decodificar la instrucción, y después hay que hacer (sólo si procede) una serie de lecturas para buscar más datos.
Las instrucciones de los RISC son todas de 1 palabra de longitud, es decir, típicamente de 32 bits. Aquí tenemos accesible en sólo una lectura (la búsqueda de instrucción) todo lo que necesitamos.
-
La regularidad de las instrucciones hace que la unidad de control del microprocesador pueda ser cableada, siendo mas rápido, haciendo que se pueda ejecutar una instrucción por ciclo de reloj, es decir, la velocidad máxima posible.
Las instrucciones de coma flotante (lo que hace un coprocesador matemático) no pueden encajar en esto. Son enormemente lentas y complicadas. Sin embargo los diseñadores saben que la gente que quiere velocidad (físicos, ingenieros) trabaja con coma flotante. La solución adoptada consiste en poner una unidad separada pero dentro del mismo integrado
-
Cuando tenemos que hacer un salto, una llamada a subrutina o se produce una interrupción, las instrucciones que tenemos en la pipeline no nos valen. El hilo de la ejecución se rompe y debemos vaciar la pipeline para cargar las nuevas instrucciones de la dirección a la que hemos saltado. La primera nueva instrucción tiene que recorrer toda la pipeline y tarda bastante tiempo. Desgraciadamente ocurre un salto cada 10 instrucciones aproximadamente.
Para evitar en lo posible esto, hay una unidad independiente que se encarga de intentar adivinar si se va a saltar o no antes de llegar a la instrucción de salto y cargar la pipeline con las instrucciones adecuadas. A esta unidad se la ha llamado la unidad de predicción de saltos. Es responsabilidad del compilador facilitar la tarea a esta unidad.
-
Según lo comentado anteriormente, vemos que un RISC tiene 3 unidades: enteros, coma flotante y saltos.
-
Para mejorar el rendimiento se han incluido a veces 2 (o más) unidades de enteros. A esto se le llama super-escalar. Se leen dos instrucciones cada vez, se ve si se pueden ejecutar en paralelo y se da una a cada unidad si se puede. De este modo se pueden ejecutar 2 instrucciones por ciclo de reloj. Si no podemos, ejecutamos una después de otra como siempre. En la práctica es el compilador el que se debe encargar de poner juntas instrucciones que se puedan ejecutar en paralelo.
-
Desde el punto de vista del programador, los RISC tienen muchos registros (típicamente 32 de enteros y 32-64 de coma flotante). Además son todos funcionalmente iguales; toda operación puede usar cualquiera como fuente o destino. Esto facilita la labor del compilador y elimina las típicas transferencias que se producen cuando necesitamos poner algo en el acumulador para realizar las operaciones aritméticas.
-
Normalmente tienen pocos modos de direccionamiento: inmediato (el operando forma parte de la instrucción), registro (operando es un registro) e indexado (o indirecto registro con desplazamiento). En el modo indexado el operando está en la dirección apuntada por el registro más el desplazamiento. Si el desplazamiento es 0 tenemos el modo indirecto por registro.
Como vemos sólo se proporcionan los modos más básicos. El resto de los modos se pueden hacer combinando varias instrucciones.
-
Los RISC no operan directamente con memoria. Los operandos se cargan en registros, se opera con los registros, y se almacena el resultado en memoria. De hecho, otro nombre para las maquinas RISC es arquitectura Carga Almacenamiento.
Vamos a ver como interpreta un compilador una sentencia como c=a+b:
NO RISC RISC
ld R1,a ;cargo a ld R1,a ;cargo a
add R1,b ;no cargo b, ld R2,b ;también b
;opero directamente
st c,R1 ; almaceno add R3,R1,R2 ; opero
st c,R3 ; almaceno
Podemos ver que RISC necesita cargar ambos operandos en registros; no puede operar con memoria. Sin embargo puede operar con 3 operandos a la vez. Ambos micros hacen 3 accesos a memoria, que son muy lentos, y al final el tiempo de ejecución será similar a pesar de ejecutar RISC una instrucción más. Si además tenemos un compilador inteligente (o al menos listillo) puede situar las variables a,b y c en registros. De este modo no tengo que cargar y almacenar, y me ahorro las lentas operaciones con memoria.
Para hacer esta optimización RISC tiene varias ventajas:
-
RISC tiene muchos más registros disponibles (típicamente 32 frente a 2 de un IBM PC).
-
Al poder usar 3 operandos, el destino no tiene porque ser una de las fuentes; no destruyo los operandos originales.
-
Todos los registros pueden contener datos y direcciones de memoria.
Estas son, en resumen, las características principales de los RISC. Los CISC más modernos comparten varias características, como el pipeline, la unidad de saltos ... etc.
Todos los fabricantes de chips para estaciones de trabajo saben que es vital que se soporte UNIX, así que incluyen mecanismos de protección de memoria, cambio de tareas y demás, a pesar de que esto hace al chip más complicado y lento.
5. COMPARATIVA RISC vs CISC
5.1 Evaluación RISC vs CISC
El conflicto surge al evaluar las ventajas netas ¿ que es mas apropiado, usar muchas instrucciones de un solo ciclo aprovechadas al máximo, o pocas de múltiples pasos de reloj en las que existe infrautilización ?
La cuestión, es que hasta el momento, el estudio de prestaciones de ambas tecnologías, nos ha llevado a concluir que hoy en día los RISC obtienen mas prestaciones, es decir, son mas potentes y rápidos que los CISC. Sin embargo, el mercado se ha decantado por la tecnología CISC en cuanto a volumen de ventas. ¿ Por que ?
1.- Por experiencia propia, podemos comprobar que un CISC tiene un coste "razonable", que es alcanzado a nivel de usuario. Esto mismo, no ocurre con los RISC, que por el contrario tienen un coste elevado, por esto mismo esta tecnología ha sido enfocada a ventas a nivel de empresa y equipos de gama alta.
2.- La utilidad que se le de a la maquina es muy importante, ya que el usuario debe de encontrar un nivel optimo en cuanto a calidad - precio. Y por que pagar mas si realmente no se le va a sacar partido al cien por cien.
3.- El software utilizado es otro de los factores importantes, dado que un RISC no utiliza el mismo software que un CISC. Estos últimos, por lo general tienen un software mas asequible.
4.- Dada la compatibilidad hacia atrás de la familia CISC x86, los usuarios han podido renovar sus equipos sin por ello tener que abandonar software que ya conocían, y reutilizar sus datos. Así mismo, los fabricantes han tenido en cuenta este factor, puesto que seguir con otra línea de procesadores suponía no solo un cambio muy radical, sino que además podía llevar un riesgo en cuanto a ventas.
Estos son algunos de los motivos. Sin embargo, también hay que tener en cuenta el conflicto de intereses de algunos fabricantes, así como la opinión de distintas revistas, algunas de ellas asociadas a diferentes marcas. Se están estudiando las tendencias futuras, como pueden ser los híbridos, mejoras en los microprocesadores CISC, mejoras en los RISC, ...
5.2 Pentium, ¿RISC o CISC?
El Pentium ofrece un juego de instrucciones CISC, pero internamente está diseñado como un procesador RISC. Cada instrucción CISC del juego x86 antiguo se descompone en una o varias RISC.
Este proceso de conversión sólo ocupa el 3% del circuito que se dedica a microprogramas. El Pentium tiene dos unidades de ejecución de enteros (U y V) y una de punto flotante. Presenta encadenamiento (pipeline) de 5 etapas para los enteros y de 8 para los número de punto flotante. Para realizar una operación de punto flotante, se aprovechan las 4 primera etapas de la primera unidad de enteros, y la unidad de punto flotante toma el control para las 4 últimas etapas.
Para saber si las instrucciones son paralelizable, el procesador sigue un sencillo algoritmo. Para ejecutar las instrucciones I1 e I2:
IF I1 es simple
AND I2 también simple
AND I1 no es salto
AND destino de I1 no es fuente de I2
AND destino de I1 no es destino de I2
THEN
envía I1 a U
envía I2 a V
ELSE
envía I1 a U, para I2 ( será evaluada con I3)
Si se utiliza un compilador que conoce este modo de funcionamiento, mejora hasta un 30% la velocidad.
Existen mejoras en las arquitecturas superescalares, que intentan reducir el impacto de los conflictos de datos en el rendimiento.
6. RENDIMIENTO EN RISC
Para medir el rendimiento de una arquitectura, tal y como hemos visto en teoría hay que tener en cuenta simultáneamente los CPI, las CRP y la frecuencia de reloj.
Veamos de qué dependen cada uno de estos factores:
-
Influencia en ciclos de reloj por instrucción (CPI)
Encadenamiento (tratamiento de conflictos)
Depende de Arquitectura load / store
Arquitecturas superescalares
-
Influencia en ciclos de reloj de programa o instrucciones por programa (CRP)
Arquitectura load / store
Depende de Compiladores
-
Influencia en tiempo de ciclo (T)
Depende de → Instrucciones simples y fáciles de decodificar
6.1 Arquitectura Load/Store
En las arquitecturas CISC las operaciones pueden operar directamente sobre memoria (suma el dato contenido en un registro con lo que hay en una posición de memoria, y lo deja en esa posición). En este tipo de instrucciones hay que acceder varias veces a MP. Recordemos que un acceso a MP es mucho más costoso que un acceso a registros. También hay instrucciones que dejan los resultados en un registro, pero toman los datos de memoria.
Las arquitecturas load / store intentan reducir el número de accesos a MP para ganar velocidad. Una instrucción load / store accede como mucho una vez a memoria en lo que respecta a los datos. "load" transfiere un dato de memoria a un registro, mientras que "store" escribe el contenido de un registro a memoria.
Algunas de las ventajas de Load/Store son:
-
La fase de acceso a memoria de las instrucciones no es excesivamente larga, por lo que las instrucciones de este tipo son apropiadas para la ejecución encadenada. Operar directamente sobre memoria incrementa el tiempo de ejecución.
-
La reducción en el número de accesos a memoria mejora el rendimiento.
-
Limitar todas las operaciones a registros simplifica el diseño del conjunto de instrucciones.
6.2 Encadenamiento
Definimos cadena de producción como la aplicación simultanea de varios operadores a un flujo secuencial de informaciones. Podemos tener dos tipos de encadenamiento atendiendo a la información sobre el que lo hagamos:
-
Encadenamiento en el flujo de datos.
-
Encadenamiento en el flujo de instrucciones
Al haber encadenamientos, a su vez pueden aparecer problemas como son los tiempos muertos debidos a la diferente duración de las etapas y los conflictos o azares. Estos últimos pueden ser de tres tipos:
Conflictos Estructurales: Ocurre cuando en un momento determinado, dos o más secciones de la cadena necesitan un recurso que no puede compartirse..
Conflicto de Control: Ocurre con instrucciones de bifurcación efectivas. Cómo el porcentaje de instrucciones de este tipo es relativamente grande en un programa, esto puede tener una repercusión importante en la velocidad.
Conflicto de Datos: Se origina cuando una instrucción B opera sobre el resultado de otra previa a ella A, que aún está en etapa de ejecución. El procesador puede detectar este tipo de conflictos y, en este caso, provocar paradas en la cadena (interbloqueo), o bien utilizar vías alternativas en la ruta de datos (cortocircuitos).
Conflicto esencial .
Hay tres tipos de conflictos de datos Conflicto de Orden .
Conflicto de Salida.
Cuando no somos capaces de mantener el ritmo de la cadena de instrucciones, el rendimiento se degrada. Se puede perder el ritmo por el tratamiento de algún conflicto (paradas, inclusión de instrucciones inútiles...) o por el uso de instrucciones con distintos tiempos de ejecución.
El objetivo, en cualquier caso, es obtener un ancho de banda de ejecución de una instrucción en cada ciclo.
Para evitar las paradas se usan diversas técnicas, entre ellas destacamos la llamada:
Ejecución especulativa: (Predicción de saltos)
Se ejecutan instrucciones sin saber si van a ser útiles. Un ejemplo de técnica de ejecución especulativa es la predicción de saltos. Antes incluso de conocer cuales son la condición de salto y la dirección efectiva, se sigue el hilo de ejecución. Si se ha fallado al hacer la predicción se descartan los resultados.
Para minimizar el efecto negativo de los saltos, se trata de predecir si se va a producir o no el salto en base a datos estadísticos.
La predicción puede ser:
Estática: la realiza el compilador analizando el código. Al final de un bucle que se repite 99 veces hay un 99% de probabilidades de que salte y un 1% de que continúe. El compilador podría indicar al procesador que lo normal es que salte.
Dinámica: existen unos bits de historia que indican lo que ha ocurrido las últimas veces que el contador de programa pasó por ese punto.
Híbrida: se analiza el código, pero además hay 2 bits de historia en la caché de instrucciones.
6.3 Arquitecturas Superescalares
El encadenamiento aumenta la velocidad de proceso, pero aún se puede mejorar añadiendo técnicas como el superescalado. Esta técnica permite hacer paralelas las mismas etapas sobre instrucciones diferentes. Un procesador superescalar puede ejecutar más de una instrucción a la vez. Para esto es necesario que existan varias unidades aritmético-lógicas, de punto flotante y de control. El proceso que sigue el micro es transparente al programa, aunque el compilador puede ayudar analizando el código y generando un flujo de instrucciones optimizado.
Veamos cómo se ejecutarían las instrucciones en un procesador superescalar de que tiene duplicadas las subunidades que lo componen:
Aunque esto mejora la velocidad global del sistema, los conflictos de datos crecen. Si antes las instrucciones se encontraban muy próximas, ahora se ejecutan simultáneamente. Esto hace necesario un chequeo dinámico para detectar y resolver los posibles conflictos.
Existen mejoras en las arquitecturas superescalares, que intentan reducir el impacto de los conflictos de datos en el rendimiento. Veamos dos de ellas:
-
Ejecución desordenada.
Supongamos un conflicto de datos entre las instrucciones A y B consecutivas. El procesador retarda sólo B y las instrucciones que dependen de ella, pero no otras instrucciones independientes que vayan detrás de A. Esto implica mayor complejidad, pero también mayor ancho de banda de ejecución. El Pentium Pro y el HP8000 usan esta técnica.
-
Registros en la sombra
También llamados Shadow Registers o Dynamic Register Renaming. Esta técnica consiste en eliminar las dependencias de orden o de salida teniendo varios juegos de registros, uno por unidad de ejecución.
7. COMPILADORES EN UN SISTEMA RISC
7.1 Objetivos
El compilador juega un papel clave para un sistema RISC equilibrado. Todas las operaciones complejas se trasladan al microprocesador por medio de conexiones fijas en el circuito integrado para agilizar las instrucciones básicas más importantes. De esta manera, el compilador asume la función de un mediador inteligente entre el programa de aplicación y el microprocesador. Es decir, se hace un gran esfuerzo para mantener al hardware tan simple como sea posible, aún a costa de hacer al compilador considerablemente más complicado. Esta estrategia se encuentra en clara contra posición con las máquinas CISC que tienen modos de direccionamiento muy complicados.
En la práctica, la existencia en algunos modos de direccionamiento complicados en los microprocesadores CISC, hacen que tanto el compilador como el microprograma sean muy complicados.
No obstante, las máquinas CISC no tienen características complicadas como carga, almacenamiento y salto que consumen mucho tiempo, las cuales en efecto aumentan la complejidad del compilador. Para suministrar datos al microprocesador de tal forma que siempre esté trabajando en forma eficiente, se aplican diferentes técnicas de optimización en distintos niveles jerárquicos del software.
Los diseñadores de RISC en la empresa MIP y en Hewlett Packard trabajan según la regla siguiente:
Una instrucción ingresa en forma fija en el circuito integrado del procesador (es decir, se alambra físicamente en el procesador) si se ha demostrado que la capacidad total del sistema se incrementa en por lo menos un 1%.
En cambio, los procesadores CISC, han sido desarrollados por equipos especializados de las empresas productoras de semiconductores y con frecuencia el desarrollo de compiladores se sigue por separado. Por consiguiente, los diseñadores de los compiladores se encuentran con una interfaz hacia el procesador ya definido y no pueden influir sobre la distribución óptima de las funciones entre el procesador y compilador.
Las empresas de software que desarrollan compiladores y programas de aplicación, tienden por razones de rentabilidad, a utilizar diferentes procesadores como usuarios de su software en lugar de realizar una optimización completa, y aprovechar así las respectivas características de cada uno. Lo cual también genera otros factores negativos de eficiencia. Esta limitación de las posibilidades de optimización del sistema, que viene dada a menudo por una obligada compatibilidad, se superó con los modernos desarrollos RISC.
7.2 Compiladores optimizados del RISC
Es cierto que un procesador RISC es mas veloz que uno CISC, pero también lo es que, al ser mas simples las instrucciones, necesita mas de estas para emular funciones complejas, por lo que los programas son mas largos y voluminosos. Es decir, el código objeto generado, ocupa mas memoria y, al ser mas extenso, emplea mas tiempo en ser procesado. Los partidarios argumentan que el factor volumen de memoria incide poco en el precio, además estiman que el aumento de código no toma dimensiones importantes por el uso de coprocesadores y compiladores optimizados.
Los segundos destacan dos aspectos :
1.- Al existir menor variedad en el código generado, el proceso de compilación es mas rápido. El motivo es que hay menor numero de reglas y posibilidades entre las que elegir ( no existirá la disyuntiva de construir la misma acción por diferentes caminos, solo habrá una forma única ) evitando la exploración de grandes tablas de instrucciones en busca del sujeto correcto.
" En un ordenador convencional, la misma instrucción de lenguaje de alto nivel puede ejecutarse de diversas formas, cada una con sus inconvenientes y ventajas, pero en el RISC solo hay una forma de hacer las cosas " .
2.- Al traducir los lenguajes de alto nivel mediante unidades de extrema simplicidad, se incremente la eficiencia. Si se emplean instrucciones potentes se corre el riesgo de no aprovecharlas en su totalidad y potencia, menor es la adaptación a los diferentes casos particulares
7.3 Técnicas de Optimización
Algunas de las técnicas más comúnmente usadas son:
Gestión de registros.
El compilador reserva registros para guardar los datos a los que se accede con más frecuencia
Eliminación de redundancia
Optimización de bucles.
Reconoce las expresiones que no cambian en un bucle y las extrae. En ANSI-C la definición volatile evita que el compilador saque una variable del bucle, esto es útil cuando la variable es susceptible de ser cambiada por la CPU, otro dispositivo, etc.
Reducción de complejidad.
Reemplaza operaciones caras en tiempo por otras más sencillas. Por ejemplo, si accedemos a la posición [a,b] de un array bidimensional de dimensión [A,B], se calcula inicioDelArray+[(b*A)+a] * TamañoDelDato. Se podría simplificar ésto si, trabajando en la misma fila, se guarda en un registro (b*A)*TamañoDelDato, ahorrando tiempo en el acceso
Planificación del encadenamiento.
Evita la presencia de escalones vacíos, forzados por conflictos, en el encadenamiento.
8. APLICACIONES
Hoy en día, los programas cada vez más grandes y complejos demandan mayor velocidad en el procesamiento de información, lo que implica la búsqueda de microprocesadores más rápidos y eficientes.
Las arquitecturas CISC utilizadas desde hace 15 años han permitido desarrollar un gran número de productos de software. Ello representa una considerable inversión y asegura a estas familias de procesadores un mercado creciente. Sin embargo, simultáneamente aumentan las aplicaciones en las cuales la capacidad de procesamiento que se pueda obtener del sistema es más importante que la compatibilidad con el hardware y el software anteriores, lo cual no solo es válido en los subsistemas de alta capacidad en el campo de los sistemas llamados "embedded", en los que siempre dominaron las soluciones especiales de alta capacidad de procesamiento sino también para las estaciones de trabajo ("workstations"). Esta clase de equipos se han introducido poco a poco en oficinas, en la medicina y en bancos, debido a los cada vez mas voluminosos y complejos paquetes de software que con sus crecientes requerimientos de reproducción visual, que antes se encontraban solo en el campo técnico de la investigación y desarrollo.
En este tipo de equipos, el software de aplicación, se ejecuta bajo el sistema operativo UNIX, el cual es escrito en lenguaje C, por lo que las arquitecturas RISC actuales están adaptadas y optimizadas para este lenguaje de alto nivel.
Por ello, todos los productores de estaciones de trabajo de renombre, han pasado en pocos años, de los procesadores CISC a los RISC, lo cual se refleja en el fuerte incremento anual del número de procesadores RISC, (los procesadores RISC de 32 bits han visto crecer su mercado hasta en un 150% anual). En pocos años, el RISC conquistará de 25 al 30% del mercado de los 32 bits, pese al aparentemente abrumador volumen de software basado en procesadores con el estándar CISC que se ha comercializado en todo el mundo.
La arquitectura MIPS-RISC ha encontrado, en el sector de estaciones de trabajo, la mayor aceptación. Los procesadores MIPS son fabricados y comercializados por cinco empresas productoras de semiconductores, entre las que figuran NEC y Siemens. Los procesadores de los cinco proveedores son compatibles en cuanto a las terminales, las funciones y los bits.
En el campo industrial existe un gran número de aplicaciones que ni siquiera agotan las posibilidades de los controladores CISC de 8 bits.
9. EJEMPLOS DE PROCESADORES RISC
9.1 Apple Power Mac G4 a 500 MHz
Apple Computers ha anunciado un mayor rendimiento de su línea de sistemas de sobremesa profesionales Power Mac G4, a los que incorpora procesadores RISC más rápidos que trabajan a 400, 450 y 500 MHz.
El Power Mac G4 está disponible con 1 Mb de caché, tarjeta de vídeo AGP 2x con 16 Mb de SDRAM de vídeo, disco duro de 10 Gb, unidad de DVD-ROM, puertos FireWire y USB, Ethernet 10/100 y módem interno de 56K. Los modelos a 450 y 500 MHz aumentan la capacidad del disco duro a 20 y 27 GB respectivamente e incluyen una unidad ZIP.
Los tres modelos Power Mac G4 soportan la red inalámbrica Airport de Apple, que facilita un cómodo y rápido acceso a Internet. La solución Airport de Apple consta de la tarjeta Airport, que se instala en el ordenador, y la denominada Airport Base Station, que contiene un módem de 56K y un puerto Ethernet 10BASE-T para conectarlo con una línea telefónica, un cable módem o una red de área local.
Los nuevos Power Mac G4 están disponibles con un precio que oscila entre las 289.000 pesetas (1737 euros) del modelo más barato, a las 629.900 pesetas (3785 euros) del modelo más avanzado.
Por otro lado, Apple ha anunciado dos nuevos sistemas de servidores Macintosh Server G4 a 400 y 500 MHz, existiendo un modelo a 500 MHz que incorpora el software Mac OS X Server. Todos los servidores están equipados con 1 Mb de caché backside, controladora de vídeo ATI RAGE 128 Pro AGP 2x con 16 Mb de SDRAM, disco duro de 18 Gb, lector DVD-ROM y Ethernet 10/100.
9.2 KRIPTON - 5 O K5 DE AMD
Estado Actual : Muestras comerciales.
Velocidad Prevista : 120 Mhz
Rendimiento Estimado : Entre 109 y 115 SPECint92.
Proceso de Fabricación : CMOS de tres capas de metal.
Tamaño de la Tecnología de Proceso : 0'35 micras
Ventajas Tecnológicas :
Microarquitectura superescalar de cuatro vías
Núcleo de tipo RISC desacoplado
Ejecución especulativa con reordenación de instrucciones
Desventajas Tecnológicas :
Velocidades de reloj inferiores a las inicialmente previstas
Las extensas pruebas de compatibilidad han retrasado el lanzamiento
Donde Consultar : http : // www.amd.com
9.3 PENTIUM PRO DE INTEL
Estado Actual : Inicios de producción.
Velocidad Prevista : 150 Mhz
Rendimiento Estimado : Entre 220 SPECint92; 215 SPECfp92
Proceso de Fabricación : BiCMOS.
Tamaño de la Tecnología de Proceso : 0'6 micras
Ventajas Tecnológicas :
Paquete multichip que integra una cache secundaria de 256 KB que se comunica con la CPU a la misma
Velocidad del procesador
Microarquitectura superescalar con reordenación de instrucciones
Superpipelines incluidos para permitir altas velocidades de reloj.
Desventajas Tecnológicas :
Alto precio de fabricación del paquete multichip
Microarquitectura optimizada para software de 32 bits, que tienen rendimiento pobre con código de 16 bits
Consumo de energía y disipación de calor totalmente inapropiadas para ordenadores portátiles
Donde Consultar : http : // www.intel.com
9.4 MIPS
Estado Actual : Primeras pruebas de producción
Velocidad de reloj Prevista : 200 Mhz
Rendimiento Estimado : 300 SPECint92 y 600 SPECfp92
Proceso de Fabricación : CMOS
Tamaño de la Tecnología de Proceso : 0'35 micras
Ventajas Tecnológicas :
Este chip de 64 bits tiene cinco pipelines funcionales, por lo que puede llegar a ejecutar cinco instrucciones por
Ciclo de reloj. Con dos unidades de coma flotante de precisión doble, el R10000 esta optimizado para sostener un alto rendimiento de coma flotante.
Desventajas Tecnológicas :
Para optimizar el rendimiento, la memoria cache secundaria externa tiene que fabricarse con costosa tecnología SRAM.
Donde Consultar : http : // www.mips.com
9.5 SUN MICROSYSTEMS
Estado Actual : Diseño
Velocidad de Reloj Prevista : de 250 a 300 Mhz
Rendimiento Estimado : De 350 a 420 SPECint92 y de 550 a 660 SPECfp92
Proceso de Fabricación : CMOS de cinco capas de metal.
Tamaño de la Tecnología de Proceso : 0'3 micras
Ventajas Tecnológicas :
El UltraSparc-II es una CPU de 64 bits superescalar de cuatro vías que no ha sido optimizada para tener unas altas cifras de rendimiento puro, sino para aplicaciones multimedia y de red.
Desventajas Tecnológicas :
La falta de asistencia por hardware para reordenar instrucciones crea una gran dependencia hacia la calidad de los compiladores y exige la recompilación del software anterior para disfrutar de todas las ventajas del chip UltraSparc-II.
Donde Consultar : http : // www.sun.com / sparc /
10. CONCLUSIONES
Los avances y progresos en la tecnología de semiconductores, han reducido las diferencias en las velocidades de procesamiento de los microprocesadores con las velocidades de las memorias, lo que ha repercutido en nuevas tecnologías en el desarrollo de microprocesadores.
La "era RISC" ha alcanzado a todos los fabricantes de semiconductores: AMD, Intel, MIPS, Motorola, ROSS, ...; y todos ellos son productos usados por fabricantes de ordenadores y estaciones de trabajo: Apple, DEC, HP, IBM, SUN, etc. y sus correspondientes clónicos.
El tiempo de diseño de estos productos se reduce sensiblemente, lo que disminuye su coste final, y por tanto, se incrementan sus expectativas, al poder llegar al mercado en un tiempo más adecuado y con menos posibilidades de errores. Además, son globalmente más eficaces, de menores dimensiones y más bajo consumo, ofreciendo siempre claras ventajas técnicas frente a los más avanzados CISC.
No obstante, cada usuario debe decidirse a favor o en contra de determinada arquitectura de procesador en función de la aplicación concreta que quiera realizar. Esto vale tanto para la decisión por una determinada arquitectura CISC o RISC, como para determinar si RISC puede emplearse en forma rentable para una aplicación concreta. Los costos, por su parte, también serán evaluados. Supongamos por ejemplo, que el precio de un procesador sea de 50.000 pts, éste será secundario para un usuario que diseña una estación de trabajo para venderla después a un precio de 10.000.000 pts. Su decisión se orientará exclusivamente por la potencialidad de este procesador.
RISC ofrece soluciones atractivas donde se requiere una elevada capacidad de procesamiento y se presente una orientación hacia los lenguajes de alto nivel, por lo que, los procesadores RISC han conquistado el sector de las estaciones de trabajo.
Adoptando técnicas típicas de los procesadores RISC en las nuevas versiones de procesadores CISC, se intenta encontrar nuevas rutas para el incremento de la capacidad de las familias CISC ya establecidas. También cabe esperar la aparición de otras tecnologías que compitan con CISC y RISC.
Por último, queremos destacar que las decisiones en el mercado las toman los usuarios, y aquí, el software o la aplicación concreta juega un papel mucho más importante que las diferencias entre las estructuras que son inapreciables para el usuario final.
11. EL FUTURO
Los RISC se van a lanzar a la caza del mercado de PC. Además de Power PC, van a aparecer máquinas baratas de Accorn, Digital, AMD ... Intel va a tener que sacar rápidamente el P6 (con tecnología RISC de HP) si no quiere pasar a la historia. En cualquier caso el standard PC va a acabar tarde o temprano, y su sucesor será indudablemente un RISC. Ahora bien, ¿qué RISC?, eso se verá con el tiempo, ...
Esta claro que parece ser que el futuro pertenece a los RISC y a los sistemas multiprocesador, a no ser que la física y la electrónica logren superar las barreras tecnológicas para incrementar muy por encima de las cotas actuales, las velocidades y prestaciones de una única CPU.
ANEXO
Conceptos de multiproceso
La industria informática, ha tenido siempre un objetivo primordial, repetido a lo largo de toda su cadena(fabricantes de semiconductores, fabricantes de sistemas y usuarios): la búsqueda de la velocidad. Para alcanzar este objetivo se han invertido ingentes cantidades de recursos, hasta alcanzar los límites físicos del silicio. Obviamente, la velocidad va ligada a las prestaciones, y por lo general, la primera ha sido la principal medida para decidirse por un sistema u otro. Sin embargo, por muy evidente que parezca, y dados los límites físicos de los semiconductores, las prestaciones pueden no estar forzosamente ligadas a la velocidad. Hoy es posible construir sistemas, que aún teniendo procesadores más "lentos" que otros, ofrezcan unas prestaciones significativamente superiores. Son los sistemas multiprocesador, que como su denominación indica, incorporan varios procesadores para llevar a cabo las mismas funciones.
No es un concepto nuevo, ya que los "minicomputadores" construidos por compañías como NCR, Sequent y Stratus, ya empleaban varios nodos de proceso como alternativas económicas a otros productos de otras compañías. Sin embargo, aquellos sistemas aún duplicaban recursos caros del sistema, como memoria y dispositivos de entrada / salida, y por tanto, confinaban a los sistemas multiprocesador al mundo de los sistemas de alto nivel. Ahora, y en gran medida gracias a los procesadores de arquitectura RISC, el soporte multiprocesador es una solución integrada y fácilmente disponible en estaciones de trabajo de sobremesa, que resuelve, a través de hardware VLSI, los complejos problemas de compartición de recursos (memoria compartida) de aquellas primeras máquinas. Evidentemente, estas mejoras en el hardware, para ser funcionales, requieren importantes desarrollos en el software, y de hecho, muchos sistemas operativos admiten extensiones multiproceso (Match, SCO, Solaris, System V, etc.), que proporcionan paralelismo "en bruto" (asignando múltiples tareas a múltiples procesadores) a nivel del sistema operativo.
Las aplicaciones escritas para facilitar el paralelismo en su ejecución, incrementan significativamente las prestaciones globales del sistema; esto es lo que se denomina multi-enhebrado (multithreading), que implica dividir una sola aplicación entre varios procesadores. Sin embargo, los desarrolladores de software y programadores de aplicaciones sólo han comenzado a explorar las vastas posibilidades de incremento de prestaciones que ofrecen los sistemas con capacidades reales de proceso en paralelo.
El multiproceso no es algo difícil de entender: más procesadores significa mas potencia computacional. Un conjunto de tareas puede ser completado más rápidamente si hay varias unidades de proceso ejecutándolas en paralelo. Esa es la teoría, pero otra historia es la práctica, como hacer funcionar el multiproceso, lo que requiere unos profundos conocimientos tanto del hardware como del software. Es necesario conocer ampliamente como están interconectados dichos procesadores, y la forma en que el código que se ejecuta en los mismos ha sido escrito para escribir aplicaciones y software que aproveche al máximo sus prestaciones.
Para lograrlo, es necesario modificar varias facetas del sistema operativo, la organización del código de las propias aplicaciones, así como los lenguajes de programación. Es difícil dar una definición exacta de un sistema multiprocesador, aunque podemos establecer una clasificación de los sistemas de procesadores en:
-
SISD o secuencia única de instrucciones y datos (Single Instruction, Single Data): una sola secuencia de instrucciones opera sobre una sola secuencia de datos (caso típico de los ordenadores personales).
-
SIMD o secuencia única de instrucciones y múltiple de datos (Single Instruction, Multiple Data): una sola secuencia de instrucciones opera, simultáneamente, sobre múltiples secuencias de datos (array processors).
-
MISD o múltiples secuencias de instrucciones y única de datos (Multiple Instruction, Single Data): múltiples secuencias de instrucciones operan, simultáneamente, sobre una sola secuencia de datos (sin implementaciones útiles actualmente).
-
MIMD o múltiples secuencias de instrucciones y datos (Multiple Instruction, Multiple Data): múltiples secuencias de instrucciones operan, simultáneamente, sobre múltiples secuencias de datos.
Los sistemas multiprocesadores pueden ser clasificados con mayor propiedad como sistemas MIMD. Ello implica que son máquinas con múltiples y autónomos nodos de proceso, cada uno de los cuales opera sobre su propio conjunto de datos. Todos los nodos son idénticos en funciones, por lo que cada uno puede operar en cualquier tarea o porción de la misma.
El sistema en que la memoria está conectada a los nodos de proceso establece el primer nivel de distinción entre diferentes sistemas multiprocesador:
1. Multiprocesadores de memoria distribuida
También denominados multiprocesadores vagamente acoplados (loosely coupled multiprocessors). Se caracterizan porque cada procesador sólo puede acceder a su propia memoria. Se requiere la comunicación entre los nodos de proceso para coordinar las operaciones y mover los datos. Los datos pueden ser intercambiados, pero no compartidos. Dado que los procesadores no comparten un espacio de direcciones común, no hay problemas asociados con tener múltiples copias de los datos, y por tanto los procesadores no tienen que competir entre ellos para obtener sus datos. Ya que cada nodo es un sistema completo, por si mismo (incluso sus propios dispositivos de entrada / salida si son necesarios), el único límite práctico para incrementar las prestaciones añadiendo nuevos nodos, esta dictado por la topología empleado para su interconexión. De hecho, el esquema de interconexión (anillos, matrices, cubos, ...), tiene un fuerte impacto en las prestaciones de estos sistemas. Además de la complejidad de las interconexiones, una de las principales desventajas de estos sistemas, como es evidente, es la duplicación de recursos caros como memoria, dispositivos de entrada / salida, que además están desocupados en gran parte del tiempo.
2. Multiprocesadores de memoria compartida
También llamados multiprocesadores estrechamente acoplados (tightly coupled multiprocessors). Son sistemas con múltiples procesadores que comparten un único espacio de direcciones de memoria. Cualquier procesador puede acceder a los mismos datos, al igual que puede acceder a ellos cualquier dispositivo de entrada / salida. El sistema de interconexión más empleado para estos casos, es el de bus compartido (shared-bus). Tener muchos procesadores en un único bus tiene el inconveniente de limitar las prestaciones del sistema a medida que se añaden nuevos procesadores. La razón es la saturación del bus, es decir, su sobre utilización; en un sistema de bus compartido, se deriva por la contienda entre los diferentes dispositivos y procesadores para obtener el control del bus, para obtener su utilización.
Es evidente, que los sistemas actuales tienden al uso de arquitecturas de memoria compartida, fundamentalmente por razones de costes, a pesar del problema de la contienda por el bus. Los tres fuentes fundamentalmente responsables de dicha disputa son la memoria (cada CPU debe usar el bus para acceder a la memoria principal), la comunicación (el bus es usado por los "bus masters" para la comunicación y coordinación), y la latencia de la memoria (el subsistema de memoria mantiene al bus durante las transferencias de datos, y en función de la velocidad a la que la memoria puede responder a las peticiones, puede llegar a ser un factor muy significativo).
Los sistemas de memoria caché y el multiproceso
Los sistemas de memoria multinivel (caché) son un esfuerzo para evitar el número de peticiones realizadas por cada CPU al bus. Los caches son pequeñas y rápidas (y por tanto caras) memorias, que hacen de tampón (buffer) entre la CPU y la memoria externa, para mantener los datos y/o instrucciones. Se basan en el principio de la "localidad", lo que significa que, dada la fundamental naturaleza secuencial de los programas, los siguientes datos o instrucciones requeridas, estarán localizadas inmediatamente a continuación de las actuales.
Los datos contenidos en la memoria caché se organizan en bloques denominados líneas. Las líneas son cargadas en el caché como copias exactas de los datos situados en la memoria externa. Para referenciar a los datos de la memoria caché, se emplean marcas (tags) que identifican a cada línea. Las marcas o tags emplean una porción de la dirección física de los datos, para compararla con la dirección física solicitada por la CPU. Cuando existe una coincidencia exacta de la dirección y de otros cualificadores (estado, privilegio, contexto, etc.), se dice que ha tenido lugar un acierto (hit) de caché; en caso contrario, tiene lugar un fallo (miss) del caché, y en ese caso, los datos han de ser recuperados desde la memoria.
El empleo de memoria caché se ha popularizado, como medida para acelerar el tiempo de acceso a la memoria principal, incluso en los sistemas monoprocesador, evitando así, según se incrementa la velocidad de los propios procesadores, aumentar la velocidad de dicha memoria, y por tanto encarecer el sistema. La forma en que la memoria es actualizada por los caches locales puede tener un gran impacto en las prestaciones de un sistema multiprocesador.
Básicamente hay dos métodos:
1. Escritura continua (write-through).
Requiere que todas las escrituras realizadas en el caché actualicen asimismo los datos de la memoria principal. De esta forma, la memoria principal siempre tiene la última copia de los datos, y por tanto no hay nunca ninguna incoherencia con el caché. El inconveniente es que se producen frecuentes accesos a memoria, especialmente superfluos cuando el software está modificando las mismas secciones de datos repetidamente (por ejemplo ejecutando bucles).
2. Copia posterior (copy-back).
Es un sistema mucho más eficiente, aunque también más complejo de implementar. En este caso, la CPU puede modificar la línea de caché sin necesidad de actualizar inmediatamente la memoria principal. Los datos sólo son copiados a la memoria principal cuando la línea de caché va a ser reemplazada con una nueva. Ello no solo minimiza el tráfico del bus, de vital importancia para el resto de los procesadores, sino que también libera al procesador de la tarea de escribir en la memoria principal. Sin embargo, este sistema, en una arquitectura de bus compartido, implica un nuevo nivel de dificultad, denominado coherencia o consistencia (coherency o consistency); dado que cada caché puede tener una copia de los datos existentes en la memoria principal, el desafío es asegurar que los datos permanecen iguales entre todos los caches.
Hay dos métodos para mantener cada línea de caché idéntica a las demás:
a.) Escritura radiada (write-broadcast)
Que requiere que la CPU que modifica los datos compartidos actualice los otros caches, para lo cual escribe en el bus la dirección de los datos, y los datos mismos, de modo que todos los dispositivos interesados (otras CPU's) los capturen. Esto asegura que cada línea de caché en el sistema es una copia exacta de las demás.
b.) Escritura invalidada (write-invalidate)
Impide a una CPU modificar los datos compartidos en su caché hasta que otros caches han invalidado sus copias. En cuanto otros caches invalidan sus líneas, el caché modificado tiene la única copia; de este modo, se garantiza que un sólo caché escribe una línea compartida en un momento dado. Tiene la ventaja de conservar el ancho de banda del bus ya que los datos modificados no tienen que ser enviados a otros caches.
Ambos sistemas requieren que los caches sean capaces de identificar peticiones en el bus que afecten a sus datos, lo que se realiza con una técnica conocida como "sondeo del bus" (bus snooping). Cada caché compara las direcciones de las peticiones en el bus compartido con los datos en su propio cache, usando las marcas (tags).
Este sistema requiere un acceso concurrente a las marcas (tags) del caché por parte del bus del sistema y del bus del procesador. Sin dicho acceso concurrente, el procesador no podría acceder al caché durante las operaciones de sondeo del bus (que tienen que tener prioridad de acceso a las marcas, para poder mantener la coherencia del caché). El resultado son frecuentes atascos del procesador y por lo tanto, bajo rendimiento.
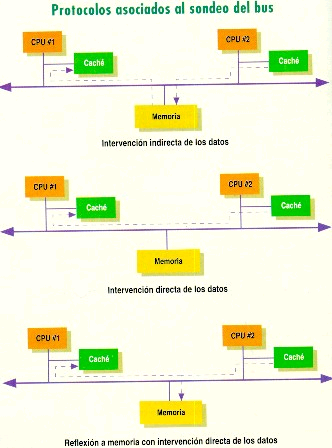
A su vez, hay varios protocolos asociados con el sondeo del bus para el movimiento de los datos y los mensajes entre los caches:
1. Intervención indirecta de los datos (indirect data intervention).
Es el método más simple de intercambio de datos entre procesadores, aunque también el menos eficiente. La 1ª CPU hace una petición de datos, que es sondeada por la 2ª; tiene lugar un acierto de sondeo (snoop hit) si dichos datos están en el caché de la 2ª CPU, entonces esta obtiene el control del bus e indica a la 1ª que lo reintente más tarde. La 2ª CPU escribe los datos de su caché a la memoria, y la 1ª CPU obtiene el control del bus de nuevo, reiniciando la petición. Los datos son ahora suministrados por la memoria.
2. Intervención directa de los datos (direct data intervention).
Los datos son suministrados directamente por la 2ª CPU a la 1ª. Este mecanismo es aplicable fundamentalmente a los sistemas con sistemas de cache de copia posterior (copy-back). Aunque pueden evitar muchos ciclos comparados con la intervención indirecta, la memoria principal permanece inconsistente con el caché, y debe de ser actualizada cuando la línea de caché es vaciada.
3. Reflexión a memoria con intervención directa (memory reflection).
La memoria captura los datos que han sido depositados en el bus, mientras son enviados a la CPU solicitante. Si la línea de caché no ha sido modificada antes de que tenga lugar la última transacción de intervención de datos, no es necesario escribir a la memoria, con lo que se conserva el ancho de banda. Esta actualización del cache solicitante y la memoria puede tener lugar en un mismo y único ciclo de reloj.
2
Arquitectura de Computadores
Descargar
| Enviado por: | El remitente no desea revelar su nombre |
| Idioma: | castellano |
| País: | España |
Todos los derechos reservados.